今天分享的是AIGC系列深度研究报告:《AIGC专题报告:从文生图到文生视频技术框架与商业化》。
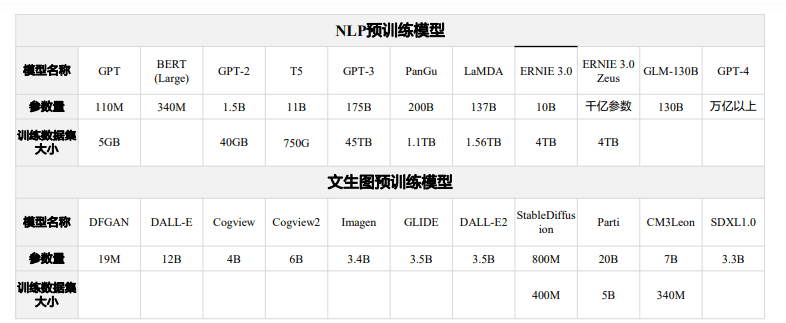
底层模型技术框架梳理:文生图和文生视频的底层技术框架较为相似,主要包括GAN、自回归和扩散模型三大路径,其中扩散模型(Diffusion model)为当前主流生成模型,多个指标对比下综合占优,能在 较为可控的算力成本和较快的速度下生成具备多样性、高质量的图像:
图像质量:扩散模型>自回归模型>GAN模型。FID值(Frchet Inception Distance score)是用于评估模 型生成的图像质量的指标,是用来计算真实图像与生成图像的特征向量间距离的一种度量。FID值越小,可以认为图像质量在一定程度上越优。从不同模型的FID得分来看,扩散模型平 均数较小,反应图像质量较高。
参数量:自回归模型>扩散模型>GAN模型。GAN的参数量一般在千万级别,整体较为轻巧,扩散模型的参数量在十亿级别,自回归模型在十亿到百亿级不等。
生成速度(由快到慢):GAN模型>扩散模型>自回归模型。生成速度与参数量级为负相关关系。
训练成本:自回归>扩散模型>GAN模型。由于参数量级较小,GAN 模型训练成本小且开源模型多,仍具备一定优势。而自回归模型参数量级较大,整体训练成本更高。在单张A100GPU下,120亿参数的DALL-E需要18万小时,200亿参数的 Parti 更是需要超过100万小时,扩散模型参数量在十亿级别,整体训练成本较为适中。
(报告出品方:国海)
报告共计:73页
海量/完整电子版/报告下载方式:公众号《人工智能学派》



文生图:基于文本生成图像,Stable Diffusion开源后迎来快速发展
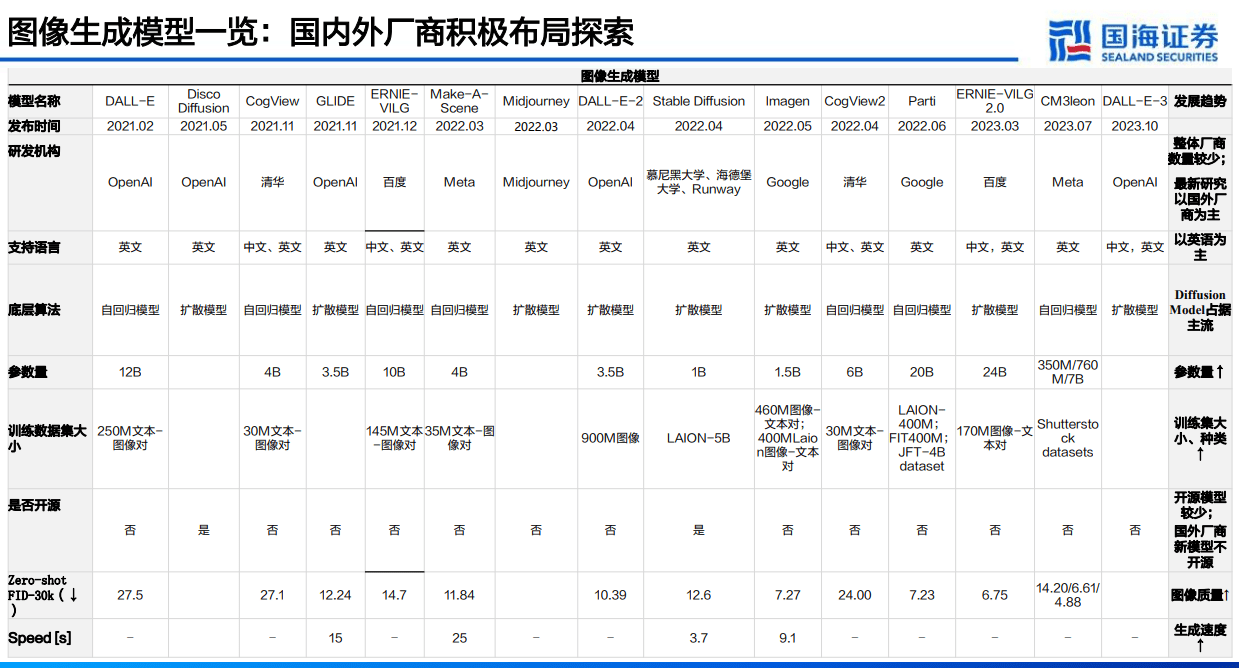
文生图(Text-to mage) 是基于文本通过生成A生成图像的模式。近3年时间,文生图的技术已实现大的进步,海外的Stable DifusionMidiournev已经能够提供较高质量的图像,国内的万兴科技的万兴爱画、百度的文心·一格也投入商用。文本生成图像的底层模型可以分为GAN、扩散模型、自回归模型三类。目前行业内的明星模型主要基于扩散模型。
文生视频:与文生图底层技术一致,自回归和扩散模型为主流
文生视频(Text-to-Video) 是基于文本通过生成式AI生成视频的模式。随着文生图技术的精进与成熟,对于文生视频的技术的发展和关注渐演变及增加,近3年时间,以Runway为代表的文生视频公司在不断涌现,互联网行业的巨头,比如谷歌、Meta微软,同样投入人员和精力参与其中,国内目前文生视频技术还在初期发展阶段,目前魔搭社区(Model Scope) 里的开源模型ZeroScope表现亮眼。文本生成视频模型的发展经历三个阶段: 图像拼接生成阶段、GAN/VAE/Flow-Based生成阶段、自回归和扩散模型阶段。




GAN:通过生成器和判别器对抗训练提升图像生成能力
GANs(GAN, Generative Adversarial Networks),生成对抗网络是扩散模型前的主流图像生成模型,通过生成器和判别器进行对抗训练来 提升模型的图像生成能力和图像鉴别能力,使得生成式网络的数据趋近真实数据,从而图像趋近真实图像。
GAN常见的模型结构
单级生成网络:代表有DF-GAN等。只使用一个生成器、一个鉴别器、一个预训练过的文本编码器,使用一系列包含仿射变换的UPBlock块学习文本与图像之间 的映射关系,由文本生成图像特征。
堆叠结构:多阶段生成网络,代表有stackGAN++、GoGAN等。GAN 对于高分辨率图像生成一直存在许多问题,层级结构的 GAN 通过逐层次,分阶段生成, 一步步提生图像的分辨率。在每个分支上,生成器捕获该尺度的图像分布,鉴别器分辨来自该尺度样本的真假,生成器G1接收上一阶段的生成图像不断对图像进行 细化并提升分辨率,并且以交替方式对生成器和鉴别器进行训练。多阶段GAN相比二阶段表现出更稳定的训练行为。(一般来说,GAN的训练是不稳定的,会发 生模式倒塌的现象mode collapse,即生成器结果为真但多样性不足)


自回归模型:采用Transformer结构中的自注意力机制
自回归模型( Auto-regressive Model)采用T自回归图像生成。coder和Decoder两大部分,能够模拟像素和高级ranstormer警水主要台属性(纹理、语义和比例)之间的空间关系,利用多头自注意力机制进行编码和解码。采用该架构模型的文生图通常将文本和图像分别转化成tokens序列,然后利用生成式的Transformer架构从文本序列藏后使用图像生成技术中科测图像序列GAN等对代序列进行解码,得到最终生成图像。
经典自回归模型
结合ViT-VQGAN:谷歌Parti将ViT-VQGAN作为图像标记器将图像编码 为离散标记序列(使用Transformer GPT-2作为编码生成工具),它将文 本到图像的生成视为序列到序列的建模问题,图像标记序列是目标输出,并 利用其将此类图像标记序列重建为高质量、视觉多样化图像。首先将一组图像转换为一系列代码条目,类似于拼图,然后将给定的文本提示转换为这些 代码条目并「拼成」一个新图像。
结合VQ-VAE(矢量量化变分自动编码器):清华的 CogView 与百度的 ERNIE-ViLG 均使用 VQ-VAE + Transformer 的架构设计。先将文本部 分转换成token,然后将图像部分通过一个离散化的AE(Auto-Encoder)转 换为token,将文本token和图像token拼接到一起,之后输入到GPT模型中 学习生成图像。

自回归模型:生成视频相比GAN更加连贯和自然
与GANs相比,自回归模型具有明确的密度建模和稳定的训练优势,自回归模型可以通过帧与帧之间的联系,生成更为连贯且自然视频。但是自回归模型受制于计算资源、训练所需的数据、时间,模型本身参数数量通常比扩散模型大,对于计算资源要求及数据集的要求往往高于其他模型随着扩散模型的火热,自回归模型的热潮逐渐降低,基于文本生成图像的文本生成视频的热潮渐起。

C L I P:实现文本和图像特征提取和映射,训练效果依赖大规模数据集
CLIP(Contrastive Language-image Pre-training)是基于对比学习的文本-图像跨模态预训练模型,由文本编码器(Text Encoder)和 图像编码器(Image Encoder)组成,编码器分别对文本和图像进行特征提取,将文本和图像映射到同一表示空间,通过文本-图像对的相似度和 差异度计算来训练模型,从标签文本创建数据集分类器,从而能够根据给定的文本生成符合描述的图像。
预训练模型:预先在数据量庞大的代表性数据集上训练模型,当迁移到自定义的数据中通过权重和偏差调优后,使模型达到需要的性能预训练模型能够节省从零开始的高昂时间成本和计算成本,降低模型对标注数据数量的要求,能够处理一些难以获得大量标注数据的场景。
CLIP的特点
• 优点:由于CLIP完成了基于多模态的对比学习和预训练,在过程中已经将文本特征和图像特征进行对齐,该模型无需事先标注数据,减少了标注数据的工作量及 对应成本,能够在零样本图像文本分类任务中高质量运行。
• 缺点:
1)CLIP在包含时间序列数据和需要推理计算的任务中由于模型本身的局限性,生成图像的效果不佳。
2)CLIP的训练效果依赖大规模的文本-图像对数 据集,对训练资源的消耗比较大,CLIP是由OpenAI团队通过4亿对图像-文本对训练后提出的。


平均来看自回归模型成本最高,生成视频成本远高于生成图片

但在实际模型应用中,成本不仅取决于参数量大小,也取决于训练时间和用户规模。 前期训练阶段,若对模型训练时间没有要求,可以通过延长训练时间降低GPU成 本;若对训练时间要求较短,则需要布局更多芯片提高训练速度。
上线阶段,如果用户体量很大,比如OpenAI和Midjourney规模用户体量,线上 运营推理的成本可能占到整体成本80-90%,训练阶段成本只占10-20%。
文生视频的成本可能为文生图24倍以上
人眼看到的视频是透过一连串的静态影像连续快速播放的结果,由于每一 张静态画面的差异很小,因此连续快速播放时,一张张快速闪过的静态画 面在人眼视网膜上产生“视觉暂留”现象,原本静态的图像仿佛连贯运动 了起来。
通常来说,人看到视频是连贯的需要帧率为每秒24帧以上,电影放映的标 准也是每秒24帧以上。如果文生图一次性消耗的算力是一个单元,文生视 频一次产生消耗约24个单元。实际应用可能是小于24,但不会小特别多, 并且很有可能大于24,因为文生视频不仅仅是简单的把图片快速播放起来, 还需要内容具备多维性和多元性。目前主流文生视频模型生成视频长度仅 支持2秒~4秒。

文生图领域整体创业门槛低于大语言模型,商业模式仍存疑问
模型层看:图像生成领域已有生成质量较高的开源预训练模型Stable Diffusion,且SD具有较为丰富 的开发者生态,有许多插件供选择。创业公司可基于Stable Diffusion基础版本进行进一步调优和个 性化数据训练, Stable Diffusion最新发布的开源模型SDXL1.0采用更大参数量级进一步提升了生成 图像质量。例如初创公司界 AI 便是国内最早基于 SD 模型推出 AI 绘画具的平台之。
成本端看:从主流模型参数规模看,文生图参数量级多在1-10B之间,而通用大模型入门级门槛达到 了70B,文生图整体参数量级较小,成本远低于通用大模型。通过调研文生图初创公司,实际小团队 利用开源模型,初期在用户不到1万情况下甚至无需购买A100,通过购买RTX30\40系列、IBS3060 (5000~1w/张)也可以启动。用户1万左右的文生图公司,生成单张图片的成本在0.1元左右。

文生图推理算力需求测算
推理思路介绍:
显存容量经验公式:10亿参数量对应3.7GB显 存容量需求。假设每个参数为FP32格式,假 设每个参数为FP32格式即4个字节(文生图一 般不需要做精度缩减),则原始理论需求为 10*4*10^8/1024/1024/1024=3.7GB。
计算单次推理所需显卡数量: A100显存容量为40GB/80GB,以40GB为例,A100可拓展的GPU是7个,40/7=5.7>所需显存需求3.7,因此单次推理所需A100显卡数量为1/7。
根据日活数量推算并发推理需求最大设计容量以Google的日活与单秒所需要处理的并发需求作为基础,考虑到文生图所需要的耗时较长要让用户具备一定用户体验,并发容量的设计次数应该是10倍于谷歌搜索。
计算并发推理所需要推理次数: 假设同一时间可承受的最高推理请求次数,以及单次推理时模型合并的推理需求数量,得到在并发推理时所需要的推理次数。
计算并发推理所需要显卡数量: 单次推理所需显卡数量与并发推理时最高所需要的推理次数相乘即为所需显卡的数量。






Midjourney:基于扩散模型的文生图龙头,用户规模超干万
Midioumey 是A基于文字生成国像的工具,由David Hoz创立于2021年。Midioumney以拥有充流量的Discord为载体,实现低成本获客和低成本营销,在此中拥有超过1000万人的社区,不到一年完成了1亿美元的营收,但至今未融资。Micdiumner的道型是源的,参考CLP及D/sn开源模型的基上抓公开教进行训练。
应用优势
• 迭代速度快于同行,图像质量提高迅速。Midjourney从V1推出到V5.2版本仅仅一年半的时间,图像质量显著提高,并且积累了数量可观的用户群体。
• 依托Discord社群,降低用户使用门槛。Midjourney以拥有充沛流量的Discord为载体,实现低成本获客和低成本营销。
• 拥有较高的图像质量和独特的艺术风格。Midjourney能够生成不同的风格,用户可以在提示词中选择默认艺术风格的应用强度, Midjourney尤其擅长环境效果, 特别是幻想和科幻场景,生成图片具有较强商业价值和艺术特色。
• 基于庞大用户规模和数据反哺模型训练,形成飞轮效应。通过庞大的用户量及用户数据,Midjourney积累的数据集具有独家性,可以进一步进行针对性训练。


报告共计:73页
精选报告来源:人工智能学派
本文作者可以追加内容哦 !

