很多人好奇,GPT大模型是否已经应用于指数增强基金中,怎么用的,效果又如何?今天就和大家说说。
GPT大模型的优势有哪些?
大模型一般指包含超大规模参数量(通常在10亿以上)的神经网络模型。大模型具有以下特征:
1. 参数量巨大:大模型包含数十亿甚至上百亿的参数,大规模的参数为大模型提供了强大的学习能力和表达能力;
2. 多任务学习:大模型通常会同时学习多种NLP(自然语言处理)任务,例如机器翻译、文本摘要等,所以大模型具有较广泛的语言理解能力;
3. 丰富的数据:巨大的参数量要求有更大规模的数据,才能训练出泛化能力较好的大模型。例如我们熟知的GPT-3模型使用的数据集包括:CC数据集(4千亿词)、WebText2(190亿词)、BookCorpus(670亿词)、维基百科(30亿词);
4.强大的计算资源:大模型训练需要非常强大的计算资源,例如openAI训练GPT-3时使用了一千多张A100显卡,完整训练一轮也需要30天的时间。
大模型如何应用到指数基金交易中?
大模型主要分为四种类型:大语言模型、计算机视觉、音频、多模态模型。GPT模型归属于大语言模型,其在文本生成、对话交互等领域都有突出的表现。我们在实际投资中其实也可以从大模型中取取经,从而优化我们的投资模型。
一方面,以GPT为代表的大语言模型基本架构几乎都是transformer模型,其核心多头注意力机制能够学习上下文和当前位置词语的关联关系,这也是GPT模型拥有强大“联想”能力的原因之一。我们在投资模型的构建中,也可以纳入该模型,从而将不同数据指标之间的关联关系考虑进来,充分利用多维度信息优化模型。
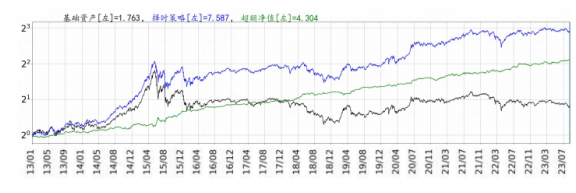
例如,我们的智能算法团队最近发布了一个AI多行业轮动的模型,其基本框架为decoder-only transformer,长期来看取得了不错的超额收益(历史回测结果)。
图:Transformer行业轮动模型表现
再例如,我们也会使用引入注意力机制的循环神经网络(LSTM/GRU等)来进行高频量价因子挖掘,同样取得了较好的效果。
另一方面,另类数据(例如文本数据、舆情数据)是指数增强模型一个重要的alpha来源,过往受限于繁琐的数据处理流程,我们很难充分利用这些文本数据。但是大模型拥有强大的文本处理分析能力,我们通过大模型能够精准地分析每段文本的语义,提取增量信息。
例如,我们可以使用BERT模型来对分析师发布的研报文本数据进行分析,识别分析师的情感偏向。我们将大模型的输出信号作为指数增强模型的输入特征之一,从而丰富指数增强模型的alpha来源,增强产品的收益表现。
写在最后
今天的讲解,可能有些专业部分大家看不太懂,但是大模型已经快马加鞭的应用到基金交易当中,普通投资者与机构的差距或许正在逐渐拉大。寻找一只适合自己的指数基金,享受大模型时代红利,对大家来说或许是更好的选择。
我是毛甜,一个致力于保护散户的量化基金经理,我的能力圈是量化投资领域,目前主要管理了宽基指增和食品饮料、医药、化工等细分赛道的行业指数基金。我会每周分享投资观点,欢迎大家留言提问!关注我,我会经常和大家交流量化投资那些事儿,下期再见。
风险提示:本材料中包含的内容仅供参考,不作为基金宣传推介材料,不构成任何投资建议或承诺。不同时期,华泰证券(上海)资产管理有限公司可能会发出与本材料所载观点、意见、评估及预测不一致的其他材料。请投资者理性判断并独立决策,在投资金融产品或金融服务过程中应当注意核对自己的风险识别和风险承受能力,选择与自己风险识别能力和风险承受能力相匹配的金融产品或金融服务,并独立承担投资风险。投资有风险,入市需谨慎。
$华泰紫金沪深300指数增强发起A(OTCFUND|016867)$$华泰紫金沪深300指数增强发起C(OTCFUND|016868)$$华泰紫金中证500指数增强发起A(OTCFUND|016865)$$华泰紫金中证500指数增强发起C(OTCFUND|016866)$$华泰紫金中证1000指数增强发起A(OTCFUND|018062)$$华泰紫金中证1000指数增强发起C(OTCFUND|018063)$
本文作者可以追加内容哦 !

