概要
在预测股票回报时,量化投资的管理人往往习惯用股票自身的特征(比如基本面、量价)作为模型输入数据。随着量化投资在过去几年飞速发展和竞争加剧,直接运用股票特征的预测信息,会更迅速的体现在股票价格里。磐松资产的投资过程聚焦长周期的股票回报预测,其中一大特点就是善于运用间接信息。我们认为来源于相关股票的数据相较于股票自身的数据有信息增量,但同时又不容易被市场参与者发掘。
我们对于直接信息和间接信息的看法可以用图1来概括:
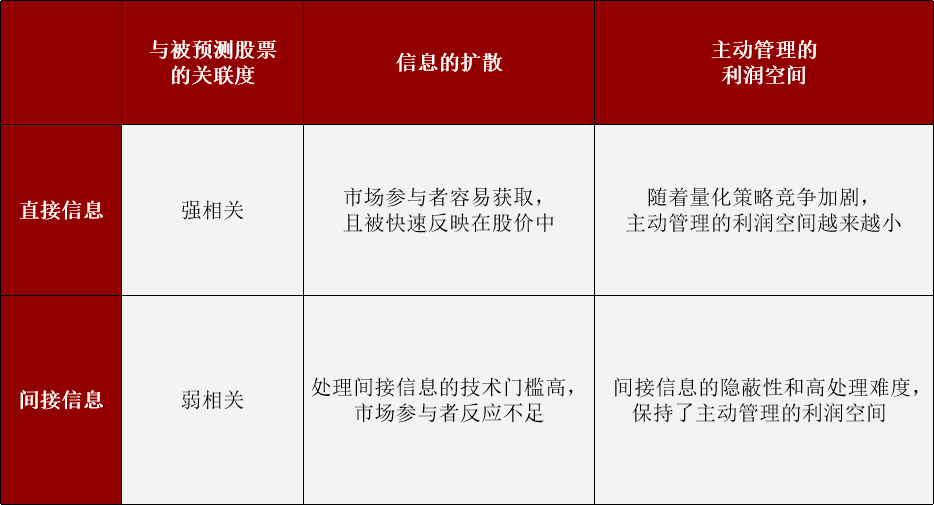
为了准确地捕捉股票间的关联度,磐松开发了极具特色且行业领先的关联模型。成熟的关联模型是我们的股票回报预测模型的关键输入,也是我们的竞争优势之一。
模型简介
不同股票之间存在复杂多样的关联度,比如在同行业中,龙头股票领涨会导致其它股票在未来跟涨;在不同行业之间,若两家公司是供应链上的合作伙伴,那么一家公司的事件可能会影响另一家公司的股价等等。
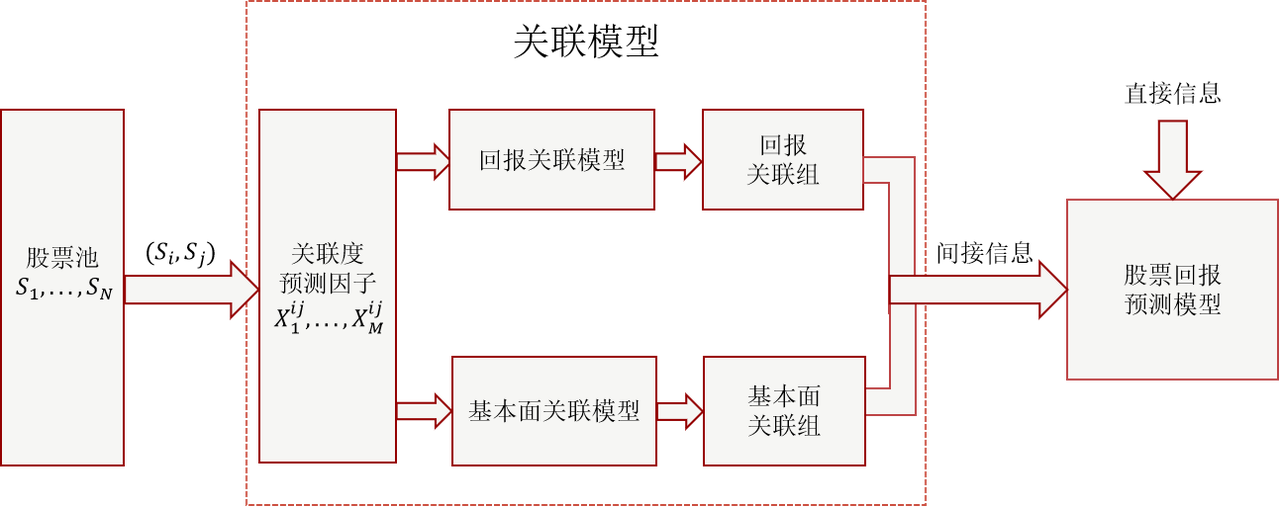
磐松的关联模型具体包括了:
1. 回报关联模型,该模型预测两只股票之间未来的股票回报相关性。高股票回报相关性往往意味着有同一批市场参与者在同时关注和交易这两只股票。
2. 基本面关联模型,该模型预测两只股票之间未来的基本面变化相关性。高基本面变化相关性往往意味着两家公司业务相似或是二者存在产业链上下游等关系。
关联模型描述的是每一对股票之间的关系,我们根据历史数据,为每一对股票构建关联度预测因子。关联模型中有几十种不同的信号,分别用来预测这两只股票未来的回报相关性和基本面变化相关性。这些信号大多数是基于经济学逻辑或者基本面关系的,比如产业链上下游;有少部分是基于统计规律的,比如股票间的历史收益相关性。我们认为,关联模型应该给基于统计规律的信号更低的权重,因为这些信号作为样本内拟合的结果,噪音较大,而对公司基本面的变化反应更慢,不能够较为准确地反映未来关联度。
下面列举一些关联模型中的预测因子,有些可能已经被我们淘汰:
1. 是否在同一个行业
2. 地理位置的靠近程度(比如是否在同个省)
3. 股票回报、周转率、波动率的相关性
4. 财报数据、分析师预测的相关性
5. 主营业务、收入来源的相关性
6. 各种风格贝塔(市场、价值、动量、大小盘等)的相似度
7. 上下游产业链关系
8. 公司间竞争、合作关系
9. 专利相似度
10. 股东构成相似度
我们综合所有的关联模型预测信号,生成关联模型的预测值。对于每一只股票,按照预测值排序,选取预测值最大的几十只股票生成每只股票自己的回报关联组和基本面关联组。
模型举例
我们选取某一天作为时间节点,使用关联模型预测两只股票之间未来的股票回报相关性和基本面变化相关性。我们分别选取回报相关性与基本面变化相关性最大的前三十只股票作为关联组,贵州茅台最终的关联组结果如图2所示:
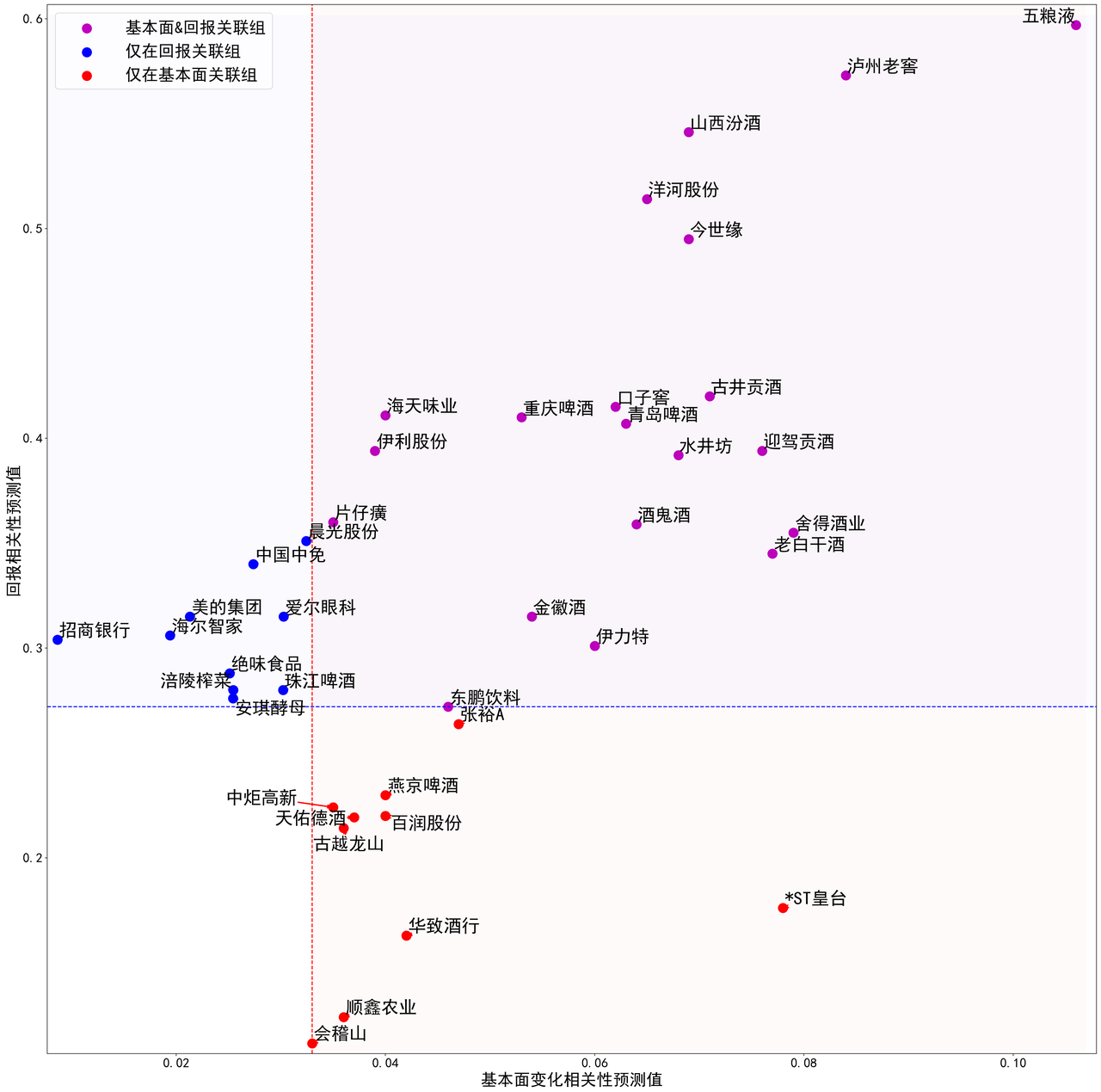
图2中纵坐标为回报相关性预测值,横坐标为基本面变化相关性预测值。图中对股票按其所处关联组类型进行了分类:红色虚线以右为基本面关联组;蓝色虚线以上为回报关联组;二者重叠的紫色部分表示股票同时存在于基本面关联组和回报关联组中,以下将其简称为基本面&回报关联组。
基本面&回报关联组中的企业分布较为符合直觉。酒企共占基本面&回报关联组企业数量的80%,它们与茅台业务相似,基本面自然高度相关。此外,市场参与者对酿酒行业进行投资时往往同时看涨或看跌茅台与五粮液、沪洲老窖等其他知名酒企,因此在股票回报上它们往往与茅台具有高度的相关性。然而并不是所有酒企的股票回报都与茅台显著相关,我们以燕京啤酒和*ST皇台为例:尽管和其他酒企的主营业务相似,但由于盈利、运营和扩张能力上燕京啤酒处于劣势,青睐绩优股的投资者往往不会选择它作为投资标的;*ST皇台虽然在20世纪90年代曾有着“南茅台,北皇台”的辉煌历史,如今却被多次实施退市风险警示,因此虽然*ST皇台与茅台基本面变化相关性极高,但回报相关性较低,主要原因是燕京啤酒和*ST皇台作为小盘、低质量股票,在风格因子上的暴露与大盘、高质量股票茅台相反。
在基本面关联组中,25%的企业为非酒企。因为关联模型的预测因子组合覆盖全面,能从间接信息中挖掘出股票间的潜在关系。这些企业与贵州茅台的基本面变化相关性均有迹可循:海天味业、中炬高新等调味品制造商与茅台有相同的上游原料种植产业;东鹏饮料、伊利股份与茅台同属食品饮料赛道;而片仔癀与茅台基本面的相关性也能从“喝酒伤肝,吃药护肝”的消费逻辑及它们都具有的收藏品属性等多个角度进行解读。
在茅台的回报关联组中还有许多股票的行业与酿酒无关,该现象反直觉却暗含信息。事实上,这些股票与贵州茅台一样,都是行业中的龙头企业,且因高估值、业绩优良而被赋予了较高的投资价值,比如中国中免就号称“免税茅台”,美的集团常被股民称为“家电茅台”,晨光股份也被称为“文具茅台”。A股“喝酒吃药”的特殊行情也使得片仔癀与茅台有较高的股票回报相关性。关联模型显示出这些股票与茅台被同一批市场参与者同时关注、交易着,这些关注酿酒行业、偏好大盘蓝筹或绩优白马股的市场参与者们,主要由专业投资机构组成,当大量的机构扎堆在少数的白马股中就会形成抱团现象。据华夏时报统计,当白马股在2022年集体回撤时,市值蒸发前10名榜单上,茅台位列第二。其回报关联组中的不少股票也榜上有名:招商银行紧跟茅台位列第三,五粮液位列第五,美的集团位列第八。这些“抱团股”同涨同跌的特征会直接反应在股票回报相关性上,从而被回报关联模型敏锐地捕捉。
回报模型
磐松的回报模型广泛地使用了关联组,我们能够利用关联组中的股票特征,构建出一系列基于间接信息的因子。因为每只股票都有属于自己的关联组,所以关联组最主要的使用场景是个股模型,但是在行业模型中也有应用。作为背景,在磐松的研究框架下,个股模型预测的是个股相对行业的超额收益,行业模型预测的是行业相对市场的超额收益。
关联组在不同类型的因子中有不同的应用方法,比如:
1. 间接动量因子组中,我们利用关联组来衡量相关股票的表现
2. 质量因子组中,我们利用关联组来作为公司基本面质量的对比基准
我们认为,关联模型越准确,所有用到关联组的回报模型信号也会在样本外表现越好。有些数据在回报预测中的直接用处不大,很多量化管理人往往会忽视这样的数据。但是如果这些数据能有效地帮助我们识别股票之间的关联,改进关联组,那么就可以间接地帮助我们改进回报预测。和直接添加或修改股票回报模型的预测信号相比,通过改进关联模型带来的回报模型的改进效果,根据我们的经验是非常可观的。尤其是后者没有对股票的未来回报进行数据挖掘,回报模型本身也没有增加任何额外的自由度或参数;相反,回报模型的结构完全没变,仅是因为关联组作为模型的输入之一,数据质量变好而得到预测效果的提升。这样的模型改进,符合磐松强调每一个因子都必须有强投资逻辑的研究思路。
总结
综上所述,作为磐松投资过程的特色之一,关联模型能够全面、准确地从多角度评估股票之间的关联度,为预测股票回报提供了更好的数据支持。关联模型是我们的竞争优势之一,而且出于以下两点原因,磐松会在未来保持这个竞争优势:
1. 关联模型的研发成本高,竞争对手难以轻易模仿。关联模型的输入数据非常广泛,处理起来既多变又复杂;关联模型的问题规模较大,因为需要预测所有的股票对,关联信号也都是在股票对层面的。我们在2017到2021历时4年开发了初代版本,这个先发优势是我们持续领先的基础。
2. 我们在关联模型上有持续不断的研发投入。很多我们的竞争对手也逐渐开始研究关联模型,但是磐松会在成熟的研究框架内,更高效地迭代、改进关联模型。2021年以来,我们做的改进项目包括:加入新的数据集,用更好的统计方法填充缺失数据等。
有些数据不能直接预测股票未来的回报,很多量化管理人因为没有足够成熟的关联模型,就会认为这个数据对于投资过程没有帮助。但这还不是最糟糕的,量化策略的研究员可能会过分挖掘数据,直到他们找到虚假的、样本内的预测信号,而这样的预测信号在样本外是不可靠的。与此相反,磐松的研究过程会通过关联模型,结构化地从这类数据中获取信息,得到更贴切的关联组,最终间接改进回报预测模型。这样的研究方法在长周期股票回报预测中是非常成功的。未来磐松将继续致力于不断改进关联模型,引入新信息,开拓新信号,确保我们在这一领域的竞争优势。
*重要声明
风险提示:本内容刊登于此仅出于传递信息之目的,不构成投资建议,其内容是基于我们认为可靠且已公开的信息,但我们对这些信息的准确性及完整性不做任何保证,也不保证文中观点或陈述不会发生任何变更;在不同时期,可发出与这些信息所载资料、意见及推测不一致的内容。
版权提示:如转载使用,请注明来源及作者、文内保留标题原题以及文章内容完整性,并自负版权等法律责任。
往期推荐:
本文作者可以追加内容哦 !

