
AI不是零和游戏!
GPT-4o星光熠熠,Gemini并未哭泣。
OpenAI抢鲜发布GPT-4o的第二天,谷歌就在2024年I/O大会上满怀豪情地“反击”。
谷歌CEO桑达尔·皮查伊(Sundar Pichai)在长达110分钟的演讲中,一口气发布几十款Google和AI结合的新产品,对阵OpenAI。
这次发布的谷歌“全家桶”包括:
支持200万token长文本的Gemini 1.5 Flash;
“谷歌版Sora”技术Veo;
对标GPT-4o的Project Astra;
最强开源模型Gemma 2;
支持生成式搜索的AI Overviews;
第六代TPU等硬件。
谈到OpenAI竞争,皮查伊表示,谷歌全面进入Gemini时代,更不能被牵着鼻子走。他进一步强调,这并不是一个零和游戏。
但是,市场对这次发布会的反应,没有预想中热烈。截至发稿,谷歌母公司Alphabet(GOOG)股价仅上涨0.60%。
全新Gemini大模型产品矩阵
根据谷歌统计,这场110分钟演讲中,皮查伊提及AI的次数高达“121次”。
“我们完全处于Gemini时代。”大会开场,谷歌CEO皮查伊一语双关。如果说历次I/O大会频率最高的词是AI,今年毫无意外地变成了Gemini。
随着演讲开始,谷歌首先发布Gemini 1.5 Pro。

Gemini Advanced上线三个月之后,注册用户已超过100万;新版Gemini 1.5 Pro面向全球用户正式推送,最高支持一百万Token上下文识别(通行计算方法中约等于 50万中文字符)。
Gemini 1.5 Pro最大支持上下文窗口从100万Tokens升级到200万,并且能同时支持35种语言。而且升级后的Gemini,不仅能分析比以前更长的文档、代码库、视频和音频录音,还能处理更加复杂和细微的指示,比如指定产品级行为的指示,如角色、格式和风格等。
接下来,为了满足用户对低延迟和低成本的需求,谷歌重磅发布轻量化模型Gemini 1.5 Flash。

谷歌对外解释,Gemini 1.5 Flash专为大规模服务设计,成本低至0.35美元/百万Tokens。它拥有更高的效率、更低的时延,不仅支持100万和200万Tokens两个版本,还适用于摘要、聊天应用、图像和视频字幕、长文档和表格数据提取等任务。
“它的上下文token数将会达到2000K,”皮查伊指出,相比之下,GPT-4 Turbo只有128K,Claude 3也只有200K。这意味着Gemini 1.5 Flash可以输入2小时视频、22小时音频、超过6万行代码或者140多万单词。
谷歌的Josh Woodward 详细介绍了 Gemini 1.5 Pro 和 Flash 的定价。
Gemini 1.5 Flash 的价格定为每 100 万个token 35 美分,这比 GPT-4o 的每 100 万个token 5 美元的价格要便宜得多。
除了Gemini模型自身性能之外,本次发布会还展示了Gemini的应用整合体验。
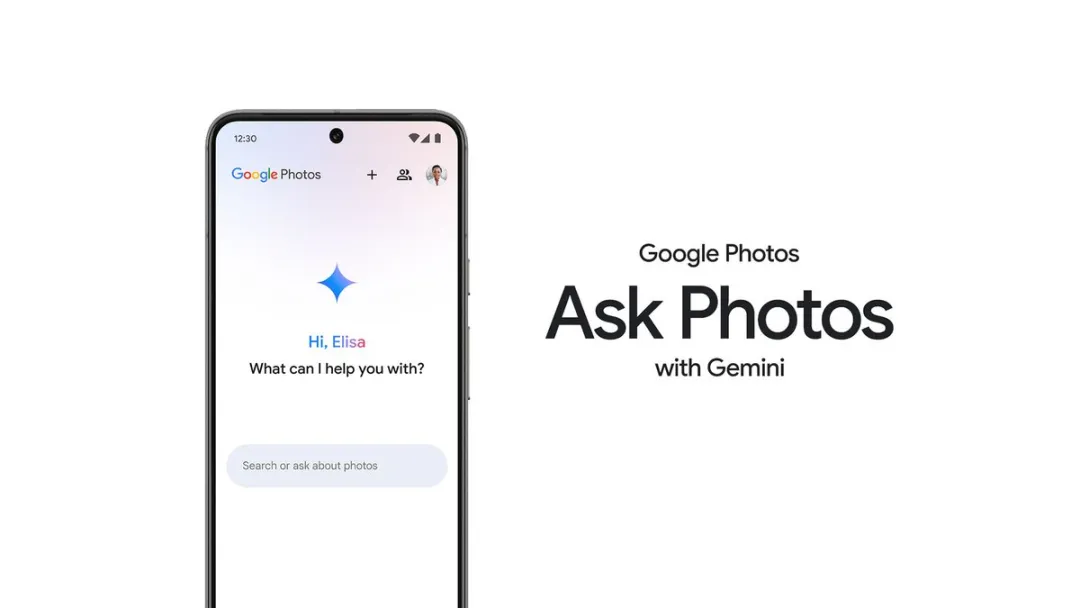
皮查伊演示了名叫Ask Photos的功能:当你停车并给车拍照后,Gemini可以帮你自动识别照片,提示你车停在了哪里。
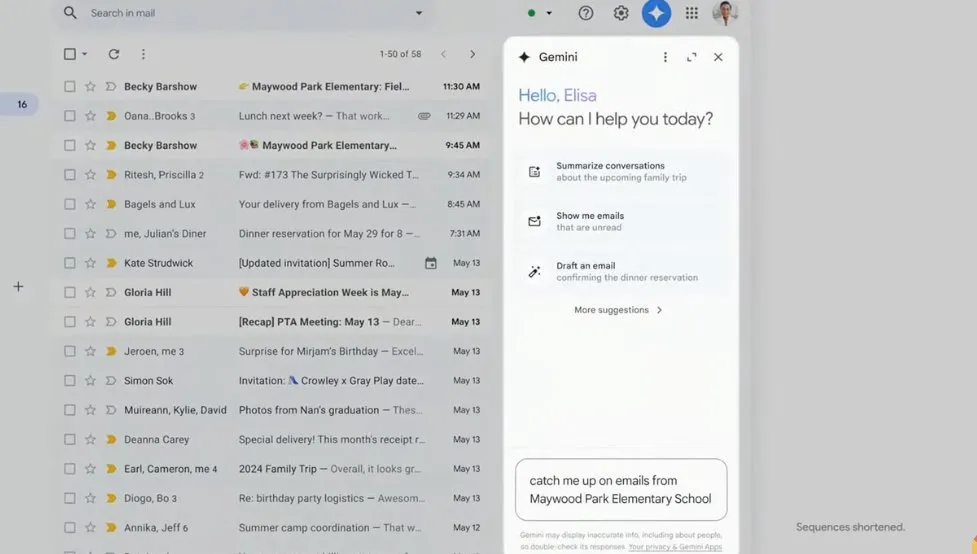
基于Gemini模型,Google的办公套件也迎来全面整合。
用户可以直接在Gmail中生成线上会议纪要,或者让AI助手在邮件中总结关键信息。
办公应用还能与 Google 表格联动,自动整理邮件中的表格文件,并整合成数据、分析表格等。
开源模型Gemma 2登场

本次I/O大会,谷歌还剧透了最新版Gemma 2。
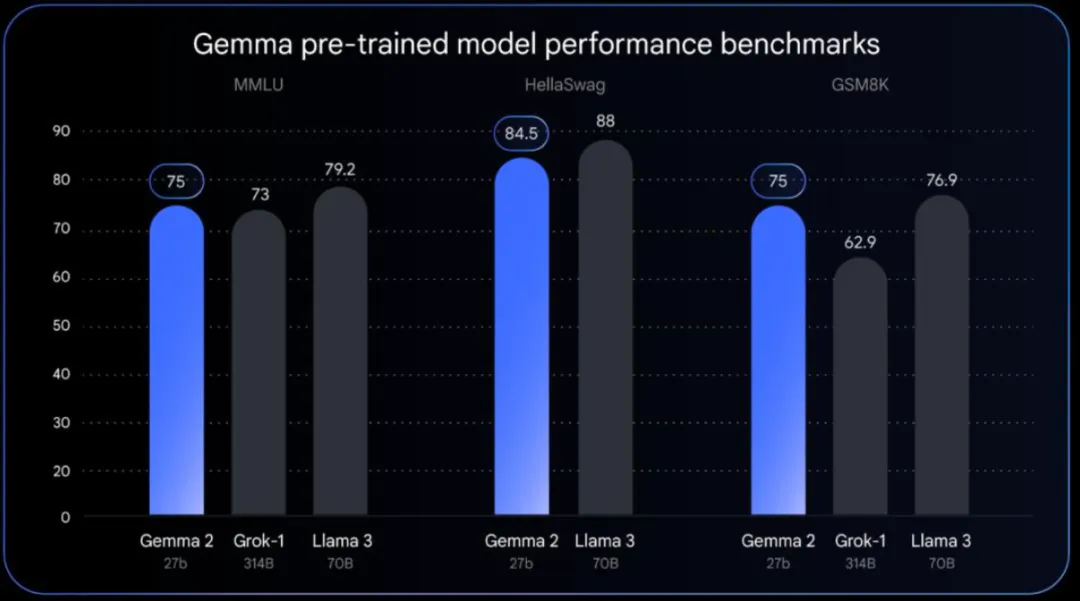
Gemma开源模型于今年2月问世,新版Gemma 2采用全新架构,参数达到27B,拥有突破性的性能和效率。
由于Gemma 2具有270亿个参数,其性能可与Llama 3 70B相媲美,但尺寸却只有Llama 3 70B 的一半。
谷歌表示,Gemma 2是一款轻量级、前沿的开放式模型,继承了 Gemini 模型的研究和技术精髓。颇有悬念的是,Gemma 2模型将在未来几周正式上线和发布。
目前,外部开发人员已能够使用预训练的Gemma变体PaliGemma。
资料显示,PaliGemma是谷歌受PaLI-3启发的第一个视觉语言模型,针对图像字幕、视觉问答和其他图像标记任务进行了优化。
比较有利于用户受益,Gemma 2 的高效设计使其所需的计算量少于同类模型的一半。27B 模型经过优化,可以在NVIDIA的GPU上运行,也可以在 Vertex AI 的单个TPU主机上高效运行,更易于部署且更具成本效益。
多模态生成式AI产品,对阵OpenAI
谷歌对阵OpenAI的努力,可见一斑。
除了对大模型领域的探索,DeepMind负责人哈萨比斯重点介绍了谷歌在多模态领域的新进展。
他表示,未来谷歌将在图像、音频以及视频三个主要内容领域全方位出击;同时推出五款基于Gemini大模型的生成式AI产品。
首先出场的是Project Astra智能助手。它与NotebookLM结合,将成为GPT-4o的有力竞争对手。
谷歌在演讲中,展示了一个人拿着手机在办公室走动,将摄像头对准各个方位,并用语言与其沟通。与此同时,Project Astra成功地识别出了各种物体、地点和代码,还能实时进行语音互动。
研发人员称, Project Astra可以通过连续编码视频帧、将视频和语音输入组合到时间线中,并缓存这些信息以进行有效回忆,从而更快地处理信息。
更有意思的是,智能手机上的Project Astra,可以通过摄像头识别周围环境,并与用户进行对话。
接下来,是谷歌的实验性产品NotebookLM。
基于全新的Gemini 1.5 Pro模型,NotebookLM再度升级,实装了语音助手功能,能够分析材料并回答问题。
Project Astra智能助手和NotebookLM的功能结合,可以直接对标OpenAI昨日发布的GPT-4o模型,成为能与用户实时对话的强大“AI 助手”。
最后,谷歌推出两款AI媒体创作模型:Veo和 Imagen 3,以及面向专业音乐创作者的音乐合成工具Music AI Sandbox。

这两款产品分别能对阵Sora的文生视频功能,和Dall-E的文生图技术。
谷歌Veo能通过文字描述,生成各种电影和视觉风格视频,可以理解“延时拍摄”或“风景空中拍摄”等指令,生成视频逼真而流畅,时间可以超过一分钟。
Imagen 3则是Google目前最高质量的文本到图像模型,可以产生更加逼真的视觉图像。
第六代 TPU芯片
除了AI新技术发布,谷歌还公布了TPU驱动软件的硬件引擎升级。

01
发布迄今为止最强大、最节能的张量处理单元Trillium TPU(第六代)。
据谷歌介绍,第六代硬件将为生成式人工智能模型和工作负载提供支持,提供比现有TPU显著增强的计算、内存和网络功能。
Trillium GPU的高带宽内存容量和带宽是原来的两倍,计算能力相比前代提升4.7倍,将在 2024年底面向用户(包括云客户)推出。
谷歌称,AI功能更新将作为Android今年的重点。除了APP之外,还将把Gemini进一步整合进入操作系统中。如:开发Gemini Live,实现流畅的对话功能来高效沟通;今年内发布基于Project Astra的摄像视频识别功能等。

03
Android 15中的Gemini能够支持YouTube视频内容识别。
用户可以在视频播放界面,通过Gemini直接提取视频相关信息、生成视频内容摘要等。
皮查伊透露,短短3个月内有100万+ Gemini Advanced 注册;有20亿用户产品(user products)全部使用 Gemini;超过150万开发者使用 Gemini。
参考资料
谷歌 I/O 2024大会;
谷歌 I/O 2024大会简报:谷歌强势回归,可惜被OpenAI抢了头条,AI寒武纪;
谷歌发布了第六代TPU芯片,半导体行业观察。
部分图片来源网络若涉及侵权请联系删除
撰稿 | 范美琪
责编 | 大方
排版 | 萝拉
校对 | 柚子
本文作者可以追加内容哦 !

