最近,相信大家的朋友圈都被一个词刷屏了:Sora。
2024年2月,在没有任何预兆和消息透露的情况下,OpenAI突然发布了自己的首个文生视频模型Sora,大幅刷新行业多个指标,将视频生成的时长一次性提升了15倍,实现了AIGC领域的里程碑式进展。

Sora到底“牛”在哪?对于创作者和行业来讲,它会产生哪些影响?本期好奇心营地就让我们一起来聊一聊Sora引发的商业浪潮。
Sora是什么?
Sora是一种基于AI算法下的文生视频模型,简单来说,就是你输入一段文字,Sora可以根据你的文字内容生成一段长达60秒的连贯视频,同时保证视觉质量。
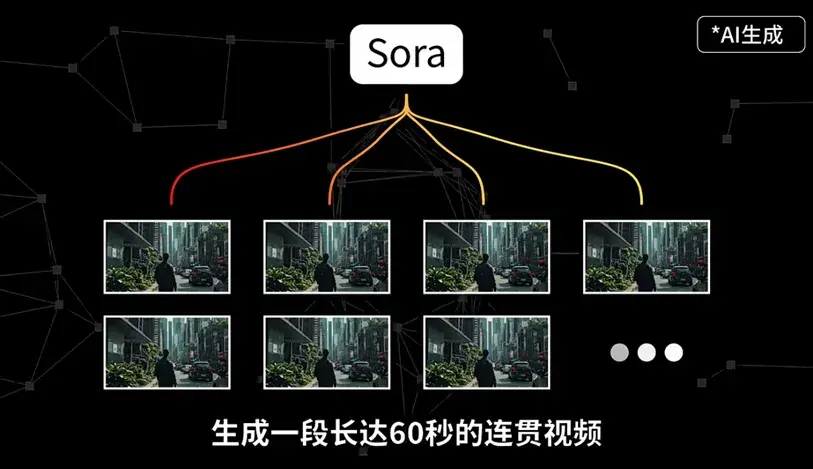
可以看到,不管是流畅度和稳定性,还是对光影反射、运动方式等细节的处理方面,特别是对物理世界的学习能力,Sora都表现出极高的水准,具体体现在:
01
语言理解能力
Sora不仅保持了视觉品质,而且完整准确还原了用户的提示语。
02
复杂场景与角色生成能力
Sora能够生成包含多个角色、背景细节复杂的场景,生成的视频具有高度的逼真性和叙事效果。
03
多角度镜头能力
Sora可以在单个生成的视频内实现多角度镜头,同时保持角色和视觉风格的一致性。
04
物理世界模拟能力
Sora对于光影反射运动方式等细节处理得十分优秀,如物体的移动、三维一致性和交互,极大提升了真实感。
05
静图生成视频能力
除了文生视频,Sora还能够从现有的静态图像开始,准确地动画化图像内容,或者扩展现有视频,填补视频中的缺失帧。

那Sora到底是怎样根据一段文字生成视频的呢?
这里就要提到Sora涉及到的两个关键技术,一个是Diffusion(扩散)模型,另一个是Transformer模型。
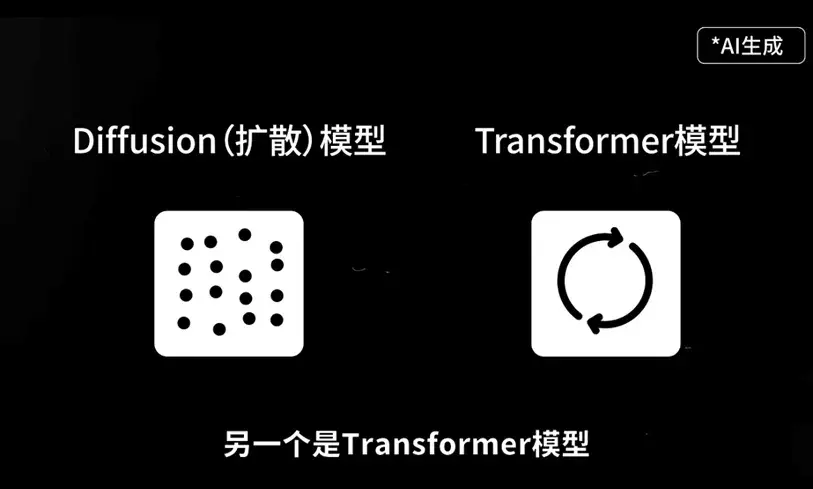
我们知道视频是由一帧一帧的图片连接而成的,在了解“文字生成视频”之前,我们应该先了解“文字生成图片”。这背后是一项称为Diffusion(扩散)模型的关键技术,通过正向扩散和逆向扩散两个过程,它能够将一张马赛克一样的图片,不断结合提示词提供的信息多次还原,最后形成一张完整、清晰的图片。

那如何让图片动起来成为一个视频呢?这就要用到机器学习的经典模型——Transformer模型了。
实际运用过程中,Sora把视频分解为了更小的数据单元3D Patch(时空碎片),提高了视频训练和推理的效率,而这也是Sora最大的创新之处。这种3D patch的做法,首先让视频效果更好了,因为生成视频的时候不再是粗暴地“补帧”,所以一致性、连贯性都更好;其次,这种切割方法很省算力,训练和推理算力的效率变得更高了,单位算力能训练出更好的模型、也能生成更长的视频时长。

Sora对行业的影响
尽管Sora在模拟能力方面已经取得了显著的进展,但它目前仍然存在许多局限性。例如,它不能准确地模拟许多基本相互作用的物理过程,比如吃东西时,Sora并不能总是产生正确的对象状态变化。

不过即使如此,Sora对于AI应用的商业化还是意义重大的,最直接的应用场景就是视频、3D内容的制作,预计未来将对短视频/短剧、游戏、广告、影视等行业有很大的帮助,长期看可能会极大降低视频内容生成的中间成本、提高视频创作效率,重构内容行业的生产模式。而视频内容制作成本和门槛大幅降低的同时,也会一定程度上加剧行业的竞争,所以,未来更多比拼的将是创作者的prompt能力,即创意、想法的能力。

我相信,随着技术的不断进步和创新,Sora所展现出的能力预示着生成式AI持续扩展的巨大潜力。随着大模型认识和学习物理世界能力的进一步深化,人工智能在未来或将迎来跨越式发展,或极大拉近我们与更具通用性的未来智能世界的距离。

*风险提示:基金有风险,投资需谨慎。投资人应当认真阅读《基金合同》、《招募说明书》、《产品资料概要》等基金法律文件,了解基金的风险收益特征及其特有风险,并根据自身的投资目的、投资期限、投资经验、资产状况等判断基金是否和投资人的风险承受能力相适应。基金管理人不保证基金一定盈利,也不保证最低收益或本金不受损失。基金过往业绩及其净值高低并不预示其未来业绩表现,基金管理人管理的其他基金的业绩并不构成本基金业绩表现的保证。
本文作者可以追加内容哦 !

