各位客官请细看![[愉快]](http://gbfek.dfcfw.com/face/emot_default_28x28/emot26.png "愉快")
我把这里的信息串联一下,你们大概就懂了
1,旭创拿下微软主供
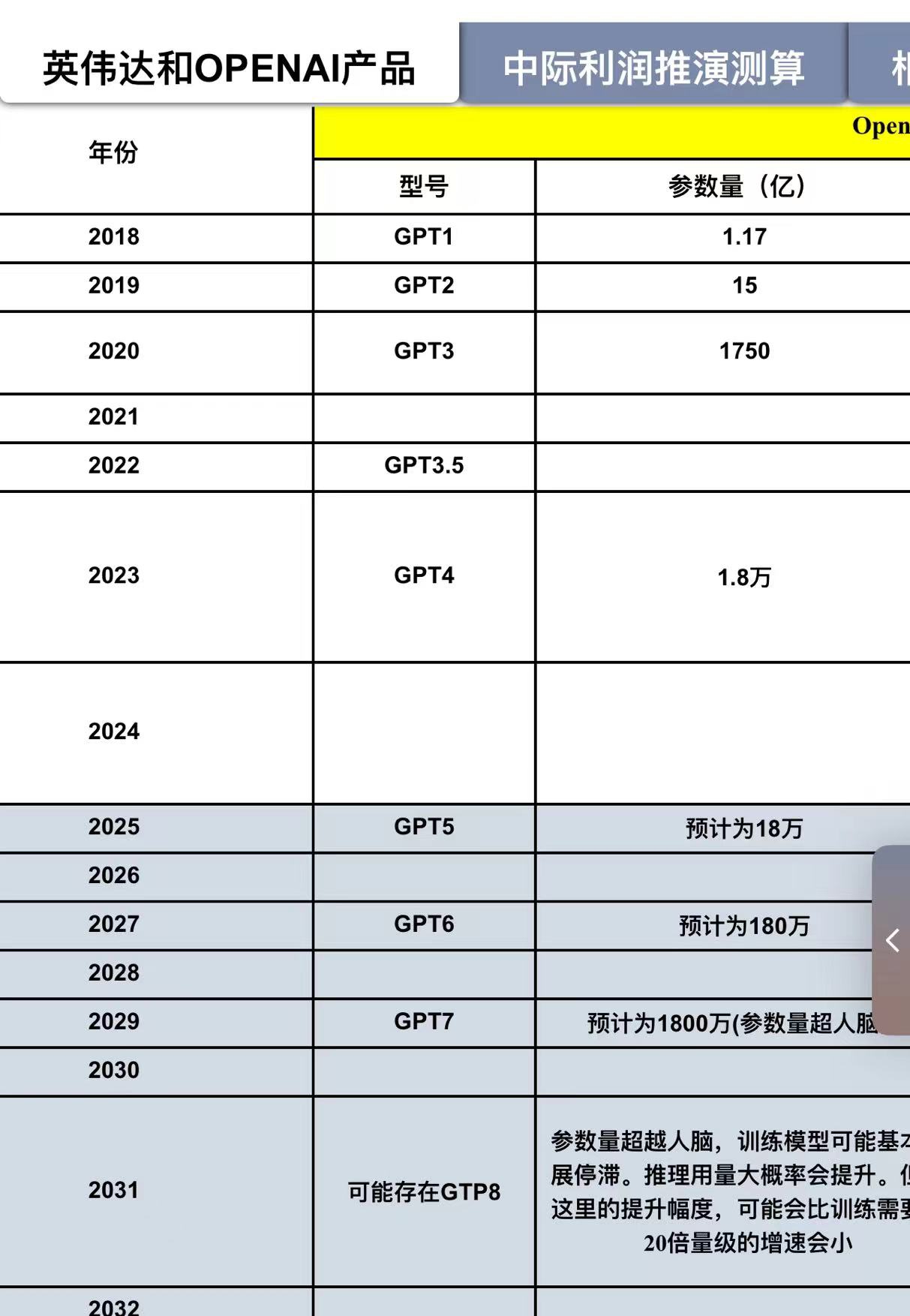
2,据媒体周日报道,OpenAI首席技术官Mira Murati近日透露,公司正在开发的新一代人工智能模型GPT-5,有望在2025年底或2026年初推出,在特定任务中达到博士级智能水平,标志着人工智能技术可能迎来又一次重大飞跃。
据悉,GPT-5内部代号为“Gobi”和“Arrakis”,是一个具有52万亿参数的多模态模型,上一代GPT-4参数约为2万亿。这一庞大的参数规模暗示了其潜在的强大能力。Murati将GPT-4到GPT-5的进步比作从高中水平到大学水平的跨越,表明新模型在复杂性和能力上将有显著提升。
3,GF通信的点评大概率确认了第一条这件事,并且进一步上修800G出货量,快接近翻倍
————
继续往下看,
可能市场会理解的负面第二点
其实本身OpenAI之前的节奏基本就是2年左右的版本迭代周期,参数量个人预计大概是18到20万亿
但目前公布的数据翻了1.5倍,显著超预期,这意味着算力需求大概是GTP4的140倍左右(根据缩放法则,测算)
此前爆料的数据:OpenAI训练GPT-4的FLOPS约为2.15e25,在大约25000个A100上训练了90到100天,利用率在32%到36%之间……但是放到今天,在2美元/每H100小时的条件下,预训练可以在大约8,192个H100上进行,只需要55天。
马斯克此前透露,xAI正在训练的Grok 2已经耗费了约2万块H100 GPU,训练进程一度因芯片短缺受阻,预计于今年5月训练完成。未来进阶版本的Grok 3可能需要高达10万块H100 GPU。
Meta计划在2024年底之前,将其人工智能基础设施扩大到高达35万个H100 GPU。目标是拥有相当于近60万个H100 GPU的算力。
2022年初,Meta和英伟达发布了一个大型AI研究超级计算机,其连接了6080个A100 GPU,可以提供五百亿亿次级的AI计算性能。全面部署后,这一超级计算机成为最大的英伟达DGX A100客户系统,用于训练具有超过1万亿个参数的AI模型。
再有:英伟达在近期台湾发布会上,发布了基于以太网的spectrum-x下一代以太网交换机,并表示未来能够支持百万级别超大规模数据中心集群。
————
好,重点来了:
按照以上的数据去做对照性的推测:
8192张H100140=114万张GPU,则目前确实已经需要到百万张卡的集群。两者信息可以相互对照
另外,即便GB200,有4倍的训练性能提升,也需要28.5万张GPU的链接。
大概可以对照迈威尔科技和博通所说的百万GPU集群
而再进一步,这个信息,可以对照下微软为何要自己招标光模块——百万集群所需的光模块数量巨大……
所以,具体到所谓的“推迟”这件事
按我的理解:
第一,实际并没有时间表,或者可能内部有,但此前的节奏就是两年一迭代。(笔者之前对英伟达中际的测算都是基于此。目前股价表现信息上,和实质代际更新并没有偏差。)
第二,现在由于人工智能已经表现出强大的能力,需要做更为稳妥的超级对齐(同样还需要增加额外的算力,此前OpenAI团队公布的数据是当时预计为20%)
第三,参数超预期,算力需求的验证也超预期,或者说起码算力需求目前看仍远未到顶部,与已经开始建立百万GPU集群可以对应。
第四:如果我们测算下,5万美金的GB200,GTP5大概需要28.5万块。对应资本支出142万亿美金。
那么下一代GTP6(算力需求提升20倍),所需要对应的,大概对应的是28.520=570万块GB200,如果R200系列训练能力仍然是扩张4倍,则对应142万的GPU集群。下一代GPU提价30%,达到6.5万美金的假设下,支出需要在923亿美金。就与此前爆料,微软与OpenAi将打造「星际之门」超算,预计会配备数百万专用的服务器芯片!项目的成本,预计高达1150亿美元。能够对应上了。
这里再八卦一下,星际之门的含义,个人理解:如果GTP5对应的博士水平,那么GTP6,确实能够对应顶级科学家,甚至超越人类,真正的打开“星际之门”。(这里也是一个信息的对照)
好了,晚安。
明天看A股表演![[抱拳]](http://gbfek.dfcfw.com/face/emot_default_28x28/emot55.png "抱拳")
本文作者可以追加内容哦 !

