今年,我们又获得了DCASE比赛声音事件定位与检测任务双赛道冠军、小样本动物声音检测任务冠军这些比赛是什么意思?简单来说:
在声音事件定位与检测任务上,今年的比赛不仅需要预测声音事件有哪些、到达的方向,还要估计声源的距离;在小样本动物事件检测任务上,需要在各种干扰声音下,从一段长音频中查找出所有给定目标动物(比如美洲麻雀、北美红雀)发声的起始及结束时间。
我们和联合团队以显著领先优势获得这三个赛道的冠军,并且已将声音定位与检测技术应用于电力、矿山、制造业等领域,研发了工业听诊器和声学成像仪等AI声学检测产品,助力各领域作业提质增效。

继2020年、2022年及2023年在国际声学场景和事件检测及分类挑战赛(Challenge on Detection and Classification of Acoustic Scenes and Events,简称DCASE)中获得声音事件定位与检测冠军以及小样本动物声音检测冠军之后,今年,科大讯飞研究院联合中科大语音及语言信息处理国家工程研究中心(简称NERCSLIP)、国家智能语音创新中心,以显著领先优势获得音频赛道和音视频赛道双项第一;科大讯飞研究院与国防科技大学(简称NUDT)复杂智能软件系统项目组联合团队也获得了小样本动物声音检测任务冠军,再次证明智能音频技术领域的不俗实力。
DCASE是目前声音事件领域最权威的竞赛之一,自2013年组织发起以来已举办了10届。DCASE 2024挑战赛设置了10个任务,吸引了全球108支队伍进行角逐,共接收到321个提交系统。本次赛事在声音事件定位与检测任务上,除了需要预测声源的到达方向,还引入了声源距离估计,任务的难度系数显著提升;而在小样本动物事件检测任务上,今年则增加了水下动物类别,对算法泛化性提出新的挑战。
音频赛道:
独立训练与联合推理方法解决多任务问题
本次声音事件定位与检测(简称SELD)任务的测试数据在真实场景下录制,不同类别声音事件在时域重叠率较高,并且要求同时预测声音事件的类别、估计到达方向和新增的声源距离,多任务问题给建模带来了极大的挑战。基于此前在DCASE 2023 Task3中夺冠的音频通道交换数据增强方法与预训练模型,联合团队进一步提出了独立训练和联合推理的方法以解决多任务问题。
具体来说,联合团队提出训练两个子模型分别专注于解决声音事件类别-到达方向估计和声音事件类别-声源距离估计子任务,并在推理阶段联合两个子模型得到最终多任务的预测结果。

联合团队所提出的独立训练和联合推理的方法有效地解决了任务问题,同时在新增的声源距离估计子任务上也表现优异。
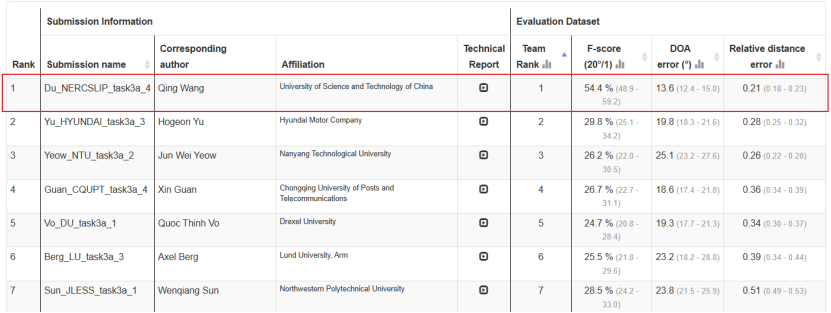
联合团队在检测F-score、定位错误率和相对距离误差三项指标中全部获得第一,其中F-score超越第二名绝对值24.6%,最终以显著优势夺得单音频赛道冠军。
音视频赛道:
多项创新技术有效提升声音定位与检测效果
此次音视频赛道中,官方发布的音视频数据仅有3.8小时,不足以训练一个鲁棒的音视频SELD模型。针对此次比赛,联合团队提出了多项创新技术,以应对真实场景下的音视频声音事件定位与检测任务:
音视频数据处理与增强:利用房间脉冲响应及声源的方向标签,生成多通道音视频仿真数据,并基于音频通道与视频像素交换(AVPS)数据增强方法,进一步丰富了训练数据多样性,有效提升了模型的泛化性及鲁棒性。
特征融合与知识迁移:利用预训练模型进行视觉特征提取,与声学特征进行早期融合,并采用跨模态迁移学习技术,加快了模型在音视频任务的学习速度,同时结合人体关键点检测算法,实现了高精确的声源定位。

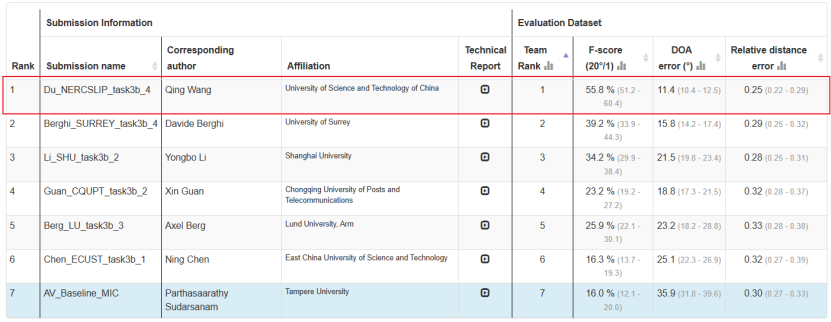
通过上述方案,联合团队最终在音视频赛道的F-score上取得55.8%的好成绩, 以超越第二名绝对值16.6%的大幅优势获得冠军,实现了全新突破。
解析动物交响乐技术叒升级:
引入新技术解决小样本检测难题
DCASE 2024挑战赛小样本动物声音事件检测任务中,需要在仅给定5条目标声音片段的条件下,从一段长音频中查找出所有目标发声的起始及结束时间。目标声音都是动物发出的声音,例如美洲麻雀、北美红雀等。该任务要求参赛队伍在指定数据集下完成系统构建,且不能使用多系统融合策略。
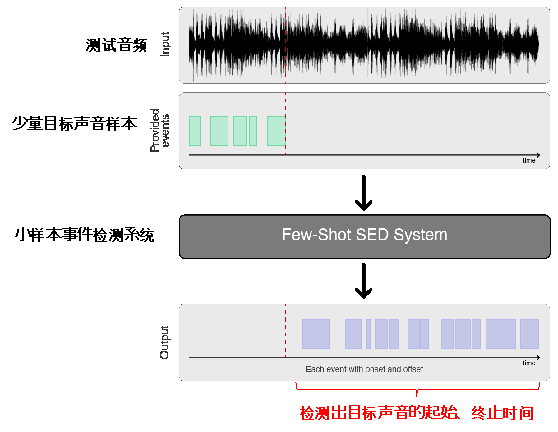
此次的比赛有这些难点:测试集与训练集关联度低,采集场地、设备、动物类别等均无重合,训练数据的动物叫声类别很少,动物叫声差异较大,很难完全依赖训练集进行目标声音检测;测试音频混淆大,存在其他类别的动物叫声、摩托引擎声等噪声,同时存在目标音频很短且与其他声音重叠的现象。
凭借多年技术积累与不断探索创新,联合团队再次升级比赛方案,提出两大关键技术改进系统性能,进一步提升小样本动物声音事件检测效果。
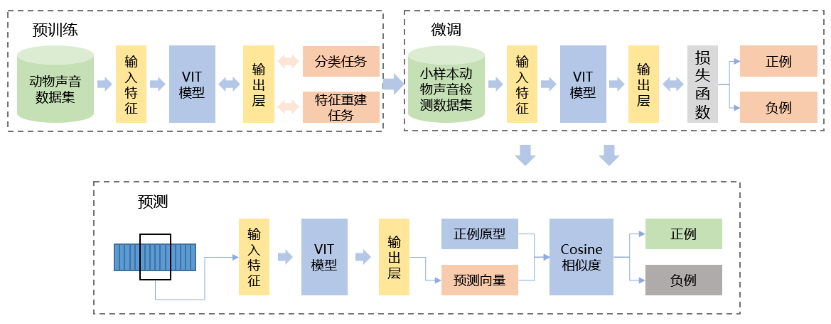
在有监督和半监督相结合的帧级小样本检测方案基础上,首次引入U-Net网络框架,针对部分动物发声持续时间波动大的特点,团队修改U-Net网络并将其作为帧级检测方案的基础模型,能够同时提取低层次的细节和高层次的语义信息,达到高精度的检测效果。
训练帧级大规模通用动物声无监督预训练模型(AAPM),以获取更加匹配的通用表征,在有监督微调阶段,针对正负例占比差异及声学特性,团队设计了一种基于余弦相似性的损失函数来指导模型训练,并采用自适应调节帧长的段级检测策略提升检测性能。
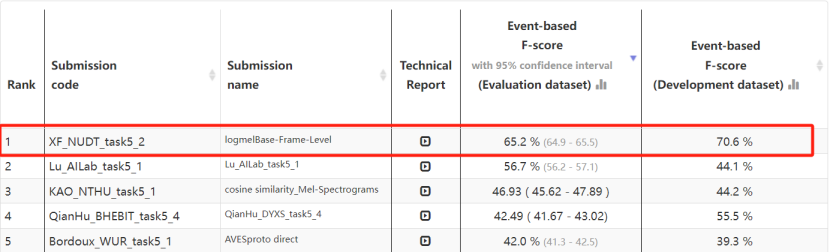
最终,基于上述方案打造的小样本动物声音事件检测系统在开发集上取得领先效果,在测试集上F-score得分为65.2%,再次拿下该任务冠军。
机器辨声应用落地
助力工业AI检测
目前,科大讯飞已经将声音定位与检测技术应用于电力、矿山、制造业等领域,研发了工业听诊器和声学成像仪等AI声学检测产品。
工业听诊器在浙江、安徽、宁夏等全国50余个变电站、风电站、水电站等地部署运行,对直流偏磁、局部放电、短路冲击等类故障识别率达99%,建立设备故障、环境异音、负荷样本、开关样本4大类型、24个细分类样本库,积累18万余小时数据样本。

声学成像仪广泛应用于燃气站、化工厂、加气站等多个关键场景,以燃气站场景为例,可以检测出法兰、阀门、管道弯头等多处泄漏点,将近5小时人工检测缩短至30分钟,大幅提高气体泄漏检测效率。

此外,科大讯飞工业智能研发听觉、视觉、触觉、嗅觉、味觉及工业大脑融合的工业六感技术,推出声学成像仪、工业内窥镜、工业六感机器人等“讯飞潮汐力”系列产品,引领工业AI检测产品创新,助力工业生产提质增效。
万物互联时代,全新人机交互的方式正在发生变革,赋能各行各业激发全新的应用落地可能。作为智能语音技术的重要部分之一,科大讯飞也将持续发力智能音频技术方向,不断探索相关技术与实际产品应用结合的可行之路。
本文作者可以追加内容哦 !

