7月9日,备受行业关注的《中文大模型基准测评2024上半年报告》由SuperCLUE正式发布。该报告对国内外33个代表性大模型进行了全面而深入的评估,通过多维度综合性测评,旨在观察与思考当前大模型技术的发展现状。在本次半年度评测中,云知声山海大模型以总分72的优异成绩脱颖而出,与360gpt2-pro、字节跳动豆包、月之暗面Kimi、百川智能Baichuan4等大模型并列国内大模型第四名,跻身全球大模型第一梯队。
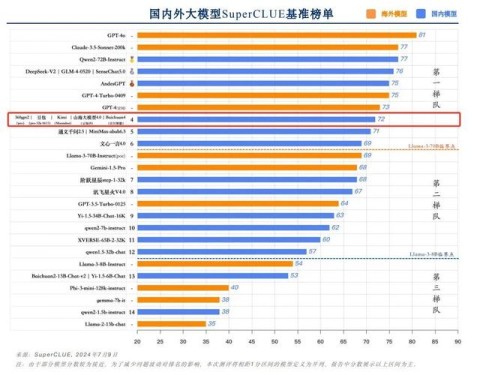
SuperCLUE,作为国内领先的通用大模型评测基准,一直致力于为行业提供科学、公正的评测服务。其评测体系经过多年的打磨和完善,已经形成了多层次、多维度的综合性评测标准。本次测评采用了自动化评测技术,确保了评测结果的客观性和准确性。

在测评内容上,SuperCLUE通过考察模型的传统能力,引入开放主观问题,模拟大模型在实际应用中的场景,全面评估了模型的生成能力。这种多维度、多视角的评测方式,使得测评结果更加全面、深入。
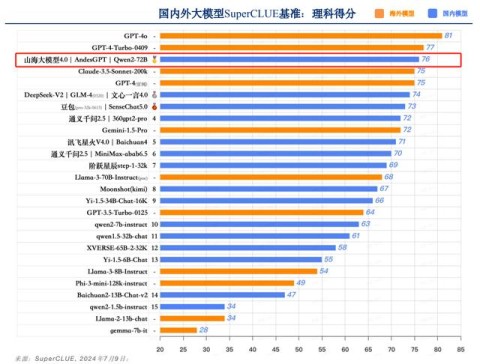
山海大模型在本次测评中展现出强大的实力。在理科任务中,其以精湛的计算、逻辑推理和代码处理能力,紧随国际领先的GPT-4系列大模型之后,位列国内第一。在文科任务中,山海大模型同样表现出色,以丰富的知识百科储备、出色的语言理解能力和强大的生成与创作能力,并列国内第二。
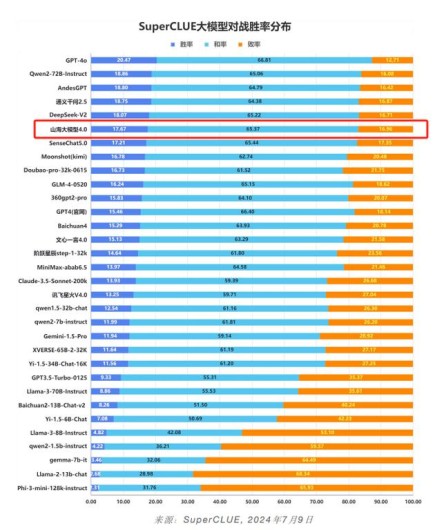
SuperCLUE的模型象限图更是将山海大模型定位为“卓越领导者”,由此可见山海大模型在基础和应用能力上的优胜地位。值得一提的是,在与GPT4-Turbo-0409的对战中,山海大模型也取得了不俗的战绩,胜率为17.67%,和率为65.37%,位列国内大模型第五,进一步印证了其强大的实力。
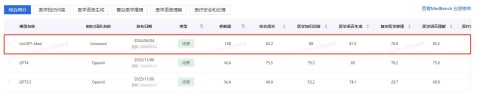
不止在此次《中文大模型基准测评2024上半年报告》表现突出,自推出以来,山海大模型已在多个权威评测中屡创佳绩,充分展现了其卓越的通用能力和行业优势地位。在此前由上海AI实验室和上海市数字医学创新中心联合推出的MedBench评测更新榜单,云知声山海大模型医疗行业版(UniGPT-Med)同样表现不俗,以综合得分82.2的优异成绩位列全球第一,各项指标全面超越GPT-4。而在更早之前的SuperCLUE的评测中,云知声山海大模型通用能力也跻身国内大模型Top10,长文本能力位列全国三甲,实力有目共睹。
纵观山海大模型,它并非一成不变,自诞生以来始终保持着高效、专业的进化频率,让行业真切感受到其蓬勃的发展潜力和综合实力。值得一提的是,云知声重视山海大模型综合性能提升之外,同样关注场景应用,持续提高其商业价值。
在大模型场景应用探索上,云知声基于过往实践经验,将山海大模型应用于熟悉的医疗、座舱、交通等行业场景——在医疗领域,云知声基于山海大模型打造的门诊病历生成系统已落地北京友谊医院,有效提升了病历撰写效率与质量;在政务领域,云知声率先开发出深圳首个政务大模型“龙知政”,全场景赋能提升政府治理水平;在座舱领域,云知声通过山海大模型赋能吉利睿蓝汽车打造情感型虚拟助手,为用户带来全车全场景的情感化智能交互体验;在交通领域,云知声山海大模型“入驻”南宁火车东站,打造更具人性化的智能客服,为乘客带来更快捷、更便利的出行体验,相关案例也于近期被央视《焦点访谈》栏目报道……
展望未来,随着技术的进步和应用场景的不断拓展,大模型市场的竞争将更加激烈。而通过云知声山海大模型性能的稳步提升,以及致力于在产业侧实现更广泛的应用探索之路,可以预见,山海大模型将成为助力各行各业的“新质生产力”,为人工智能技术的发展和应用开辟新的“新路”。
本文作者可以追加内容哦 !

