
智谱AI终于也赶上了这波文生视频的热潮
7月26日,智谱AI在7月的OpenDay活动中,对外发布了一款全新的文本生成视频(文生视频)工具清影智谱(Ying)。用户只需输入一段几个字到几百个字不等的文字描述,最快30秒即可生成一段高精度视频。
自Sora向世人展示了大模型文生视频的强大能力后,包括Runway的Gen系列、微软的Nuwa、Meta的Emu、谷歌的Phenaki/VideoPoet、CogVideo等在内的大模型项目都发布了文生视频的功能。作为国内大模型公司杰出代表的智谱AI,终于也赶上了这波文生视频的热潮。
智谱CEO张鹏在智谱 Open Day上宣布,AI生成视频模型清影(Ying)正式上线智谱清言,面向所有用户开放。输入一段文字后(俗称Prompt),用户可以选择自己想要生成的风格,包括卡通3D、黑白、油画、电影感等,配上清影自带的音乐,就生成了充满AI想象力的视频片段。
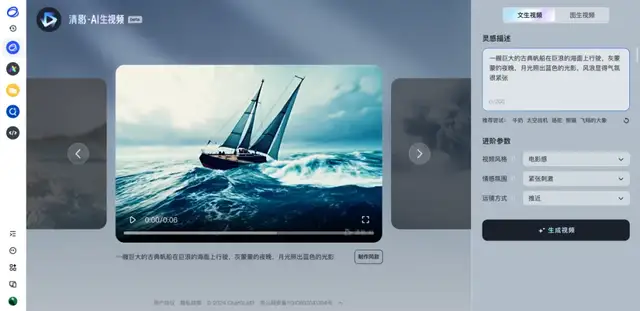
(点击文末阅读原文体验智谱清言 )
除了文生视频的功能以外,清影还具备图片生成视频(图生视频)的能力。图生视频拥有更多的应用场景,譬如表情包梗图、广告制作、剧情创作、短视频创作等。同时,基于清影的「老照片动起来」小程序也会同步上线,用户只需一步上传老照片,就能在AI的帮助下,让凝练在旧时光中的照片灵动起来。
商用方面,清影(Ying)API 也同步上线大模型开放平台bigmodel.cn,企业和开发者通过调用API的方式,体验和使用文生视频以及图生视频的模型能力。
新型DiT模型架构,更高效地压缩视频信息,以及更充分地融合文本和视频内容,让清影在复杂指令遵从能力、内容连贯性、大幅的画面调度上具有一定独到之处。
在智谱AI的Openday上,智谱CEO张鹏向外界展示了首批获得测试资格的创作者们生成的视频。
智谱AI CEO 张鹏透露:
本次清影(Ying)底座的视频生成模型是CogVideoX,它能将文本、时间、空间三个维度融合起来,参考了Sora的算法设计,它也是一个DiT架构,通过优化,CogVideoX 相比前代(CogVideo)推理速度提升了6倍。我们将继续努力迭代,在后续版本中,陆续推出更高分辨率、更长时长的生成视频功能。
张鹏表示,清影(Ying)的研发得到北京市的大力支持。当前,北京正在以海淀区为核心打造人工智能产业高地,海淀区是智谱AI总部所在地,为智谱AI开展大模型研发提供了产业投资、算力补贴、应用场景示范、人才等全方位支持。
清影(Ying)的训练依托亦庄高性能算力集群,受益于亦庄良好的人工智能产业生态。清影(Ying)在北京亦庄算力集群诞生,未来也将应用于北京亦庄广阔的高精尖产业集群,形成大模型赋能实体经济的新业态。
bilibili 作为合作伙伴也参与了清影的技术研发过程,并致力于探索未来可能的应用场景。同时,合作伙伴华策影视也参与了模型共建。
本文作者可以追加内容哦 !

