
就在英伟达股价陷入连续调整之际,被市场给予厚望的GB200延期交付了
01 史上最强AI超算GB200
时间拨回到五个月前,英伟达2024GTC大会上,英伟达创始人兼首席执行官黄仁勋正式发布全新GPU平台架构Blackwell,推出基于Blackwell的B200和GB200超级芯片,AI计算能力大幅提升。
简单来说发布会上发布了一种基于Blackwell架构的B100和B200GPU芯片,B100和B200的区别主要在能耗上,这种Blackwell架构实际上是指“双芯”GPU,即两颗采用了台积电4nm增强版工艺的Blackwell GPU,通过10TB/s带宽的片间互联技术合二为一。
两颗B200芯片加一颗Grace CPU芯片,构成了新一代超级芯片Grace Blackwell即GB200。

在GB200基础上,英伟达还打造了由36块GB200芯片即包含36颗Grace CPU、72颗B200 GPU、240TB HBM3e内存的全新一代AI超算DGX SuperPOD。

此外英伟达还针对有大型需求的企业提供服务器成品和完整的服务器解决方案——GB200 NVL72服务器搭载36个CPU和72个B200 GPU,并配备一体水冷散热方案。

02 GB200跳票
英伟达在今年3月发布了Blackwell系列,首席执行官黄仁勋在5月时还信心满满地表示,公司计划在今年晚些时候开始批量出货Blackwell系列芯片。
GB200芯片包含两个相连的B200 GPU芯片和一个GraceCPU。一个B200 GPU又是由两颗Blackwell GPU组成。然而,在最近几周台积电工程师为量产进行准备时,却在连接两个Blackwell GPU的裸晶上发现了设计缺陷。这一缺陷会导致芯片良率或产量降低,通常做法是停止量产。
因此,英伟达不得不对芯片设计进行调整,并在开始量产前,与台积电合作进行新的试生产。
芯片出货延迟并非闻所未闻,但在即将量产前发现重大设计缺陷的情况还是非常罕见的。
台积电原本计划在第三季度开始量产Blackwell系列芯片,并从第四季度开始向英伟达客户批量发货。然而,由于设计缺陷的发现,量产时间不得不推迟到第四季度,批量出货的时间预计要推迟到明年第一季度。台积电为量产GB200保留了产能,但在问题解决之前,不得不让产线闲置。
03 哪个环节出了问题
大模型特点是使用了超大规模的参数模型,通过海量的数据进行训练,从而实现了AI能力的突破与赋能,其中不管是5nm、3nm还是GB200使用的较为成熟的台积电N4P工艺,摩尔定律正在逼近物理极限,这意味着未来单一芯片的运算能力其实是存在上限的。
因此,一个芯片算不明白,就用多个芯片算,这就是为什么大模型对分布式技术和多个计算节点协同工作有着越来越高的要求。而分布式技术和多个计算节点协同工作的核心就是数据交换效率,这个效率是芯片与芯片间,服务器与服务器之间的数据交换效率。
英伟达B200 GPU芯片里由两颗Blackwell GPU组成,问题就出在这里。B200 GPU芯片采用的是台积电的CoWoS封装。
在先进封装行业研究【下】中我们提到过,台积电的CoWoS根据不同的互联方式又分为三种:CoWoS-S、CoWoS-R和CoWoS-L。
CoWoS-S在连接多颗芯片时,使用Si中介层:
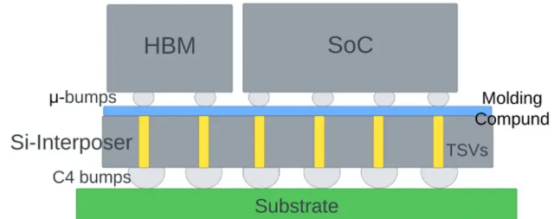
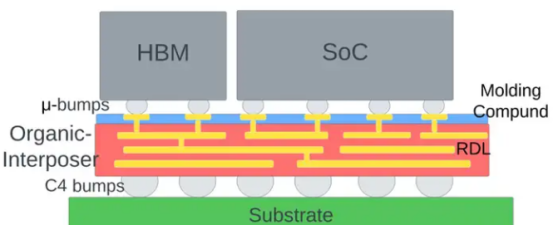
CoWoS-R使用的是重新布线层(RDL):
CoWoS-L封装使用本地硅互连(LSI)和 RDL 内插件,共同构成重组内插件(RI)。除了 RDL 内插件外,它还保留了 CoWoS-S 的诱人特点,即硅通孔(TSV)。这也缓解了CoWoS-S中由于使用大型硅内插件而产生的良品率问题。在某些实施方案中,它还可以使用绝缘体通孔(TIV)代替TSV,以最大限度地降低插入损耗。
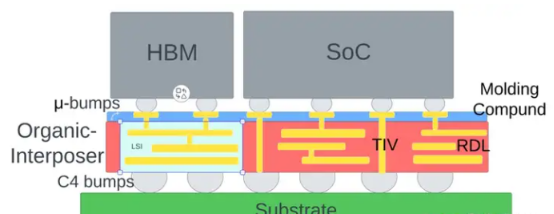
这次B200采用的为CoWoS-L封装,问题就出在,连接两个Blackwell GPU的裸晶上发现了设计缺陷。
04 影响如何
这次GB200跳票无疑打乱了英伟达客户的计划,特别是对于微软、谷歌和Meta这样的巨头来说。根据此前消息,谷歌已经订购了40多万颗GB200芯片,加上服务器硬件,订单成本可能远远超过100亿美元。Meta也下了一份价值至少100亿美元的订单。
而微软最近几周的订单规模也增加了20%,他们原本计划在明年1月份前向OpenAI提供由基于Blackwell系列芯片的服务器,但现在可能至少要推迟到明年3月。
AI企业原本期望在2025年第一季度就能在其数据中心运行由Blackwell系列芯片驱动的大型集群,实现计算能力飞跃,从而更好地生成AI回答、视频或执行任务。
然而,现在他们不得不面对芯片交付推迟的现实,这可能会影响到ChatGPT、Meta AI以及其他未来几代大模型和AI应用的开发进度

本文作者可以追加内容哦 !

