大模型发展呈现“规模定律”,Transformer为技术基座
大模型(LLM)发展普遍呈现“规模定律”特征,即:模型的性能与模型的规模、数据集大小和训练用的计算量之间存在幂律关系。当前主流大模型普遍是基于Transformer模型进行设计的,Transformer由Encoder(编码器)和Decoder(解码器)两类组件构成,而OpenAI的GPT是Transformer演化树中Decoder-only架构的代表。我们认为GPT的成功也并非全部源自技术性因素,OpenAI能够从早期众多的技术路线中识别到并坚定执行这条路线,这需要大模型团队足够的技术前瞻和定力。
全球大模型竞争白热化,国产大模型能力对标GPT-3.5Turbo
全球大模型竞争中,OpenAI、Anthropic、谷歌三大厂商为第一梯队,2024年以来三家大模型能力呈现互相追赶态势。从模型能力来看,根据SuperCLUE上半年 最新的评测结果,国内绝大部分闭源模型已超过GPT-3.5Turbo,其基准上表现最好的国产大模型为阿里云的开源模型Qwen2-72B,超过众多国内外闭源模型,与GPT-4o仅差4分。
大模型发展催生海量算力需求,预计带来千亿美元市场规模
大模型技术与应用发展催生海量算力需求,根据Jaime Sevilla等人的研究,2010-2022年在深度学习兴起背景下,机器学习训练算力增长了100亿倍。持续增长的大模型与AI产品研发需求同时也推升了科技巨头的资本支出。
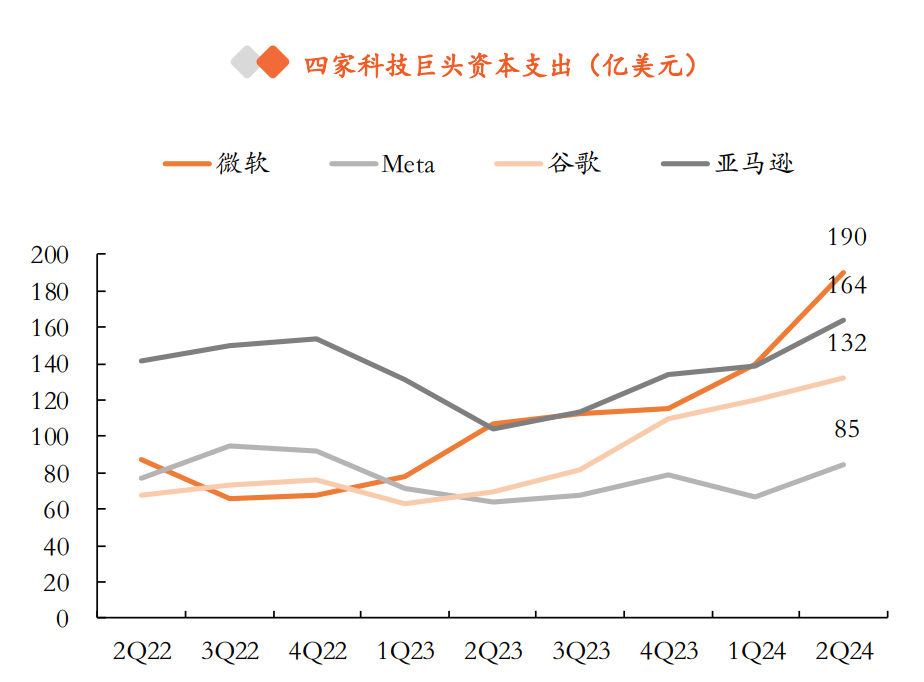
在此背景下,大模型的持续迭代升级将为AI芯片及服务器发展提供强劲动力,我们对不同参数规模的大模型在训练与推理两个阶段的算力需求进行了测算,设未来有100家大模型实现持续经营,最终测算得到AI服务器的市场规模为2301亿美元。
投资策略
当前,全球范围内大模型领域的竞争依然白热化,我国大模型厂商持续迭代升级算法能力,2023年底国产大模型市场迈入爆发期,根据SuperCLUE上半年最新的评测结果,国内绝大部分闭源模型已超过GPT-3.5Turbo,将有望加速国产大模型在各场景的应用落地。
以上涉及个股仅作为教学案例,不构成投资建议,仅供参考学习。
参考来源:2024年8月15日 中国平安 闫磊,黄韦涵,王佳一 大模型发展迈入爆发期,开启AI新纪元
特别声明:文章内容仅供参考,不构成投资建议。投资者据此操作,风险自担。
本文由投资顾问:尚亚雄 A1290623030001 编辑整理
本文作者可以追加内容哦 !

