
Hot Chips 向来都是芯片领域的盛会。2024 年的 Hot Chips 在美国斯坦福大学纪念礼堂隆重举行。迄今为止,Hot Chips 展会已成功举办了 36 届。
数十年来,该展会一直是探讨英特尔、AMD、IBM 以及众多其他供应商最前沿芯片的热门之地,各公司也常常借此展会发布新产品。
英伟达:公布Blackwell架构细节,2024年至2028年的产品路线图
IBM:下一代 AI 加速器Telum II
英特尔:下一代英特尔至强 6 SoC、Lunar Lake客户端处理器
AMD:Zen 5 核心架构解析
高通:Oryon核心解析
特斯拉:TTPoE,即特斯拉以太网传输协议
中国香山高性能RISC-V处理器亮相
01
英伟达:公布Blackwell架构细节
英伟达公布了下一代GPU架构Blackwell的更多细节信息,以及未来的产品路线图。
英伟达Blackwell是通用计算全栈矩阵的终极解决方案,由多个英伟达芯片组成,包括Blackwell GPU、Grace CPU、BlueField数据处理单元、ConnectX网络接口卡、NVLink交换机、Spectrum以太网交换机和Quantum InfiniBand交换机。


它涵盖了从CPU和GPU计算,到用于互连的不同类型的网络。这是芯片到机架和互连,而不仅仅是GPU。它是有史以来单个GPU所拥有的最强AI计算、内存带宽和互连带宽。通过使用高带宽接口(NV-HBI),可在两个GPU芯片之间提供10TB/s的带宽。
此外,英伟达还引入了新的FP4和FP6精度。降低计算精度是提高性能的一种众所周知的方法。通过英伟达的Quasar量化系统,可以找出哪些方面可以使用较低的精度,从而减少计算和存储。英伟达表示,用于推理的FP4在某些情况下可以接近BF16性能。

NVLink交换机芯片和NVLink交换机托盘(tray)旨在以更低的功耗推送大量数据。英伟达演示了GB200 NVL72和NVL36。其中,NVL72包含36个Grace GPU和72个Blackwell GPU,专为万亿参数AI而设计。GB200 NVL 72作为一个统一系统,对大语言模型(LLM)推理性能提升高达30倍,释放了实时运行数万亿个参数模型的能力。
英伟达表示,随着AI模型尺寸的增加,在多个GPU上拆分工作负载势在必行。而Blackwell足够强大,可以在一个GPU中处理专家模型。

英伟达还展示了2024年至2028年的产品路线图。2026年的1.6T ConnectX-9似乎表明了英伟达对PCIe Gen7的需求,因为PCIe Gen6 x16无法处理1.6T的网络连接。
02
IBM:下一代 AI 加速器,Telum II
2021 年,IBM推出了IBM Telum 处理器,这是 IBM 首款用于推理的先进处理器芯片 AI 加速器。Telum 处理器实现业务成果的能力一直是 IBM z16大型机计划成功的关键驱动因素。随着客户需求的发展,IBM 不断创新并突破新兴技术的极限。

在今年的Hot Chips 2024大会上,IBM 宣布推出面向 AI 时代的下一代企业计算,即 IBM Telum II 处理器和 IBM Spyre Accelerator 预览版。预计两者将于 2025 年上市。
采用三星 5nm 技术开发的全新 IBM Telum II 处理器将配备八个高性能核心,运行频率为 5.5GHz。Telum II 的片上缓存容量将增加 40%,虚拟 L3 和虚拟 L4 分别增加到 360MB 和 2.88GB。该处理器集成了专门用于 IO 加速的全新数据处理单元 (DPU) 和下一代片上 AI 加速。这些硬件增强旨在为客户提供比前几代产品显著的性能改进。

每个加速器的计算能力预计将提高 4 倍,达到每秒 24 万亿次运算 (TOPS)。但仅凭 TOPS 并不能说明全部情况。这完全取决于加速器的架构设计以及位于加速器之上的 AI 生态系统的优化。当谈到生产企业工作负载中的 AI 加速时,适合用途的架构至关重要。Telum II 旨在使模型运行时能够与最苛刻的企业工作负载并驾齐驱,同时提供高量、低延迟推理。此外,还增加了对 INT8 作为数据类型的支持,以增强首选 INT8 的应用程序的计算能力和效率,从而支持使用较新的模型。
还加入了新的计算原语,以更好地支持加速器内的大型语言模型。它们旨在支持越来越广泛的 AI 模型,以便对结构化数据和文本数据进行全面分析。
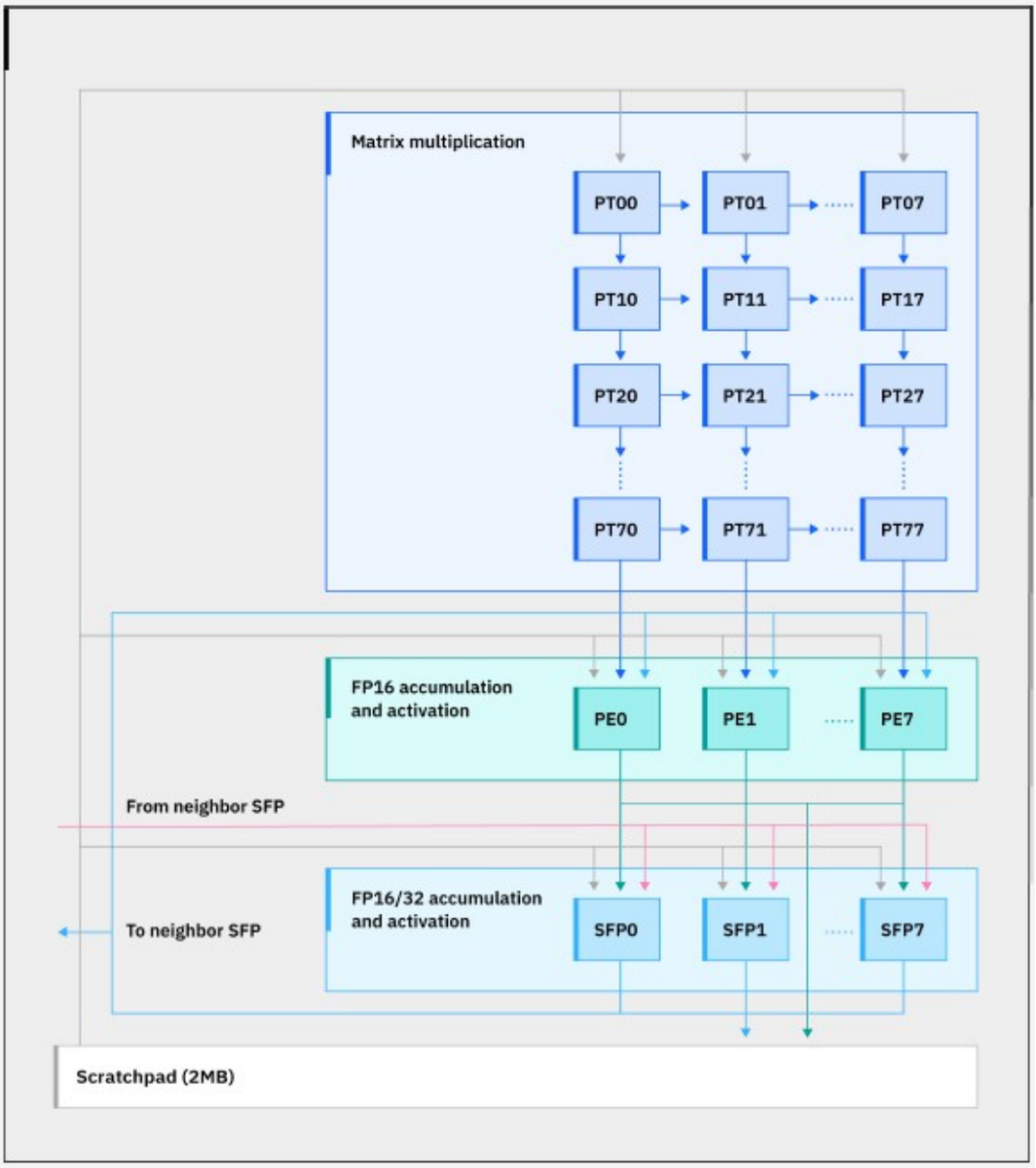
Spyre 核心的框图
在 Hot Chips 2024 上,IBM 还展示了 IBM Spyre 加速器,它是与 IBM Research 和 IBM Infrastructure Development 联合开发的。Spyre 加速器将包含 32 个 AI 加速器核心,这些核心将与集成在 Telum II 芯片中的 AI 加速器共享类似的架构。多个 IBM Spyre 加速器可以通过 PCIe 连接到 IBM Z 的 I/O 子系统中。将这两种技术结合起来可以大幅增加可用的加速量。

Spyre 加速卡的外观
Spyre 芯片上有一个 32 字节双向环连接 32 个内核(我们认为是 34 个内核,但只有 32 个处于活动状态),还有一个单独的 128 字节环连接与内核相关的暂存器内存。内核支持 INT4、INT8、FP8 和 FP16 数据类型。
03
英特尔:下一代英特尔至强 6 SoC、Lunar Lake 客户端处理器
在 Hot Chips 2024 上,英特尔发表了四篇技术论文,重点介绍了英特尔至强 6 SoC、Lunar Lake 客户端处理器、英特尔 Gaudi 3 AI 加速器和 OCI 芯片组。



英特尔至强 6 SoC 将英特尔至强 6 处理器的计算芯片组与基于intel 4 工艺技术构建的边缘优化 I/O 芯片组相结合。与之前的技术相比,这使 SoC 在性能、能效和晶体管密度方面实现了显著提升。其他功能包括:
最多 32 条通道 PCI Express (PCIe) 5.0。
最多 16 条通道 Compute Express Link (CXL) 2.0。
2x100G 以太网。
兼容 BGA 封装中的四个和八个内存通道。
lEdge 特定的增强功能,包括扩展的工作温度范围和工业级可靠性,使其成为高性能坚固设备的理想选择。

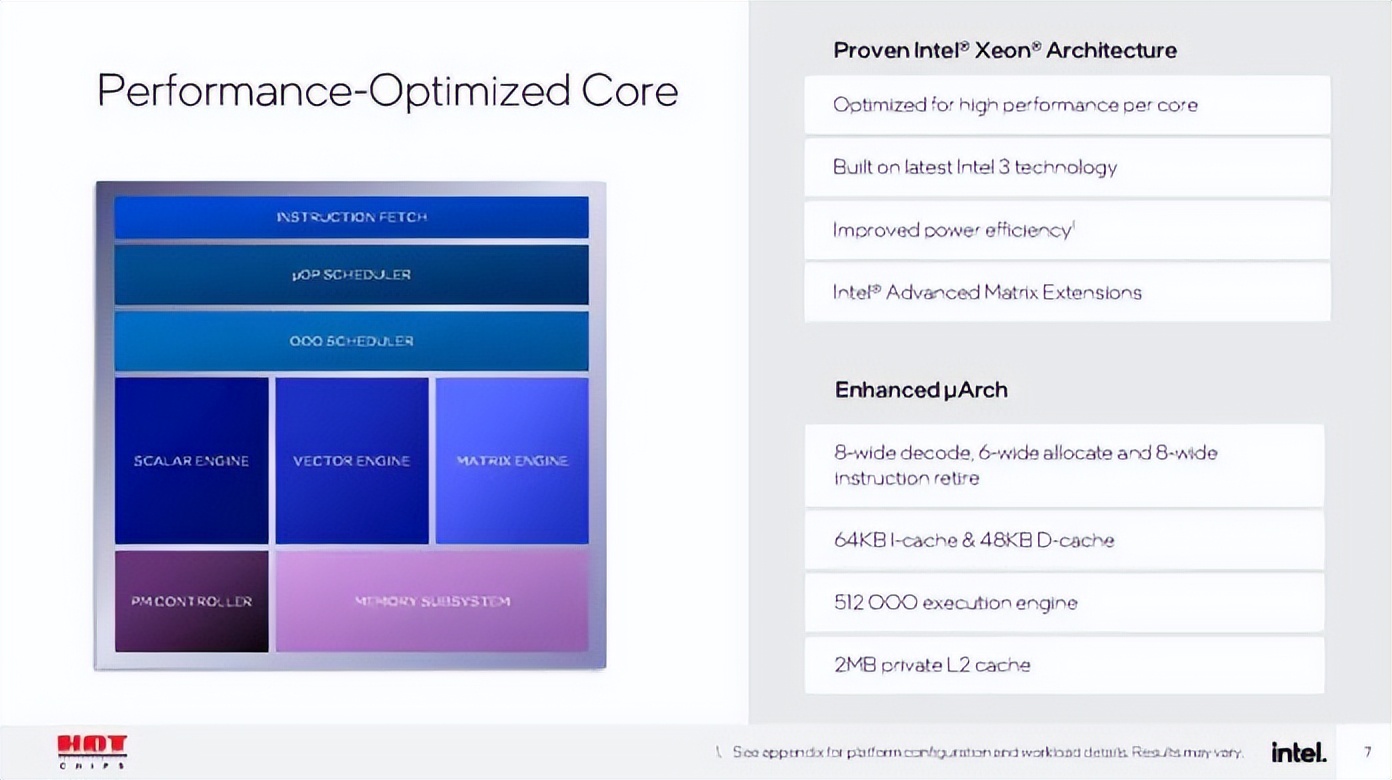

英特尔至强 6 SoC 还包括旨在提高边缘和网络工作负载性能和效率的功能,其中包括新媒体加速,可增强实时 OTT、VOD 和广播媒体的视频转码和分析;英特尔高级矢量扩展和英特尔高级矩阵扩展,可提高推理性能;英特尔QuickAssist 技术,可实现更高效的网络和存储性能;英特尔 vRAN Boost,可降低虚拟化 RAN 的功耗;并支持英特尔Tiber 边缘平台,让用户能够以类似云的简便性在标准硬件上构建、部署、运行、管理和扩展边缘和人工智能解决方案。
Lunar Lake 客户端处理器。与上一代相比,新的性能核心 (P 核心) 和高效核心 (E 核心) 可提供惊人的性能,而系统级芯片功耗降低了 40%。与上一代相比,新的神经处理单元速度提高了 4 倍,从而实现了生成式 AI (GenAI) 的相应改进。此外,新的 X e 2 图形处理单元核心将游戏和图形性能提高了 1.5 倍。有关 Lunar Lake 的更多详细信息将于9 月 3 日在英特尔酷睿超极本发布会期间公布。
英特尔 Gaudi 3 AI 加速器。人工智能加速器首席架构师 Roman Kaplan 介绍了需要大量计算能力的生成式人工智能模型的训练和部署。随着系统规模的扩大(从单个节点扩展到庞大的数千个节点集群),这会带来巨大的成本和功耗挑战。
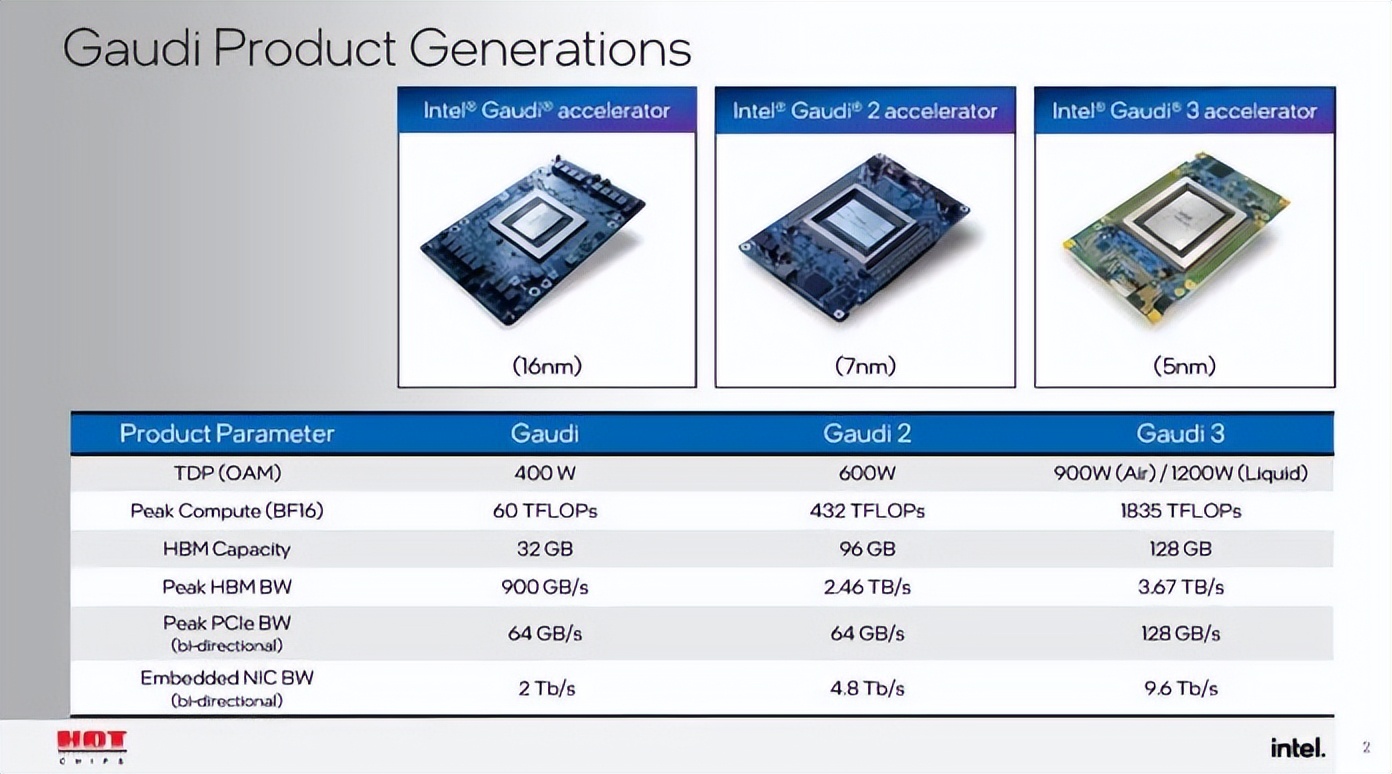

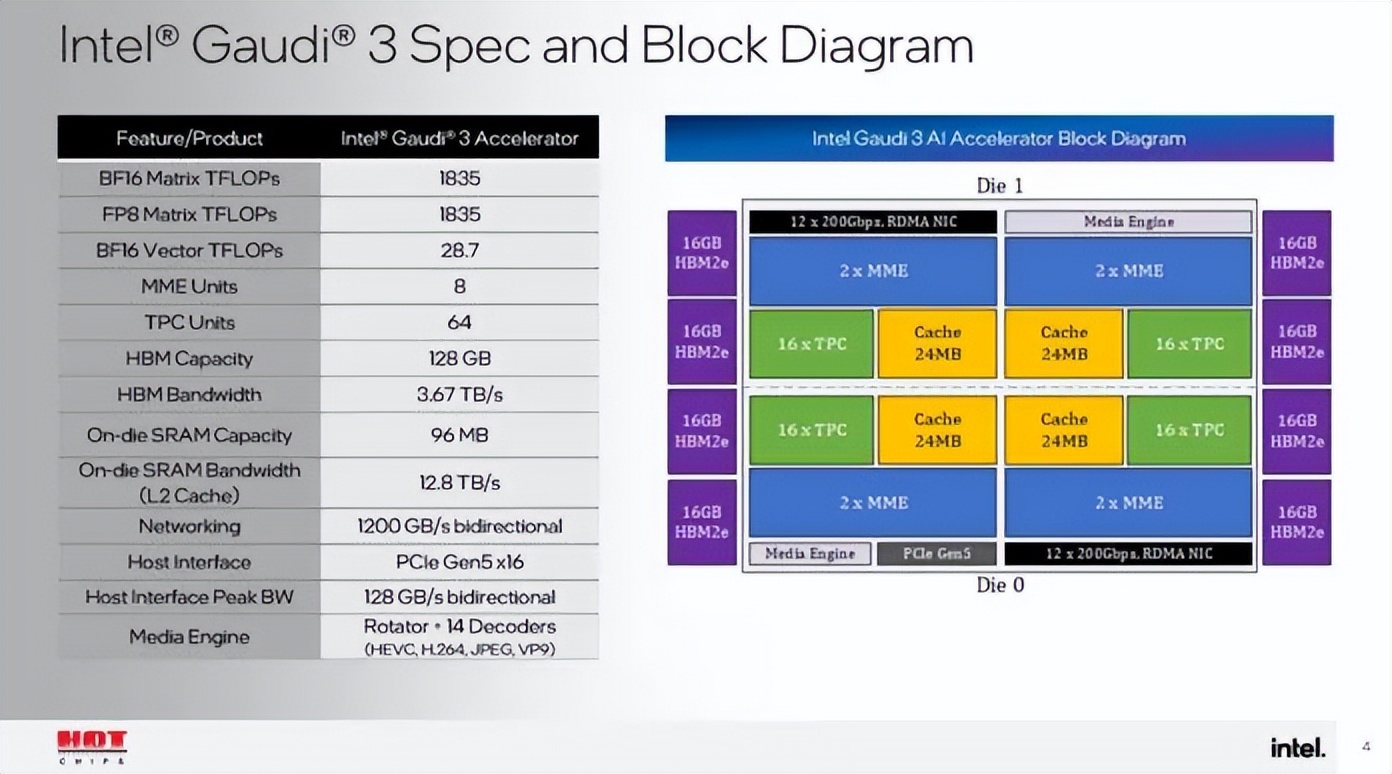

英特尔 Gaudi 3 OAM 工作示例包
英特尔 Gaudi 3 AI 加速器通过优化计算、内存和网络架构来解决这些问题,同时采用高效矩阵乘法引擎、两级缓存集成和广泛的 RoCE(融合以太网上的 RDMA)网络等策略。这使 Gaudi 3 AI 加速器能够实现显著的性能和能效,使 AI 数据中心能够更经济高效、更可持续地运行,解决部署 GenAI 工作负载时的可扩展性问题。
04
AMD:Zen 5 核心架构解析
在 Hot Chips 上,AMD 深入介绍了其全新的 Zen 5 核心架构,该架构将为其下一次高性能 PC 之旅提供动力。
AMD 的 Zen 1 核心架构于 2017 年首次推出,此后,该公司推出了五种新架构(Zen+、Zen 2、Zen 3、Zen 4、Zen 5)。AMD 在本世纪初推出了 Zen 3 架构,该架构在利用 7nm/6nm 工艺技术的同时,将 IPC 提高了 19%,具有 8 核复合体,并增加了每个 CCX 的 L3 缓存。
该公司随后发布了 Zen 4,带来了另外 14% 的 IPC 改进、AVX-512(FP-256)指令、将 L2 缓存增加一倍至 1 MB、支持 VNNI/BFLOAT16 并采用 5nm 和 4nm 工艺技术。

今年,AMD 推出了其最新的高性能核心架构 Zen 5,该架构通过 AVX-512 和 FP-512 变体将 IPC 提升了 16%,具有 8 宽调度、6 个 ALU、双管道提取/解码和 4nm/3nm 技术利用率。今天,AMD 正在 Hot Chips 上深入研究其 Zen 5 的完整架构。
AMD 首先阐述了 Zen 5 的设计目标。在性能方面,Zen 5 旨在实现 1T 和 NT 性能的又一次重大提升,平衡跨核 1T/NT 指令和数据量,创建前端并行性,提高执行并行性,提高量,实现高效的数据移动和预取,并支持 AVX512/FP512 数据路径以提高量和 AI。同时,AMD 希望通过其 Zen 5 和 Zen 5C 核心变体添加新功能,例如额外的 ISA 扩展和新的安全功能,以及扩展平台支持。
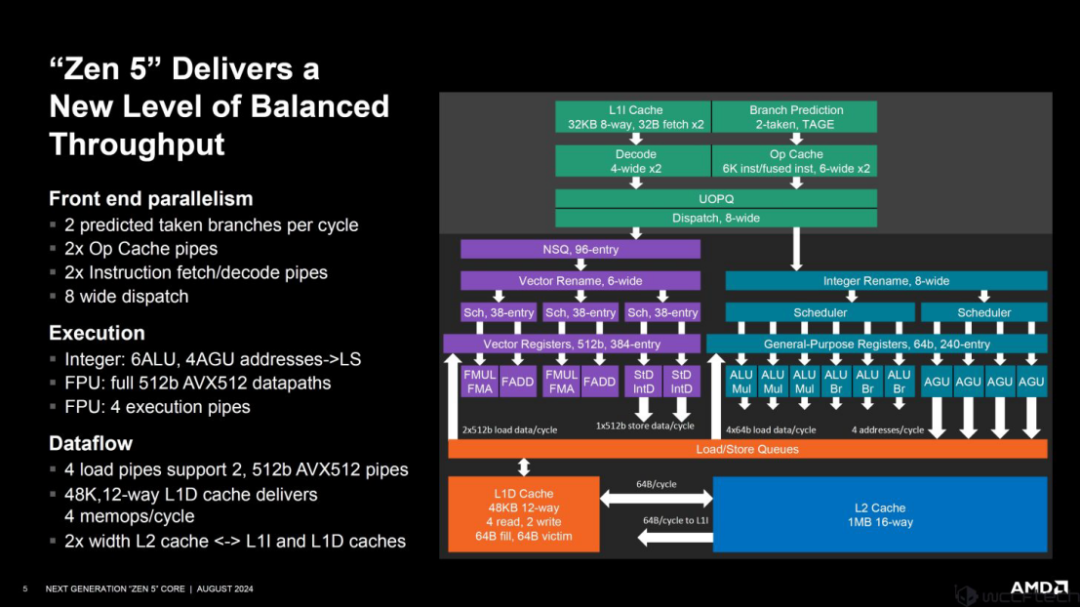
产品方面,AMD 的 Zen 5 核心将在三轮产品中率先亮相,包括 Ryzen 9000 “Granite Ridge” 台式机 CPU、Ryzen AI 300 “Strix” 笔记本电脑 CPU 和第五代 EPYC "Turin" 数据中心 CPU。
总而言之,AMD 表示 Zen 5 再次以大幅提升性能的节奏交付,AVX512 具有 512 位 FP 数据路径,可提高量和 AI 性能。高效、高性能、可扩展的可配置解决方案:Zen 5 可实现峰值性能,Zen 5c 可实现效率,支持 4nm 和 3nm 工艺节点。
05
高通:Oryon 核心解析
在 Hot Chips 2024 上,高通详细展示了骁龙 X Elite 中的 高通Oryon CPU。高通 Snapdragon X Elite 是该公司进军基于 Arm 的 PC SoC 的尝试。

高通Oryon 是该公司为 Snapdragon X Elite SoC 提供动力的 CPU。这是 Nuvia 团队基于 Arm 的核心。这里的集群是相同的,但出于功率目的,它们的运行方式不同。

高通重点关注的 CPU 核心领域包括指令获取单元 (IFU)、矢量执行单元 (VXU)、重命名和退出单元 (REU)、整数执行单元 (IXU)、内存管理单元 (MMU) 以及加载和存储单元 (LSU)。
以下是 Oryon 的提取和解码规格。13 周期分支预测错误延迟并非业界最佳,但高通表示,该设计已“平衡”。

矢量和标量引擎都具有类似的总体布局和物理寄存器文件。两者都有来自加载/存储单元的四个数据馈送,因此每个周期可以进行四次加载。相比之下,AMD 的 Zen 4 在整数方面每个周期只能处理三次加载,在矢量方面每个周期只能处理两次加载。

高通选择了分布式调度模型。虽然统一调度器有其优势,但拆分队列可以更轻松地选择最早就绪的指令。
Oryon 的加载/存储单元拥有大型 64 个条目保留站或调度器。核心的调度容量大于加载/存储队列容量,这与我们在其他架构中看到的情况相反。
高通指出,更大的调度器仍能满足时序要求,并缓解一些瓶颈。此外,调度器可以执行除加载/存储之外的其他操作(可能是存储数据操作),额外的容量有助于吸收这些操作。
Oryon 的 L1 数据缓存容量为 96 KB。它是多端口的,并使用代工厂的标准位单元设计。高通确实评估了使用更大数据缓存的可能性,但选择了 96 KB 的设计以满足时序(时钟速度)要求。
这是使用单线程的内存带宽图表。单核能够以略低于 100GB/s 的范围进行传输,考虑到 LPDDR5x 内存的 135GB/s 平台带宽,这非常了不起。
预取在任何现代核心中都扮演着重要角色。Oryon 特别强调预取,各种标准和专有预取器都会查看访问模式,并尝试在指令请求数据之前生成请求。高通通过使用各种访问模式测试软件可见的加载延迟来展示这一点。预取器拾取的模式具有较低的延迟。对于简单的线性访问模式,预取器运行得足够靠前,几乎可以完全隐藏 L2 延迟。
在系统层面,骁龙 X Elite 拥有 12 个内核,分为三个四核集群。之所以没有使用更大的内核集群,是因为在开发生命周期的早期,L2 互连不支持超过四个内核的集群。该功能后来被添加,但并未出现在骁龙 X Elite 中。之前有测试指出,在测试的笔记本电脑中,12 个内核受到功率和散热限制的严重限制。在与产品经理的对话中,他们表示,拥有 12 个内核让骁龙 X Elite 能够扩展到更高的功率目标,并在具有更好散热的设备中提供额外的多线程性能。该策略与英特尔和 AMD 形成鲜明对比,后者使用不同的内核数量来实现广泛的功率目标。
高通希望将 Oryon 的用途拓展到笔记本电脑以外的领域。
06
特斯拉:TTPoE,即特斯拉以太网传输协议
去年在 Hot Chips 2023 上,特斯拉推出了他们的 Dojo 超级计算机。对于特斯拉来说,机器学习专注于自动驾驶汽车等汽车应用,训练涉及视频,这可能需要大量的 IO 带宽。例如,对于公司的视觉应用,单个张量的大小可能为 1.7 GB。特斯拉发现,即使主机只是通过 PCIe 复制数据,他们的 Dojo 超级计算机的量也可能受到主机将数据推送到超级计算机的速度的限制。
特斯拉通过增加更多主机和将这些额外主机连接到超级计算机的廉价方式解决了这个问题。特斯拉没有使用像 Infiniband 这样的典型超级计算机网络解决方案,而是选择通过修改传输层来适应以太网的需求。TCP 被特斯拉以太网传输协议 (TTPoE) 取代。TTPoE 旨在提供微秒级延迟并允许简单的硬件卸载。较低级别的层保持不变,让协议在标准以太网交换机上运行。
TTPoE 的设计完全由硬件处理,并提供比标准 TCP 协议更好的延迟。因此,与 TCP 相比,TTPoE 的状态机大大简化。
通过消除 TCP 中的等待状态,可以减少延迟。在 TCP 中关闭连接涉及发送 FIN、等待该 FIN 的确认,并确认该确认。此后,连接进入 TIME WAIT 状态,这需要实现等待一段时间,允许任何无序数据包安全耗尽,然后新连接才能重用该端口。TTP 删除 TIME_WAIT 状态,并将关闭顺序从三次传输更改为两次。可以通过发送关闭操作码并接收确认来关闭 TTP 连接。Tesla 的目标是微秒级的延迟,因此即使是毫秒级的 TIME_WAIT 持续时间也可能导致严重问题。
TCP 以三向 SYN、SYN-ACK、ACK 握手打开连接。TTP 应用了与关闭端类似的优化,将握手更改为双向握手。同样,打开连接时传输次数越少,延迟就越低。这些简化的打开和关闭序列是在硬件中实现的,这也使其对软件透明。这意味着软件不必明确创建连接,而是可以告诉硬件它想要向哪个目的地发送数据或从哪个目的地接收数据。
与 TCP 一样,特斯拉使用数据包丢弃来进行拥塞控制。但由于 TTP 设计为在低延迟底层网络上运行,因此特斯拉能够采取蛮力方法解决问题。传统的 TCP 实现会维护一个滑动拥塞窗口,该窗口限制可以发送的未确认数据量。您可以将其视为网络中正在传输的流量。如果数据包得到及时确认,则拥塞窗口会扩大,从而增加带宽。如果数据包被丢弃并且在时间阈值内未收到确认,则拥塞窗口会迅速缩小。这让 TCP 能够优雅地处理各种不同的连接。带宽将在低延迟、低损耗的家庭本地网络中扩大,并自然地在与您的互联网服务提供商及其他网络的高延迟、高数据包丢失链接中缩小。
特斯拉不打算在开放互联网的低质量链路上运行 TTP,因此采取了强力拥塞控制方法。拥塞窗口不会根据数据包丢失进行缩放。硬件跟踪 SRAM 缓冲区中发送的数据,这定义了拥塞窗口大小。当缓冲区填满时,发送停止,数据包丢失通过重新传输 SRAM 缓冲区中保存的数据来处理。当相应的确认从另一端返回时,数据将从 SRAM 缓冲区中释放,从而自然地将滑动窗口向前移动。
特斯拉证明这种方法的合理性是,传统 TCP 拥塞控制算法(如 Reno)的工作时间尺度太长,因此对其 Dojo 超级计算机应用程序无效。
拥塞管理在每个端点上独立处理,这是 TCP 拥塞爱好者所熟悉的模型。Tesla 提到这一点主要是为了与其他低延迟网络(如 Infiniband)形成对比,在这些网络中,拥塞控制是在交换机级别处理的。Infiniband 使用在交换机级别控制的信用系统,不会丢弃数据包。如果端点用尽信用,它就会停止发送。TCP 和 TTP 通过简单地丢弃数据包来处理拥塞,从而消除了单独发送信用的需要,并降低了网络交换机的复杂性。
Tesla 在位于芯片和标准以太网硬件之间的硬件块中处理其 TTP 协议。此 MAC 硬件块由 CPU 架构师设计,并引入了许多 CPU 设计功能。演示者将其描述为像共享缓存一样,其中仲裁器在考虑排序风险的情况下在请求之间进行选择。
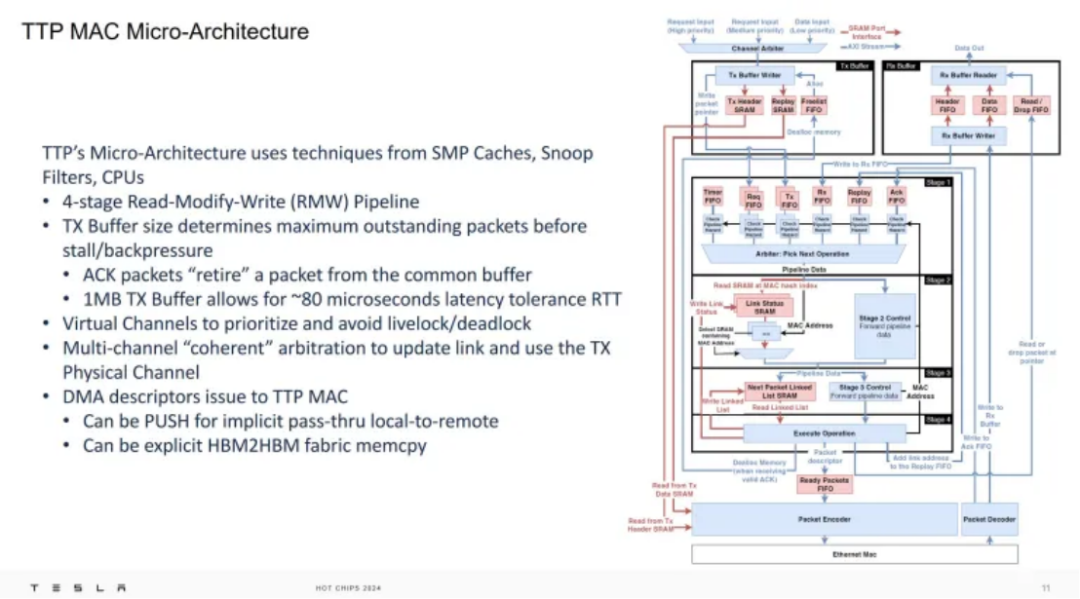
传输中的数据包在被确认后会按顺序“退出”,这种机制让人想起 CPU 从重新排序缓冲区按顺序退出指令。最突出的资源之一是 1 MB 传输 SRAM 缓冲区,它定义了上述拥塞窗口。特斯拉表示,这个大小足以容忍大约 80 微秒的网络延迟,而不会造成明显的带宽损失。根据利特尔定律,假设 1 MB 的传输数据和 80 微秒的延迟,则会产生 97.65Gbps。这刚好足以使 100 千兆位网络接口饱和。
TPP MAC 是在 Tesla 所谓的“Dumb-NIC”上实现的。NIC 代表“网络接口卡”。之所以被称为“Dumb”,是因为它尽可能便宜和简单。Tesla 希望部署大量主机节点来为他们的 Dojo 超级计算机提供数据,而廉价的网卡有助于以经济高效的方式实现这一目标。

除了 TPP MAC,Mojo 还集成了带有 PCIe Gen 3 x16 接口的主机芯片以及 8 GB 的 DDR4。PCIe Gen 3 和 DDR4 并非尖端技术,但有助于控制成本。Mojo 这个名字源于这样一种理念:额外的主机节点会为 Dojo 提供更多的 Mojo,从而保持高性能。
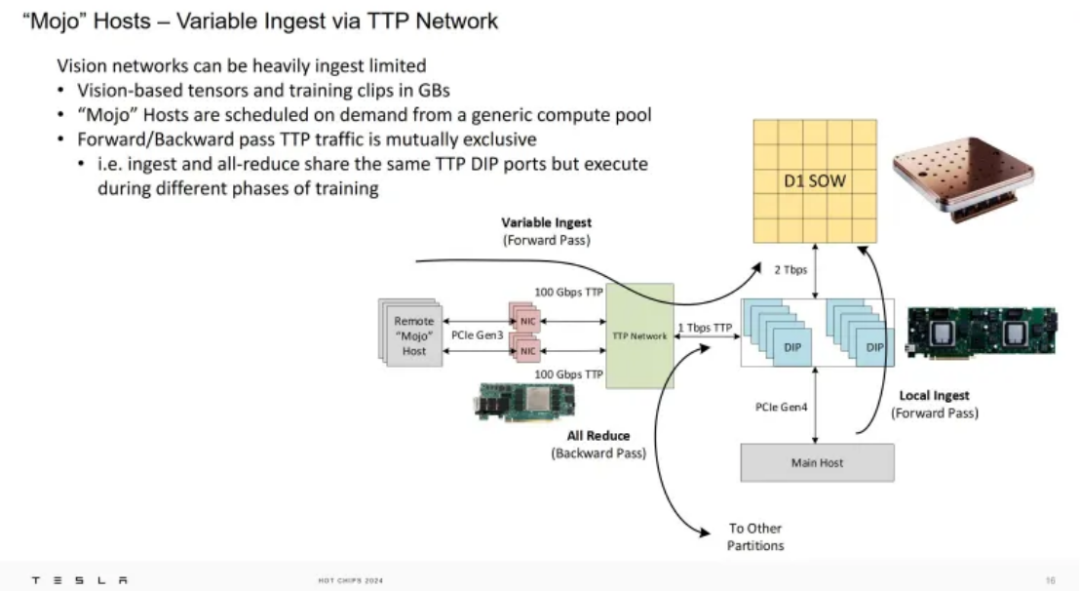
这些 Mojo 卡安装在远程主机上。当工程师需要更多带宽来将数据输入 Dojo 超级计算机时,可以从池中拉出远程主机。这些机器的额外带宽叠加在现有主机提供的入口带宽之上,这些主机使用去年 Hot Chips 会议上展示的更高成本接口处理器。
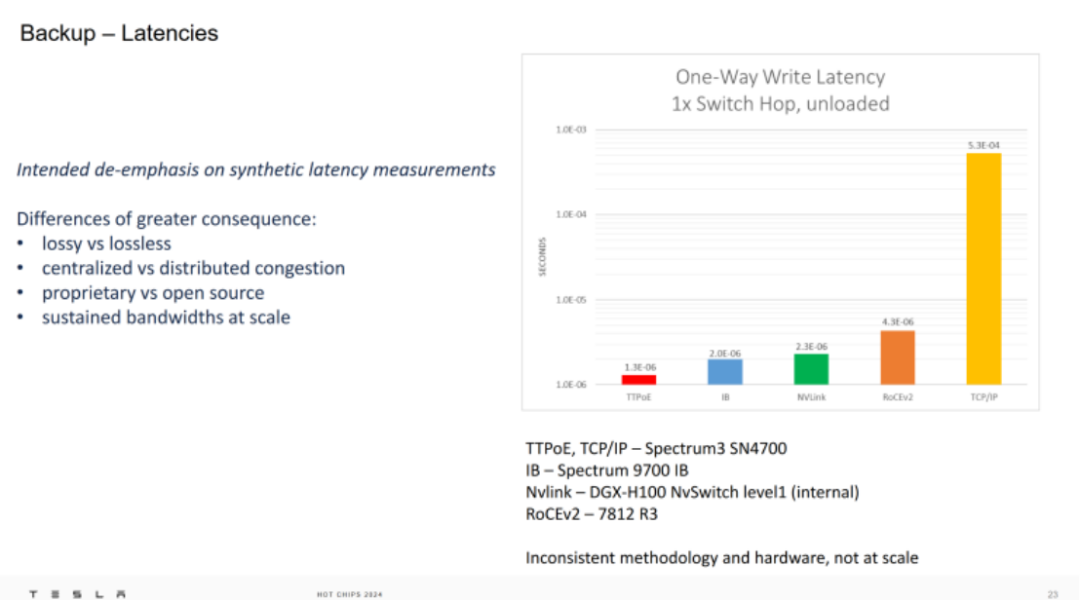
总体而言,Mojo 和 TTPoE 协议提供了一个有趣的视角,展示了如何简化众所周知的传输控制协议 (TCP),以用于更高质量的超级计算机内部网络。虽然该协议理论上可以在互联网上运行,但诸如固定拥塞窗口之类的简化在互联网服务提供商及其他低质量链路上效果不佳。
与 Infiniband 等其他超级计算网络解决方案相比,以太网上的自定义传输协议可能提供足够的额外带宽来满足 Dojo 的需求。
07
中国香山高性能 RISC-V 处理器亮相

“香山”开源高性能RISC-V处理器核源于中国科学院在2019年布局的“中国科学院先导战略专项”。作为该项目的承担单位,中国科学院计算技术研究所于2021年成功研制了第一代开源高性能RISC-V处理器核“香山(雁栖湖)”,是同期全球性能最高的开源处理器核。
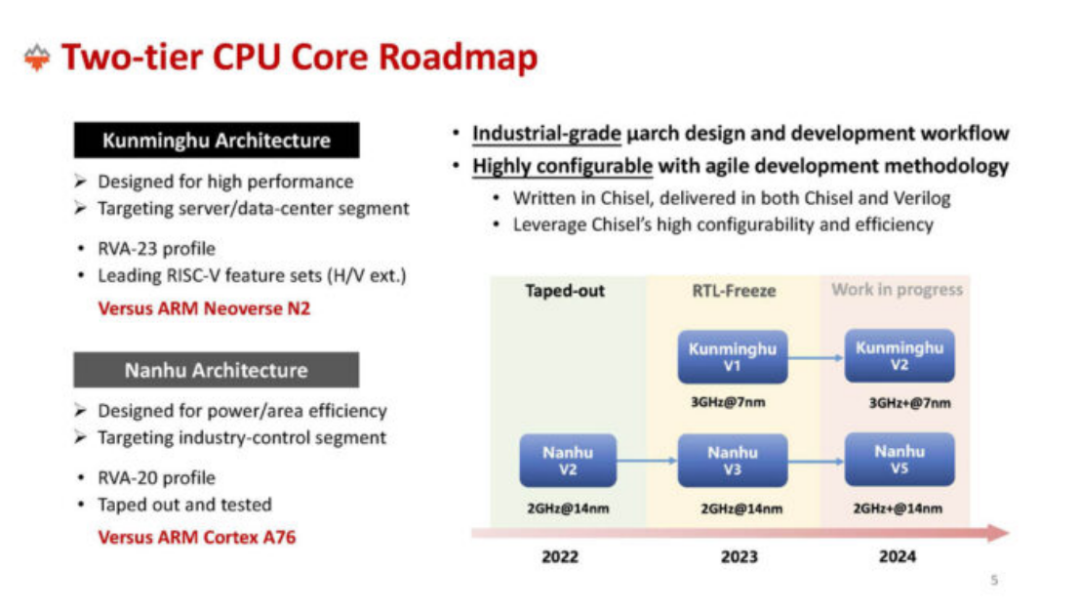
第二代“香山”(南湖)开源高性能RISC-V处理器核发布,是我国首款对标A76的高性能开源RISC-V处理器核。第三代“香山”(微架构代号是昆明湖)生产线瞄准的是 Arm Neoverse N2。
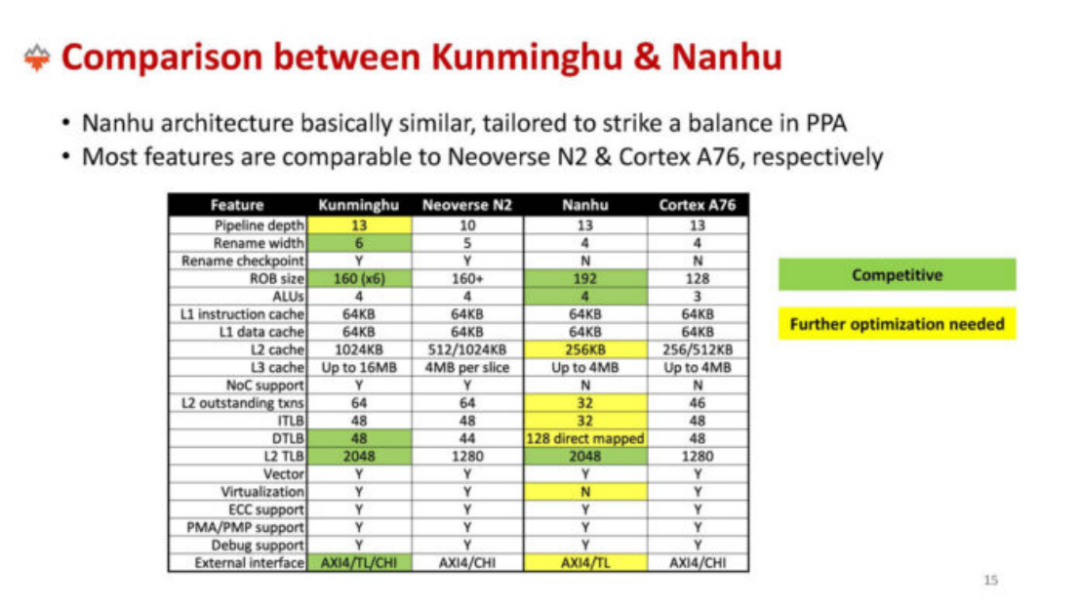
以上是“昆明湖”和“南湖”芯片与Arm Neoverse N2和 Arm Cortex A76 的比较。
本文作者可以追加内容哦 !

