
2011年的iPhone 4s发布会上,Siri以智能语音助手的身份初次亮相,成为整场发布会上最大的亮点。
当时许多人还未曾体验过Siri的服务,但从媒体报道中建立了一个朴实的愿望:就像《钢铁侠》中的贾维斯一样,每个人都将拥有自己的智能助手,可以实时沟通,帮助我们解决各种问题。
即使Siri后来“跌落神坛”,人们对于“贾维斯”的期望始终没有抹灭。AlphaGo、智能音箱、大模型……每一次现象级的创新背后,总有人在讨论:《钢铁侠》中的贾维斯,离我们的生活还有多远?
2024年大概率是愿望成真的一年。
7月末,OpenAI宣布向部分付费用户开放GPT-4o的视频通话版本,能够即时与GPT进行视频交互问答,通过摄像头识别画面,在线解答各种问题,比如实时翻译、解线性方程题等。
8月29日,智谱AI官宣智谱清言APP上线“视频通话”功能,成为首个可以通过文本、音频、图像和视频来进行多模态互动和实时推理的AI助手。目前已经向部分用户开放,并且开放了外部申请权限,将持续迭代并逐步放开规模。
由此产生的一个话题是:为什么头部的大模型厂商都在死磕“视频通话”功能,对用户体验有什么影响,“人手一个贾维斯”的愿望能否照进现实?
01 解锁AI新体验
大模型引发的新一轮技术热潮已经持续了近两年时间,市场上出现了形形色色的AI助手,人机交互却被“束缚”在了对话框中,停留在文本输入的阶段。某些产品推出了语音对话功能,但较高的延迟导致体验不佳,而且无法理解语调起伏、笑声等表达的情感信息,仅仅是用语音替代文本输入。
我们提前一天体验到了智谱清言APP的“视频通话”功能,在内测群里和其他进行了简单交流,发现了一些有趣的应用场景:
第一个场景是作业辅导。
不同于OpenAI发布会上演示的简单方程组解答,有群友直接将智谱清言用于孩子的作业辅导:
比如小学数学的互余角计算,智谱清言迅速理解了视频中题目的语义,并将问题进行了拆解,一步步引导孩子去计算,当孩子给出正确的答案后,智谱清言还在第一时间给出了“太棒了”的鼓励。
而在英语教学的场景中,孩子用笔在纸上圈出了某个单词,智谱清言精准识别到了圈住的词汇,并给出了正确的发音,甚至在孩子的朗读出现错误时,“耐心”地进行了读音矫正,就像是一个坐在孩子身边的“英语老师”。
第二个场景是产品介绍。
有时买到的商品是英文包装,可能看不懂使用说明和注意事项,是否可以用“视频通话”功能填补信息差呢?
我们将摄像头对准了星巴克买来的一款咖啡豆,因为存在折痕,一些英文字母出现了变形,但智谱清言依然准确识别出了商品信息,包括产品名称、配料、产地、风味、品牌等基础内容。
接下来询问了咖啡豆的制作和储存建议,即便是远远超出视频画面中的信息,智谱清言同样给出了确切的答案:做美式超合适,味道正好;保存咖啡豆要放在阴凉干燥的地方,避免受潮或晒太阳......
第三个场景是厨房助手。
因为每天中午都面临“吃什么”的烦恼,于是萌生了一个想法:让智谱清言识别菜品,并给出建议的菜谱和制作方法。
我们同时将白菜、干辣椒、大蒜和生姜放在案板上,然后询问都要哪些食材,可以用来做什么菜。没想到的是,智谱清言准确说出了每一种食材的种类,并给出了辣椒炒白菜的建议。
进一步询问应该怎么做,智谱清言详细给出了锅热加油、姜蒜炒香、加入红辣椒、香味出来后放切好的白菜等一整套流程。而当我们进一步询问“做醋溜白菜还需要哪些食材”时,智谱清言的答案再次让人惊艳:“做醋溜白菜的话,还需要点醋和糖”。
可以看到,上面的几个“小儿戏”并不能难倒智谱清言,比答案更重要的其实是整个问答的过程:不仅能够准确识别摄像头拍摄到的内容,听懂语音指令并准确执行,即使打断它也能迅速给出反应。相较于机械式的一问一答,在体验上越来越接近人与人的自然交流。
02 到底难在哪里
对智谱清言APP的“视频通话”功能做个总结的话,主要解决了三个痛点:
1、新的信息输入模式,不再局限于文字和语音,而是文本、图像、音频和视频等多个模态,AI可以自己“看世界”了;
2、新的对话交流模式,过去的对话交流大多是一问一答式的,合理但不符合真实习惯,现在已经可以做到“随时打断”;
3、新的人机交互场景,简单高于一切,视频和语音带来了近乎零门槛的用户教育,意味着人机交互可能迎来革命性更新。
上面提到的情景,曾不只一次出现在科幻电影中。除了前面提到的《钢铁侠》,《流浪地球》《Her》《银翼杀手2047》等电影中都有类似的桥段。因为最符合人类习惯的交互,从来都不是键盘,而是对话。
要实现“视频通话”功能,到底难在哪里呢?就大模型而言,必须要满足两个方面的能力要求。
首先是多模态能力。
简单来说,模态就是信息输入和输出的表现形式,包括文字、图像、语音、视频等等。为什么多模态能力重要呢?因为人类认识世界的方式本身就是多模态,眼睛、耳朵、嘴巴、手脚等承载了不同的信息感知,AI想要替代人类的工作,帮助人类学习、认识和理解这个世界,前提正是多模态数据处理能力。
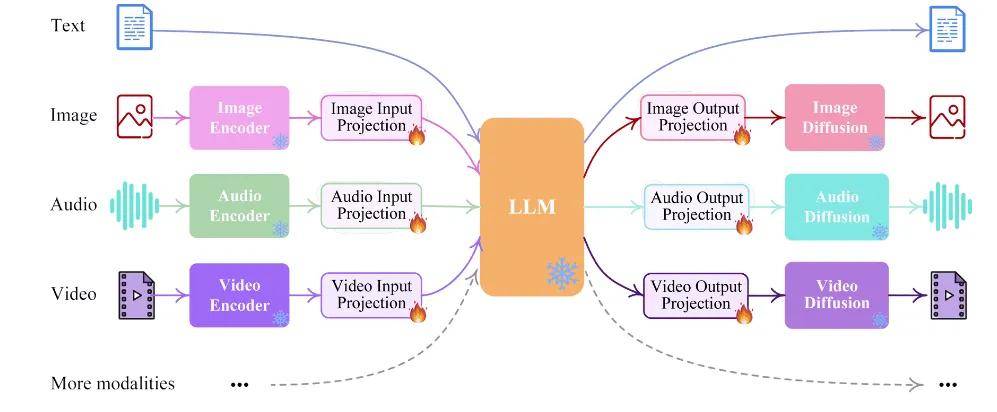
其次是模型推理速度。
人类对话的普遍间隔时间是250毫秒,偏离这个间隔越久,交互就越“不自然”,体验也就越“不爽”。目前大模型存在的问题在于:推理时长往往在3秒以上,直接影响了用户体验和业务效率。OpenAI曾公开GPT-4o的语音延迟数据,平均为 320 毫秒,智谱AI尚未公布详细数字,但实际体验和GPT-4o相当。
也就是说,大模型的竞争就是一场开卷考试,追求的目标一致,且路径逐渐清晰,比拼的其实是技术硬实力。
以智谱清言为例,之所以成为国内首个面向C端开放“视频通话”功能的产品,离不开两个核心优势:
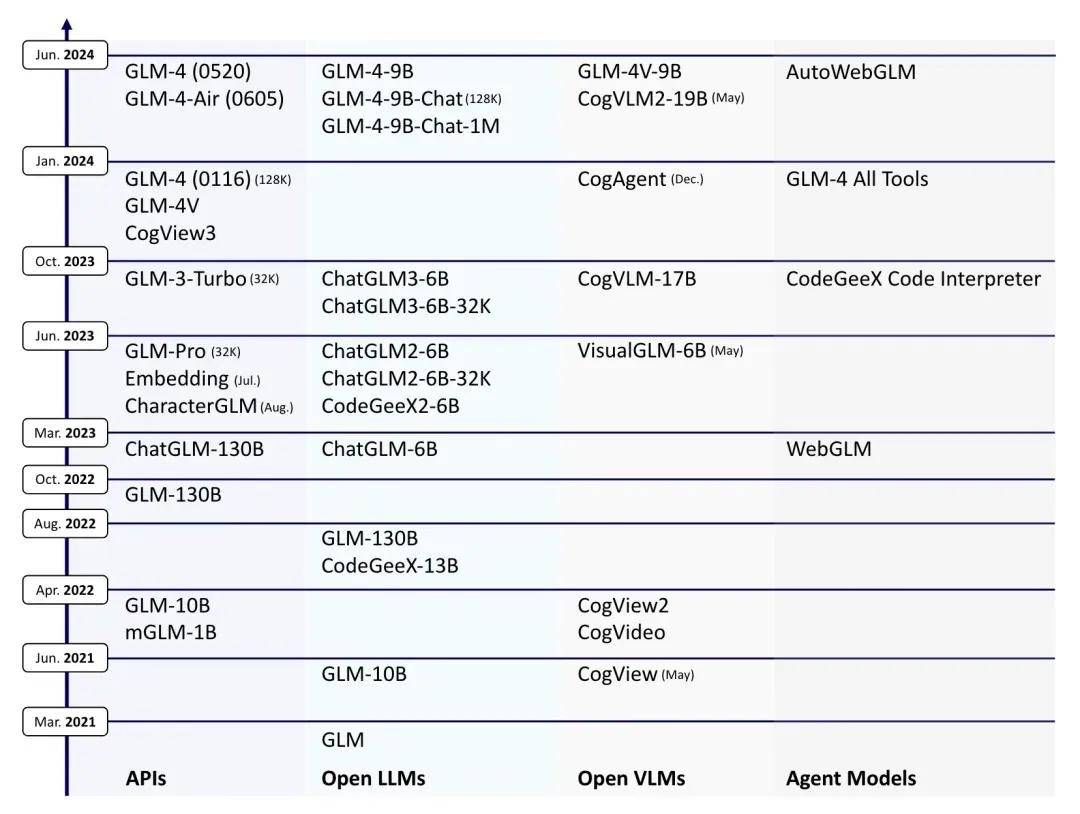
一个是时间上的先发优势。早在2021年3月,智谱AI团队就推出了GLM系列大模型,2021年5月推出了推出了将中文文字生成图像的文生图模型CogView,2022年在CogView2的基础上研发了视频生成模型CogVideo……超过国内同行近两个的时间优势,让智谱AI在多模态能力上有着更深的沉淀。
另一个是能力上的领先优势。比如智谱AI联合清华KEG潜心打磨的CogVLM-17B,在多个数据集上获得了SOTA或第二名的成绩;新推出的GLM-4V-Plus,在MVBench、LVBench、OCRBench、MMVET等多个基准测试中的表现超过GPT-4o和Gemini 1.5Pro,达到国际先进水平。
03 “盛宴”刚刚开始
也许在一些人眼中,“视频通话”不过是一项寻常的功能创新,放诸到商业语境里,却有着不可小觑的作用。和每一次风口出现时一样,大模型的概念刚走红时,创业者们一窝蜂地涌入,试图在新一轮的创业潮中搏一个机会。可直到现在,市场上还没有跑出一款真正意义上的杀手级产品。
不少人将ChatGPT的走红视作“AI的iPhone时刻”,可初代iPhone的销量只有700万台,并未改写诺基亚统治市场的格局;让无数开发者从中获利的App Store,则要追溯到2008年发布的iPhone 3G。
初代iPhone的“历史价值”,其实是电容屏和多点触控。

诺基亚和摩托罗拉也曾推出多“大屏”手机,但采用的是电阻屏,需要用触控笔才能操作,导致使用门槛高且场景有限。相比之下,多点触控的电容屏允许用户直接用手指操作、输入和互动,极大地降低了用户的学习成本,赋予了开发者更大的想象空间,进而才有了移动互联网的繁荣。
沿循这样的逻辑,“对话框”就像是电阻屏,“视频通话”功能让大模型的人机交互进化到了电容屏时代。
个中差别并不难解释。
作为一个深度使用大模型能力的普通用户,之前我们的需求主要集中在文本生成、图像生成和视频生成,比如让AI写简单的视频脚本、生成文章配图和视频素材,核心场景并未脱离“工作”的范畴。
体验了智谱清言的“视频通话”功能后,我们深切地感受到:多模态能力和毫秒级的推理速度,在生活中有着无处不在的应用场景,比如出国旅游时打开摄像头将餐厅的菜单翻译成中文、工作面试前让AI扮演面试官提前模拟面试、早上出门时打开视频询问今天的穿着怎么样、吃零食前先让AI识别计算卡路里……对应的生活场景不可计数。

对于开发者而言,“卷模型还是卷应用”的争论有了确切的答案:大模型打破能力上的枷锁后,开发者可以在更多场景中开发有价值的应用。
譬如我们曾走访过一家工业企业,为了解决大型机械设备的维修问题,这家企业采用了AR眼镜+远程工程师的模式,即由当地工作人员戴着AR眼镜采集实时数据,后端的维修工程师进行远程指导,在一定程度上节约了工程师的差旅和时间成本,但培养一个工程师的时间成本近乎无解。
现在无疑有了新的解法:这家企业可以将工程师的经验和知识用于训练专有大模型,然后通过“视频通话”功能为现场员工赋能,在AI的指导下一步步解决问题,每个人都能拥有资深工程师的能力。
把思维再发散一些的话,几乎所有的场景,都可以利用“视频通话”能力重新做一遍,包括但不限于作业辅导、英语家教、景区导览、数字客服等等,等待开发者的不再是同质化竞争的局面,而是深入一个场景做深做实。
当想象力不再被制约的时候,就是价值加速变现的拐点,也是大模型盛宴开场的积极信号。
04 写在最后
年初的一场演讲上,智谱AI CEO张鹏曾断言:2024年一定是AGI元年,而多模态是AGI的一个起点。
2024年已经过去三分之二,回头再来审视张鹏的判断,正一步步被验证。同时也意味着,大模型行业的演进正走在一条可预见的道路上,不断在图文的基础上融合听觉、视觉等模态的认知能力,加速迈向AGI时代。
本文作者可以追加内容哦 !

