
文 / 道哥
“AI具备思维了么? ”“AI应该具备怎样的思维能力? ”这是一直以来科技界频繁探讨并力主攻克的难题。
自从 OpenAI 发布新模型 o1-preview后,这道难题大致有了解法:
有人用门萨(MENSA)测试题“拷问”o1-preview,被它120分的智商震惊到合不拢嘴;
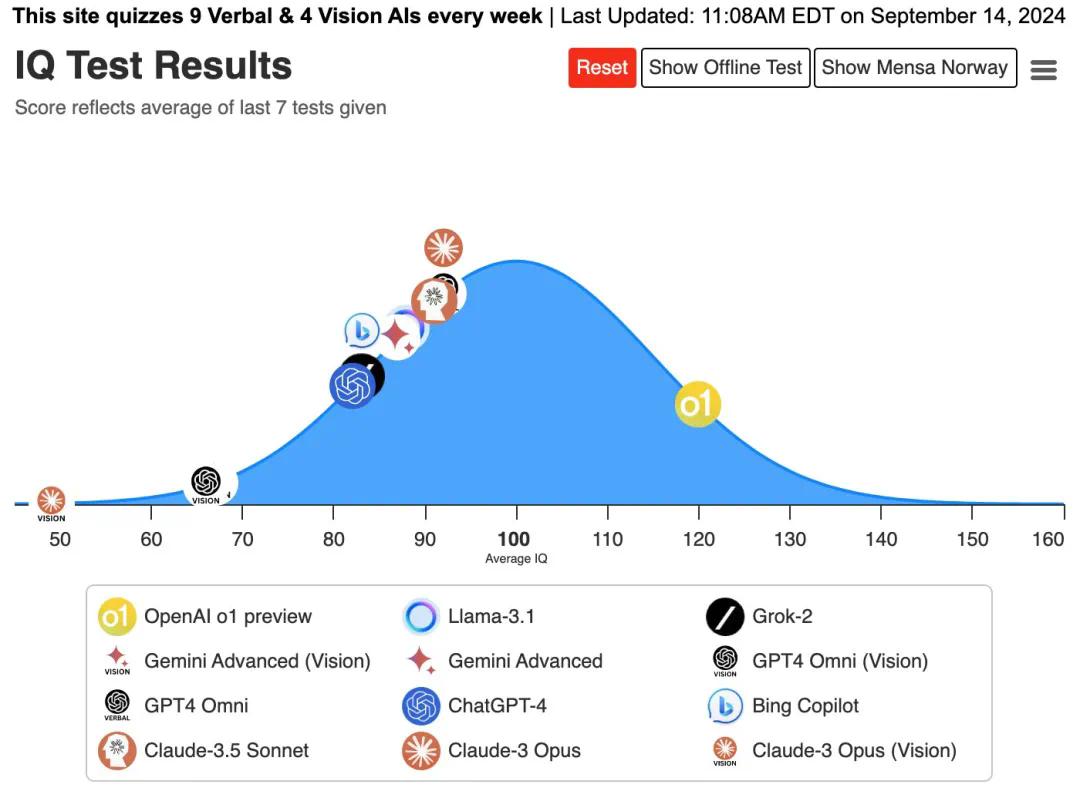
数学大佬陶哲轩在和o1-preview碰触后,发现它竟然能成功识别出克莱姆定理;
一位天体物理学论文作者,仅用6次Prompt,就让 o1-preview在1小时内,创建了代码运行版本,相当于他博士生期间10个月的工作量。
……
换言之, o1-preview已经具备了思维能力,甚至可以“三思而后行”。
据了解,o1-preview和GPT系列模型最大的区别在于,o1-preview是在思考之后解答用户问题,输出高质量的内容,而非迅速回应无效答案,即用模仿人类思维过程的“慢思考”代替过去追求快速响应的“快思考”。
但其实,这种思想和方法并非OpenAI的首创,更非独创。早在7月底的ISC.AI2024大会上,360集团创始人周鸿祎就宣布,“用基于智能体的框架打造慢思考系统,从而增强大模型的慢思考能力”。
01 英雄所见略同
诚如前文所言,o1-preview之所以变得更强大、更聪明,其本质是用模仿人类思维过程的“慢思考”代替过去追求快速响应的“快思考”。
英雄所见略同。周鸿祎不仅早于OpenAI提出这一理念,且在之后多次强调类似理念。
对于o1-preview的推出,周鸿祎在其最新发布的短视频中表示,“o1-preview不同于以往大模型用文字来训练,而是像自己和自己下棋,通过强化学习来实现这种思维链的能力。”
在周鸿祎看来,人类思维有“快思考”和“慢思考”之分。快思考的特点是直觉敏锐、无意识,反应很快但精度不够。GPT类大模型汲取海量知识,主要学习的是快思考能力,这也是为什么它们能脱口而出,但常常答非所问、“胡说八道”的原因,“就像人一样,不假思索出口成章而不出错的概率很小。”
慢思考的特点则是缓慢、有意识、有逻辑性,需要分解成详细的步骤,好比写一篇复杂的文章,要先列提纲,再根据提纲去搜集资料和素材,然后讨论、撰写、润色和修改,直至定稿,“o1-preview拥有了人类慢思考的特质,在解惑答疑前会反复地琢磨、推敲,可能还会自我提问千遍,最后才给出结果。”
不过,尽管o1-preview在“慢思考”的加持下取得了令人惊喜的进展,但其仍然难称完美,尚存在幻觉、运行速度较慢、成本高昂等诸多“痼疾”,也限制了其应用范围。
对比之下,提前意识到“慢思考”对AI重要性的360,凭借着行业首发、全栈自研的CoE(Collaboration of Experts,专家协同)技术架构和混合大模型,在o1-preview推出之前就已实现应用落地。
据了解,360在今年7月底正式发布的CoE技术架构中,强化了“慢思考”的使用,驱动多个模型分工协同、并行工作,执行多步推理。
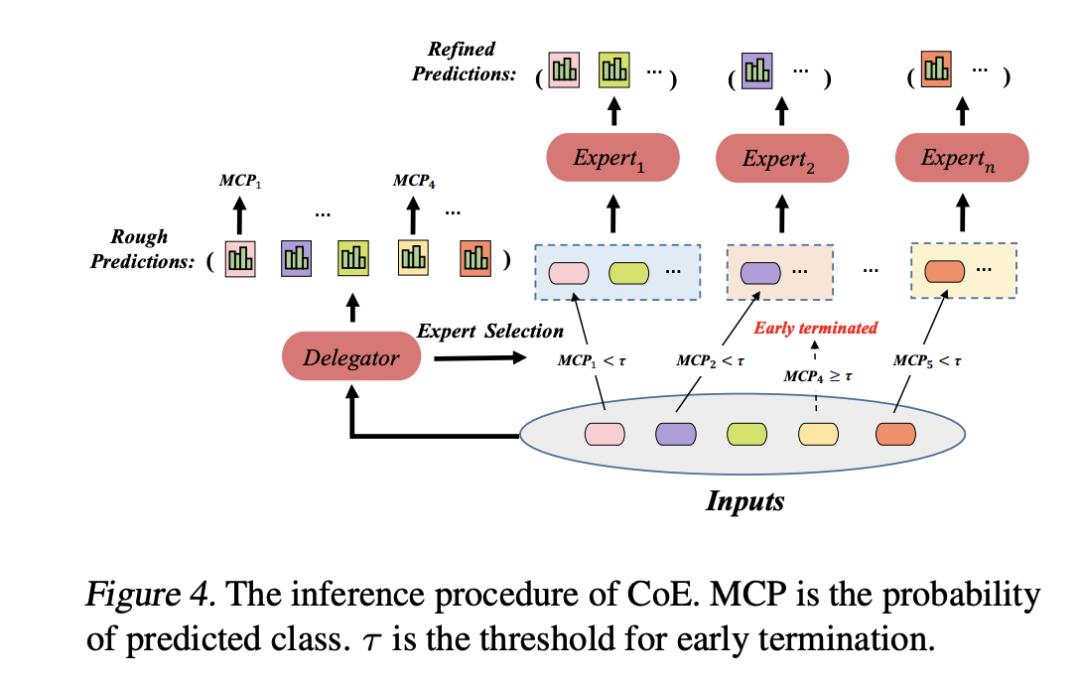
并且CoE技术架构带来更精细的分工、更好的鲁棒性、更高的效率和可解释性和更深的泛化性,能够加快推理速度,以及降低API接口和Token所需费用。
可以说,这一次,中美两国的人工智能企业在研发思路上罕见地站在了同一条起跑线,并且中国企业的起跑时间还要早一些。
02 集齐龙珠,召唤“神龙”
和同业选手显著区隔开的是,CoE技术架构并非只接入了一家企业的模型,而是由360牵头,百度、腾讯、阿里巴巴、智谱AI、Minimax、月之暗面等16家国内主流大模型厂商组成“联合舰队”。
同时,其还接入了很多十亿甚至更小参数的专家模型,让整个系统更加有的放矢,更具能动性、更加智能。
双管齐下的举措,使CoE技术架构轻松实现“量体裁衣”,达致资源、效用最大化:一边“集齐龙珠,召唤神龙”,让最强的模型啃最硬的“骨头”,一边调用更精准、更具特色的小模型,解决简单的浅层疑问。
目前,CoE架构作为底层支撑,已在360AI搜索、360AI浏览器等产品中落地。
360AI搜索的“深入回答”模式,涉及7-15次的大模型调用,比如可能会涉及1次意图识别模型调用,1次搜索词改写模型调用,5次搜索调用,1次网页排序调用,1次生成主回答调用,1次生成追问调用。
由此导向的工作链路分为三步,即首先构建意图分类模型,对用户的发问进行意图识别;接着打造任务路由模型拆解问题,划分成“简单任务”、“多步任务”和“复杂任务”,并对多个模型进行调度;最后构建AI工作流,使多个大模型协同运作。
这样一来,360 AI搜索不光考虑到了任务的动态性和复杂性,还能够根据任务的具体情况实时调整处理策略和资源分配,化解繁琐任务时更加灵活和高效。
03 组队较量,战力更强
360AI浏览器中,除了上线“多模型协作”,另一大亮点便是入驻了国内首个大模型竞技平台——模型竞技场。
“大模型竞技场”,同样支持调用国内16家主流大模型厂商的54款大模型,包括“组队较量”、“匿名比拼”、“随机对战”等功能,帮助用户在最短的时间获取最优解。
尤其是“组队较量”功能,用户可以自由选定3款大模型,和任意一款或两款大模型PK。
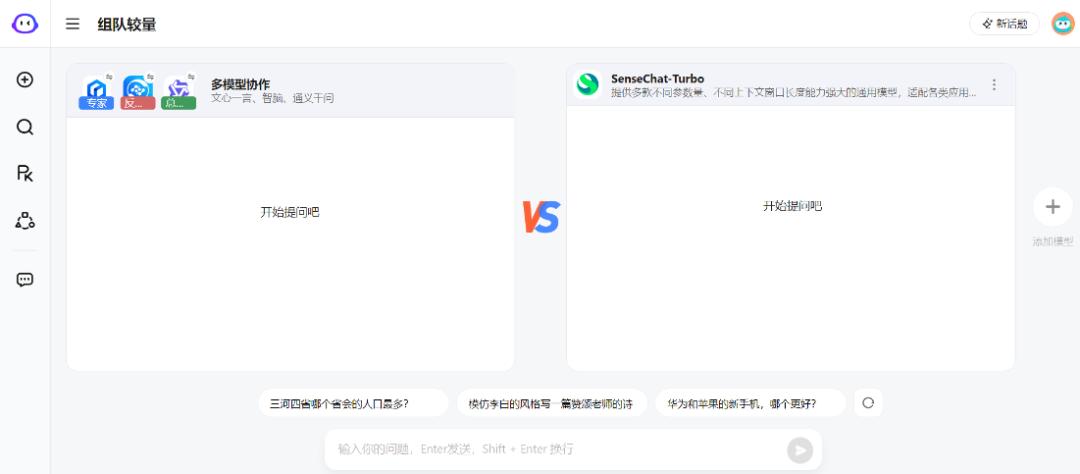
这么做的好处显而易见。多个大模型在同一时空激烈“赛马”,展开就速度、耗时、效率等多个维度的量化比拼或“秀肌肉”,对用户来说,交叉比证后,能更为直观地评估并裁夺出最佳方案。
事实上,当下不少国产大模型在单项指标上都能打平甚至完胜GPT-4,但论整体实力,差距就显现出来了。
CoE技术架构的思路,正是改变这种“单打独斗”的做法,构建大模型“精英集群”、“团战”打法,从而各取所长,形成“最强大脑”,迎战o1-preview和GPT-4o。
同时,在“比学赶帮超”的浓厚氛围中,碰撞出行业的一些集成标注,提高不同模型间的兼容性,升级用户体验。
尊因循果,得益于底座的整合创新,360混合大模型在翻译、写作、学科考试、代码生成等 12 项具体测评中取得了80.49分的综合成绩,大幅领先于GPT-4o的69.22分;特别是在“诗词赏析”、“吧”等这类比较具有中文特色的细分赛道,领先身位进一步扩大。
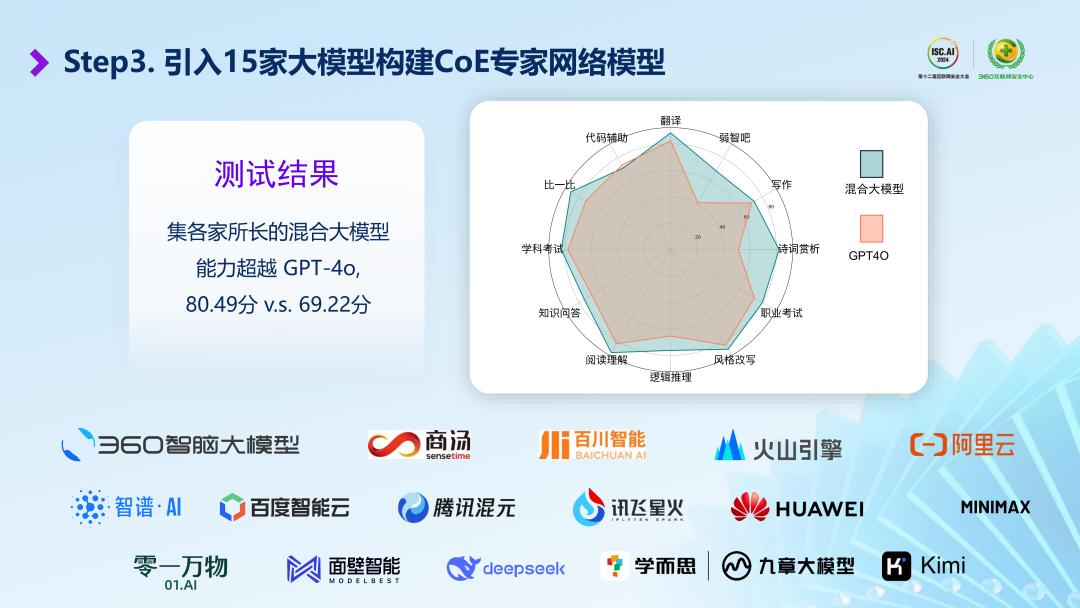
即便面对 o1-preview,360混合大模型在未经专门优化的情况下也展现出了能与之抗衡的力量。
经过21道复杂逻辑推理题测试结果显示,其效果与OpenAI o1-preview相当,完全超越GPT-4o,有时还能超越o1-preview。
可以说,CoE的整个流程就是在践行人类思维过程的“慢思考”,涵盖分析、理解、剖判等关键环节,内涵了愈发“类人”的倾向。
正如周鸿祎认为的,“模型知道什么时候自己不懂,然后找方法去‘查询’或‘验证’答案,而不是依赖模型自身储存所有知识。”
写在最后
在AI这条赛道上,“慢思考”无疑是人工智能发展到现在的一大突破。
长线看,“慢思考”更是角力AI赛道的“胜负手”。“以后比的不是多快能给你答案,而是给的答案完不完整,这也会改变人工智能服务的业态,人工智能到最后还是要参考人类大脑的组成来构造工作模式”,周鸿祎说。
360凭借前瞻性的技术洞察和笃行实干,寻获一条充满自主特色的AI发展路径。这一路径给中国的AI进程提供了新的思路,也使中国大模型厂商媲美甚至超越OpenAI成为可能。
本文作者可以追加内容哦 !

