在当今数字化时代,数字营销已成为企业获取用户、提升品牌影响力和促进销售增长的关键手段之一。然而,随着信息量的爆炸性增长和用户需求的日益多样化,如何精准地推送个性化内容,实现高效的用户触达,成为了数字营销领域亟待解决的问题。深度学习作为人工智能领域的一项重要技术,其强大的特征提取和模式识别能力为智能推荐系统带来了革命性的变革,极大地提升了数字营销的效果。本文将从用户数据采集、典型深度学习模型特征处理方式以及项目实践介绍及效果指标三个方面,深入探讨深度学习模型如何助力智能推荐,进而提升数字营销效果。
1. 用户数据采集
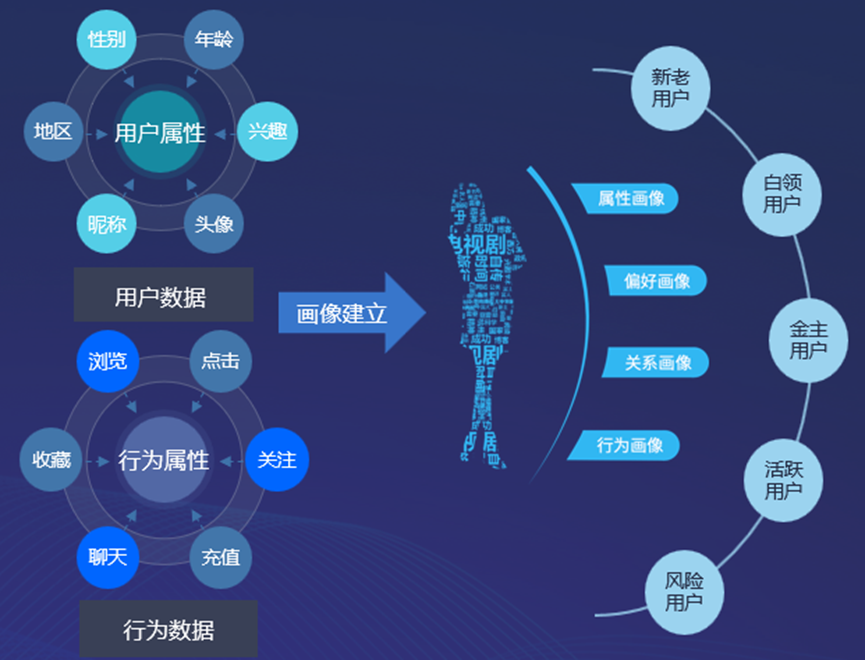
达观推荐系统通过高效、灵活的数据接入机制,实现了对海量数据的全面整合与利用。这一过程中,数据接入不仅涵盖了系统内置的标准化字段,如用户ID、商品ID、行为类型(如点击、购买、浏览等)、时间戳等,还允许用户根据实际需求自定义添加字段,以增强数据的丰富性和个性化。
1.1 数据来源与类型
在智能推荐系统的构建过程中,用户数据是至关重要的资源。数据来源多样,包括但不限于用户行为日志、社交媒体互动、交易记录等。这些数据类型涵盖了用户的显式反馈(如评分、购买历史)和隐式反馈(如浏览时间、点击率),为深度学习模型提供了丰富的信息。采集用户的行为主要目的是为了以数据的视角观察用户是怎么在你的产品里“活动”的,为了帮助设计者了解设计的缺陷,优化交互设计,提高产品的体验。
用户行为日志:通过分析用户的点击、搜索、购买等行为,可以捕捉到用户的兴趣偏好和购买意图。例如,电商平台的日志数据可以揭示用户的购物习惯和偏好。
社交媒体互动:用户在社交媒体上的点赞、评论、分享等行为反映了用户的情感倾向和社交关系,这些信息对于理解用户需求和优化推荐策略具有重要价值。
交易记录:用户的购买记录提供了用户偏好的直接证据,通过分析购买频率、购买类别、购买时间等信息,可以构建用户的消费画像。
用户属性数据:如年龄、性别、地域、职业等基本信息,为推荐系统提供了用户画像的基础。
1.2 数据预处理
数据预处理是深度学习模型训练的基础,它包括数据清洗、缺失值处理、异常值检测等步骤。。
数据清洗:去除数据集中的噪声和不一致性,例如去除重复记录、纠正错误的数据条目、标准化文本数据等。
缺失值处理:对于缺失的数据,可以采用填充(如使用均值、中位数)、删除(如删除含有缺失值的记录)或预测(如使用其他数据预测缺失值)等方法。
2. 典型深度学习模型特征处理方式
在推荐系统中,模型特征处理是连接原始数据与推荐算法之间的重要桥梁。达观推荐系统内置的几十种模型,每一种都经过精心设计,以应对不同场景下的推荐需求。这些模型之所以能够有效提升推荐精准度,关键在于其背后强大的模型特征处理功能。
2.1 DLRM
DLRM(Deep Learning Recommendation Model)是一种深度学习推荐模型,由Facebook在2019年提出。DLRM模型在特征处理方面有以下几个关键点:
离散特征处理:对于类别型的离散特征,DLRM通过one-hot编码转换成高维稀疏特征,然后使用Embedding层将这些稀疏特征映射成稠密的向量表示,便于神经网络处理和学习。这一过程可以量化为矩阵乘法,其中one-hot编码后的向量与Embedding矩阵相乘,得到embedding向量。
连续特征处理:对于数值型的连续特征,DLRM使用多层感知机(MLP)进行处理,将连续特征映射到与离散特征相同维度的嵌入向量。
特征交叉:DLRM模型中的交互层(interaction layer)通过点积操作实现特征的交叉,类似于FM算法中的操作,这样可以捕捉特征间的二阶交互。
特征表示:DLRM模型使用Embedding层处理稀疏特征,并通过MLP处理连续特征,然后显式考虑这些特征的交互,最后使用一个MLP预测事件概率。
并行计算:由于稀疏特征的Embedding会产生大量参数,DLRM采用模型并行和数据并行来处理这些参数,以提高计算效率。
优化点:DLRM在特征处理上,对于离散特征通过one-hot编码和Embedding层转换,对于连续特征则通过MLP转换。在特征交叉上,通过MLP神经网络层对Embedding层输出的特征进行进一步的转换和组合,实现特征的交叉。
DLRM模型的这些特征处理方式使其能够有效地从输入数据中提取有用的信息,并根据用户和物品的交互模式进行推荐,从而在实际应用中取得了显著的推荐效果。
2.2 DIN
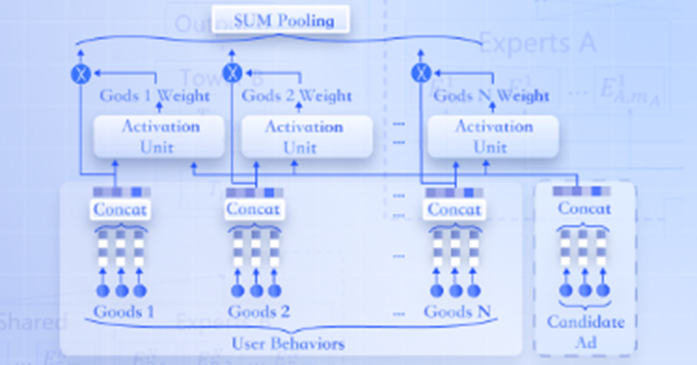
DIN(Deep Interest Network)是一种深度学习推荐模型,它通过引入注意力机制来处理特征,特别是在处理用户行为序列方面表现出色。以下是DIN模型的特征处理方式:
用户行为序列处理:DIN模型考虑了用户行为序列的特殊结构,即用户的兴趣是多样化的(Diversity)和局部激活的(Local Activation)。这意味着不同的用户行为对最终的点击事件有着不同的影响权重。
注意力机制(Attention Mechanism):DIN模型使用注意力机制来动态地计算用户历史行为与当前候选广告之间的相关性。这种机制允许模型对用户的历史行为进行加权,从而突出与当前候选广告更相关的行为。
局部激活单元(Local Activation Unit):DIN模型中的局部激活单元是实现注意力机制的关键部分。它通过一个前馈神经网络来学习用户历史行为和候选广告之间的权重,这些权重反映了不同行为对用户兴趣的贡献程度。
特征表示:DIN模型通过Embedding层将类别型特征转换为低维稠密向量,然后通过局部激活单元和加权求和(Weighted Sum Pooling)来聚合用户的行为序列,形成用户的兴趣表示。
特征交叉:DIN模型通过注意力机制隐式地进行特征交叉,而不需要像传统模型那样显式地设计交叉特征。
模型训练:DIN模型在训练时采用了Mini-batch Aware Regularization和Dice激活函数等技术,以优化模型的训练过程并提高模型的泛化能力。
特征输入:DIN模型的输入特征包括用户画像特征、用户行为特征、广告特征和上下文特征等,这些特征通过one-hot编码或multi-hot编码后输入模型。
变长特征处理:DIN模型处理变长特征(如用户行为序列)时,通过Embedding和Pooling层将变长的特征序列转换为固定长度的特征表示,使其能够被后续的全连接层处理。
DIN模型的这些特征处理方式使其在推荐系统和点击率预估(CTR)任务中表现出色,能够有效地捕捉用户多变的兴趣并进行精准推荐。
3. 深度学习在推荐系统中的实际应用
深度学习在推荐系统中的应用已经非常广泛,达观推荐系统正以其卓越的数据处理与特征提取能力,深刻地重塑着数据营销的生态格局。达观推荐系统不仅显著提升了营销策略的精准度与效果,还通过一系列创新应用,为企业带来了前所未有的市场优势。
首先,达观推荐系统构建了强大的个性化推荐引擎。它深度挖掘用户的历史行为数据,如浏览记录、购买偏好及点击行为,精准绘制用户画像,进而提供高度个性化的商品与服务推荐。这一功能极大地提升了用户满意度,促进了转化率的持续增长,使电商平台等企业受益匪浅。
其次,在点击率预测优化(CTR Prediction)方面,我们凭借先进的深度学习模型,能够精准预测用户对广告内容的点击概率,助力广告主优化投放策略,实现广告点击率和转化率的双重飞跃。这一技术的应用,极大地提高了广告投放的效率和效果,为数字营销市场注入了新的活力。
达观推荐系统还擅长多模态融合推荐,整合文本、图像、音频等多种类型的数据,为用户带来更加丰富、立体的推荐体验。同时,系统引入深度学习技术,持续与用户交互学习,动态调整推荐策略,以最大化用户满意度和长期收益。在社交关系驱动的信任推荐方面,达观推荐系统深度整合用户社交网络信息,提供更加相关、信任度更高的推荐,增强了用户对推荐内容的接受度和信任度。

深度学习技术的引入,为智能推荐系统带来了前所未有的机遇和挑战。达观推荐系统通过精准的用户数据采集、高效的特征处理以及先进的模型应用,我们能够构建出更加个性化、智能化的推荐系统,达观推荐系统也将继续发挥其独特优势,为数字营销行业注入更多智慧与活力,推动企业实现更加精准、高效的营销策略。
本文作者可以追加内容哦 !

