"最近新股行情火爆,中签就是赚到!从近期的打新表现来看,新股首日开盘基本稳吃大肉,动辄翻倍的涨幅让不少老铁直拍大腿。眼看华之杰上市首日在即,吧里讨论热度飙升——首日日内最高价究竟能冲多高? 这可是决定是开盘就跑还是格局到尾盘的关键!$华之杰(SH603400)$
如果能提前预判这个价格天花板,无论你是中签党想精准止盈,还是抢筹派准备盘中狙击,操作都能快人一步。今天咱们就玩点干货:结合行业估值、可比公司溢价、近期新股情绪、配售对象报价家数等数据,基于XGBoost模型,建模预测华之杰上市首日冲刺顶点! 手把手带你看懂主力推演逻辑,开盘前心里先画好路线图!"
一、数据变量选取
"构建有效预测模型的关键在于特征工程的科学性——既要覆盖核心定价因子,又要规避多重共线性等干扰。笔者在综合考量新股定价机制、市场流动性及行业估值体系后,精选以下12维特征变量:
基础发行指标:
发行价(元)、发行总数(万股)、网上发行(万股)、网上发行比例、申购上限(万股)
——反映标的稀缺性与打新参与门槛
估值锚定体系:
发行市盈率、行业市盈率
——构成IPO定价基准与行业溢价空间
市场情绪量化:
中签率、询价累计报价倍数、配售对象报价家数
——表征资金热度和机构博弈强度
衍生特征引擎:
市盈率倍数 = 行业市盈率 / 发行市盈率
(衡量发行估值相对行业的折溢价程度)
市盈率推算值 = 市盈率倍数 × 发行价(元)
(构建行业可比估值锚点)
基于上述特征矩阵,本文将对 '首日最高价' 建立预测模型。通过特征衍生,将静态发行数据转化为动态定价因子,使模型既能捕获行业估值传导效应(市盈率倍数),又能量化市场情绪对定价的重估影响(市盈率推算值),从而实现对价格冲刺顶点的多维度拟合。"
数据来源:东方财富、同花顺,选取2024年至今新股特征数据
二、数据预处理
"高质量的数据预处理是构建稳健预测模型的基石。在本研究中,笔者对原始数据集进行了系统性清洗与转换,主要包含三大关键步骤:
1.缺失值填充
针对数值型特征(如询价累计报价倍数、配售对象报价家数),采用均值填充策略:
修复值 = 列均值
此方法在保留数据分布特性的同时,避免因样本缺失导致模型训练偏差。对于关键特征(如行业市盈率)则采用同行业均值填充,确保估值基准可靠性。
2.数据标准化处理
由于各特征量纲差异显著,笔者实施Z-score标准化:
X_std = (X - μ) /
将全部数值特征转换为均值为0、标准差为1的分布,消除量纲对权重计算的干扰,大幅提升梯度下降算法收敛效率。
3.异常值平滑处理
通过箱线图分析识别出市盈率倍数中的极端离群值(如科创板新股超高溢价),采用Winsorize缩尾法将首尾1%数据替换为临界值,有效抑制噪声对回归模型的扭曲影响。
三、建模调参
“经过系统的特征工程和数据预处理,我们进入核心的建模阶段。为了找到最适合预测新股首日最高价的模型,我们重点对比了三大主流算法:支持向量机(SVM)、随机森林(Random Forest)和XGBoost。
模型对比与选择
在相同的数据集和特征条件下:
SVM表现相对基础,对复杂市场关系的拟合能力有限。
随机森林展现不错的稳定性,能有效捕捉多因素交互。
XGBoost凭借其梯度提升架构和正则化控制脱颖而出,在预测精度上显著优于前两者。它能更智能地组合特征(如市盈率推算值与其他因子的交互),并自动学习数据中的非线性规律和潜在模式。
性能与预期偏差
基于历史数据回测,最终选定的XGBoost模型在测试集上表现最优。其预测误差(以均方误差MSE衡量)约在1000左右。这意味着:
模型估算的首日最高价,与实际值可能存在大约 30元 的偏差范围。
为什么选择XGBoost?
高效捕获复杂性: 尤其擅长处理发行参数、市场情绪和行业估值之间的复杂关系。
抗噪能力强: 对数据中的小幅波动或轻度异常更具鲁棒性。
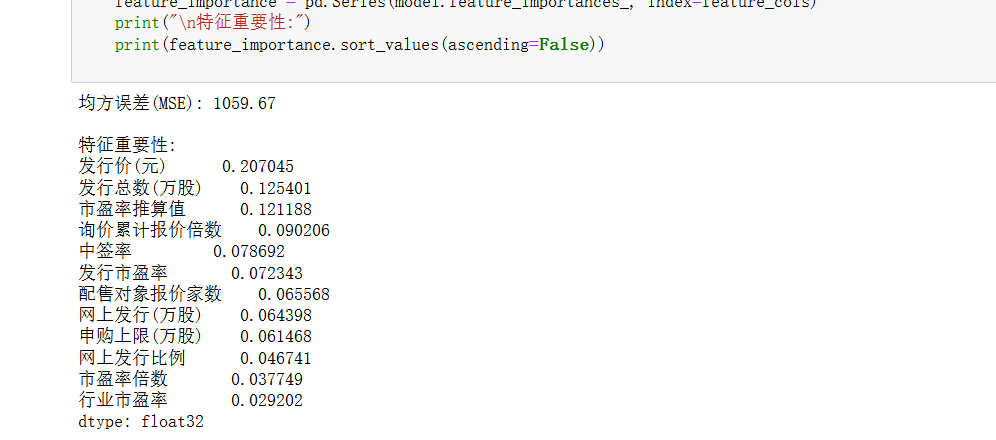
特征重要性明确: 可清晰识别如市盈率倍数、中签率等关键驱动因子。
虽然无法做到百分百精确(任何市场预测皆如此),但XGBoost模型提供的预测区间(30元)在实战中已足够为判断价格冲刺的大致范围提供有力参考,帮助制定更理性的止盈或入场策略。”
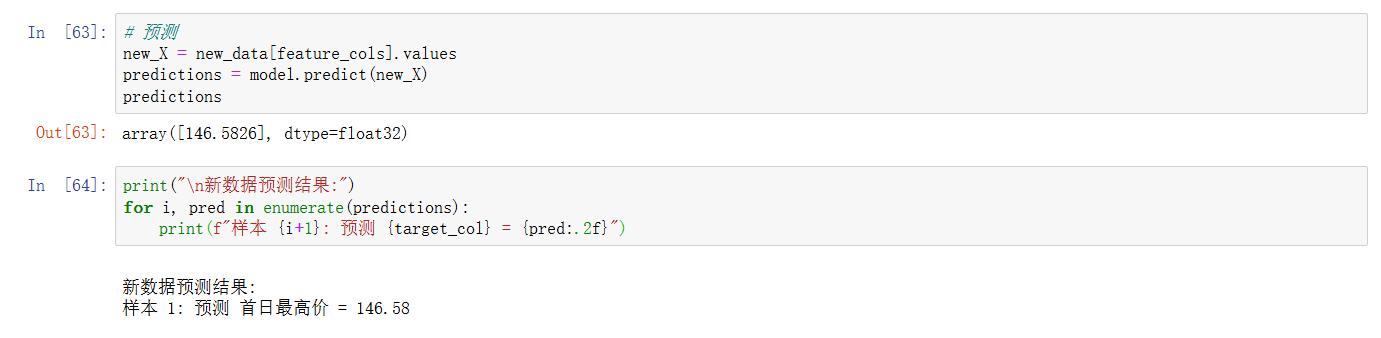
结论:XGBoost模型给出的最终结论大致为,首日日内最高价有望冲击146.58元,误差30元,考虑较为保守的情况,100元以上大概率是不成问题的!!
以上内容仅代表个人研究观点,模型预测存在误差可能,不作为投资依据。股市风险自担,操作请谨慎。
最后!!!!关键结果展示
本文作者可以追加内容哦 !

