
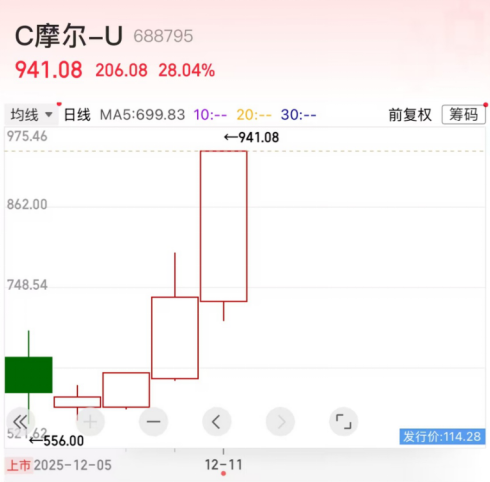
今日,摩尔线程再度暴涨,收盘涨幅达28.04%,创上市以来新高!#摩尔线程今日上市 中一签能赚多少钱?##DeepSeek寒武纪同步发布引关注#
对比首发价格,摩尔线程上市5个交易日涨幅高达723.49%!若是中签持有至今,单签浮盈超过41万元!
12月中下旬,另一家国产GPU公司——沐曦股份将紧随其后,登陆A股科创板。日前已公布中签情况,网上投资者缴款认购的股份数量为964.52万股,缴款认购的金额为10.09亿元,放弃认购数量为20349股,放弃认购金额为212.97万元,相比摩尔线程更难中签!
摩尔线程、沐曦股份,加上早已上市的寒武纪,“国产三强”格局已现!
一. AI算力芯片
AI算力芯片可分为通用型AI芯片和专用型AI芯片,当前AI算力芯片以GPU为主流。GPU生态体系复杂,建设周期长、难度大,GPU生态体系建立极高的行业壁垒,目前英伟达主导全球GPU市场。ASIC是一种专为人工智能应用设计的定制集成电路,具有高性能、低功耗、定制化、低成本等特点。
寒武纪、摩尔线程、沐曦虽都能提供AI算力芯片,但其产品仍存在不小差异。
寒武纪
寒武纪主要研发通用型智能芯片,定位上介于“完全通用的GPU”和“功能专一的ASIC”之间。这类芯片为加速AI计算而专门优化,但又保留了较强通用编程能力的处理器,可覆盖各类智能算法所需的基本运算操作,同时性能功耗比较传统芯片优势明显。
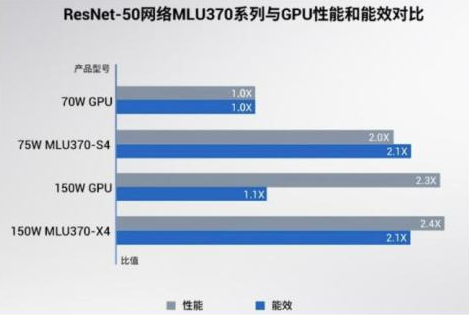
寒武纪目前智能加速卡有思元370、290、270系列。
思元100(MLU100):中国首款高峰值云端智能芯片。
思元290(MLU290):寒武纪首款云端训练智能芯片,采用了7nm工艺,在4位和8位定点运算下,理论峰值性分别高达1024TOPS、512TOPS。
思元370(MLU370):寒武纪首款采用Chiplet技术的人工智能芯片,是寒武纪第二代云端推理产品思元270算力的2倍。
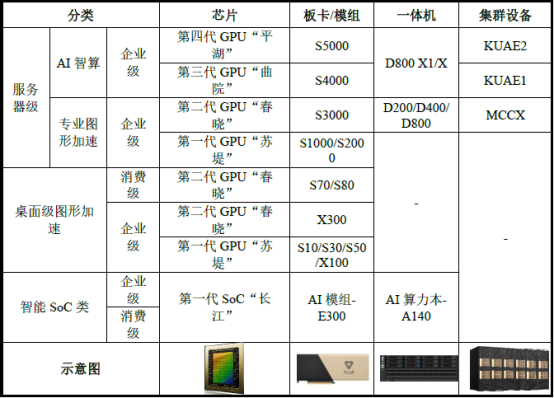
摩尔线程以自主研发的全功能GPU为核心,聚焦AI、数字孪生、科学计算等高性能计算领域,提供专业计算加速平台。凭借四代自主研发GPU架构的技术积淀,公司构建了覆盖AI智算、高性能计算、图形渲染、智能媒体的多元产品矩阵,产品线涵盖政务与企业级智能计算、数据中心及消费级终端市场。
基于自主研发的MUSA架构,摩尔线程目前已推出四代GPU架构芯片。
苏堤:第一代GPU芯片,内置了全功能GPU的四大引擎,即拥有AI计算加速、图形渲染、物理仿真和科学计算、超高清视频编解码引擎。
春晓:第二代GPU芯片,在提升芯片性能的同时,针对云计算以及GPU虚拟化的能力进行大幅优化;并且做到了对DirectX 11和DirectX 12的支持,为率先能支持DirectX 11和DirectX 12的国产全功能GPU,实现多款图形引擎的高性能适配,支持数字孪生以及工业设计、元宇宙等应用。
曲院:第三代GPU芯片,加强了AI训练和推理能力,公司基于该芯片搭建千卡集群智算中心。
平湖:第四代GPU芯片,增加了FP8精度支持,大幅提升AI算力,公司基于该芯片支撑面向DeepSeek类前沿大模型预训练的万卡集群智算中心解决方案
沐曦股份致力于自主研发全栈高性能GPU芯片及计算平台,主营业务是研发、设计和销售应用于人工智能训练和推理、通用计算与图形渲染领域的全栈GPU产品,并围绕GPU芯片提供配套的软件栈与计算平台。
沐曦主要产品全面覆盖人工智能计算、通用计算和图形渲染三大领域,先后推出用于智算推理的曦思N系列GPU、用于训推一体和通用计算的曦云C系列GPU,以及正在研发用于图形渲染的曦彩G系列GPU。
智算推理GPU——曦思N系列:先后实现智算推理GPU产品在传统AI任务和生成式AI任务中的落地。其中,曦思N100产品是面向云端和边端多种传统AI应用场景的智算推理GPU,提供强大的推理算力和视频编解码能力;后续产品如曦思N260、曦思N300(在研)均主要面向生成式人工智能下的云端人工智能推理场景,拥有强大的多精度混合算力,配以大容量显存和新一代高速I/O接口,支持主流深度学习开发框架,可为内容生成式应用和大语言模型等智能应用提供端到端的加速服务。

训推一体GPU——曦云C系列:针对云端计算场景,为人工智能训练和推理、通用计算提供算力底座,具备高性能、高自主可控、高扩展性。曦云C系列产品具有强大的多精度混合算力、高带宽和大容量存储,结合其自研的MetaXLink 高速互连技术,能够满足大规模计算集群扩展需求、支持千亿参数以上的AI大模型训练,可以大幅增加集群算力、缩短大模型计算时间。
图形渲染GPU——曦彩G系列:面向图形处理和智算推理的图形渲染GPU,采用公司自研的XCORE 2.0架构及指令集,内置性能强大的GPU IP和硬件单元,具备卓越的图形处理能力,可广泛应用于云渲染、游戏、数字孪生、影视动画制作、专业制图等场景。
二. 优势
寒武纪:软硬件协同$寒武纪-U(SH688256)$
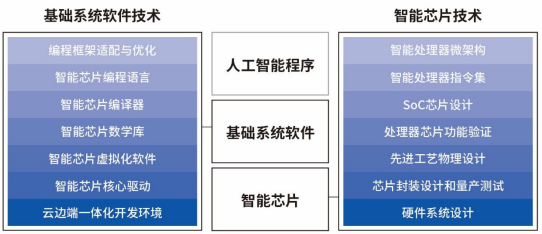
寒武纪全面系统掌握智能芯片及其基础系统软件研发和产品化核心技术。
在智能芯片领域,掌握了智能处理器微架构、智能处理器指令集、SoC芯片设计、处理器芯片功能验证、先进工艺物理设计、芯片封装设计与量产测试、硬件系统设计等关键技术;
在基础系统软件技术领域,掌握了编程框架适配与优化、智能芯片编程语言、智能芯片编译器、智能芯片数学库、智能芯片虚拟化软件、智能芯片核心驱动、云边端一体化开发环境等关键技术。
摩尔线程:兼容英伟达生态
MUSA架构为公司自主研发的加速计算架构。该架构涵盖统一的芯片架构、指令集、编程模型、软件运行库及驱动程序框架等关键要素,且同一代码能够在公司不同GPU产品及系统上运行,具有良好的灵活性与可扩展性。
MUSA架构具备与由英伟达主导的国际主流GPU生态的兼容性,使得开发者能够以较低成本充分利用目前国际主流生态下的代码资源。基于MUSA架构开发的应用程序不仅具有广泛的可移植性,还能够同时在云端及边缘的众多计算平台上运行,其应用领域广泛,涵盖AI、图形处理、科学计算等多个重要方向。

此外,摩尔线程是国内少有的在京东等电商平台面向消费者市场展开销售的国产GPU企业。MTT S80是公司推出的国内首款支持Windows操作系统以及DirectX 11/12图形计算库的消费级显卡,其性能规格与英伟达RTX 3060相当。公司在两年时间内先后完成24版驱动更新,显卡性能表现提升数倍,成功兼容近千款游戏和应用。
沐曦股份:商业化快速落地
公司仅用3年时间便实现两款芯片一次流片并成功量产,快速实现了商业化、规模化落地,是国内少数真正实现千卡集群大规模商业化应用的GPU供应商。凭借突出的产品性能和稳定的供应能力,截至2025年Q1末,沐曦GPU产品累计销量超过25000颗。
此外,在通用性方面,沐曦MXMACA软件栈实现了对英伟达CUDA生态的高度兼容,为人工智能、通用计算和大数据处理等领域的现有应用提供了高效迁移至MXMACA软件栈的能力,开发者无需过多修改现有代码即可将应用快速部署到公司的GPU 产品上运行,大幅降低客户应用迁移本、提升迁移效率。
(特别说明:文章中的数据和资料来自于公司财报、券商研报、行业报告、企业官网、百度百科等公开资料,本报告力求内容、观点客观公正,但不保证其准确性、完整性、及时性等。文章中的信息或观点不构成任何投资建议,投资人须对任何自主决定的投资行为负责,本人不对因使用本文内容所引发的直接或间接损失负任何责任。)
本文作者可以追加内容哦 !

