当整个AI圈沉浸在GPT-4的余波中,认为大语言模型已经走到技术巅峰时,OpenAI却在一个深夜悄然投下了技术的“核弹”——全新大模型o1。没有任何预告,没有任何铺垫,就像一个突如其来的炸弹,这一发布瞬间点燃了整个行业的兴奋与不安。
在凌晨的科技圈,无数人因为这次发布彻夜难眠。微博、知乎、推特等社交媒体平台上迅速刷屏,AI从业者们纷纷陷入了激烈的讨论:为什么OpenAI要重置它们引以为傲的GPT系列,推出全新的o1?而且,这不仅仅是个名字的更改,OpenAI宣告这次是“从1开始”,这意味什么?
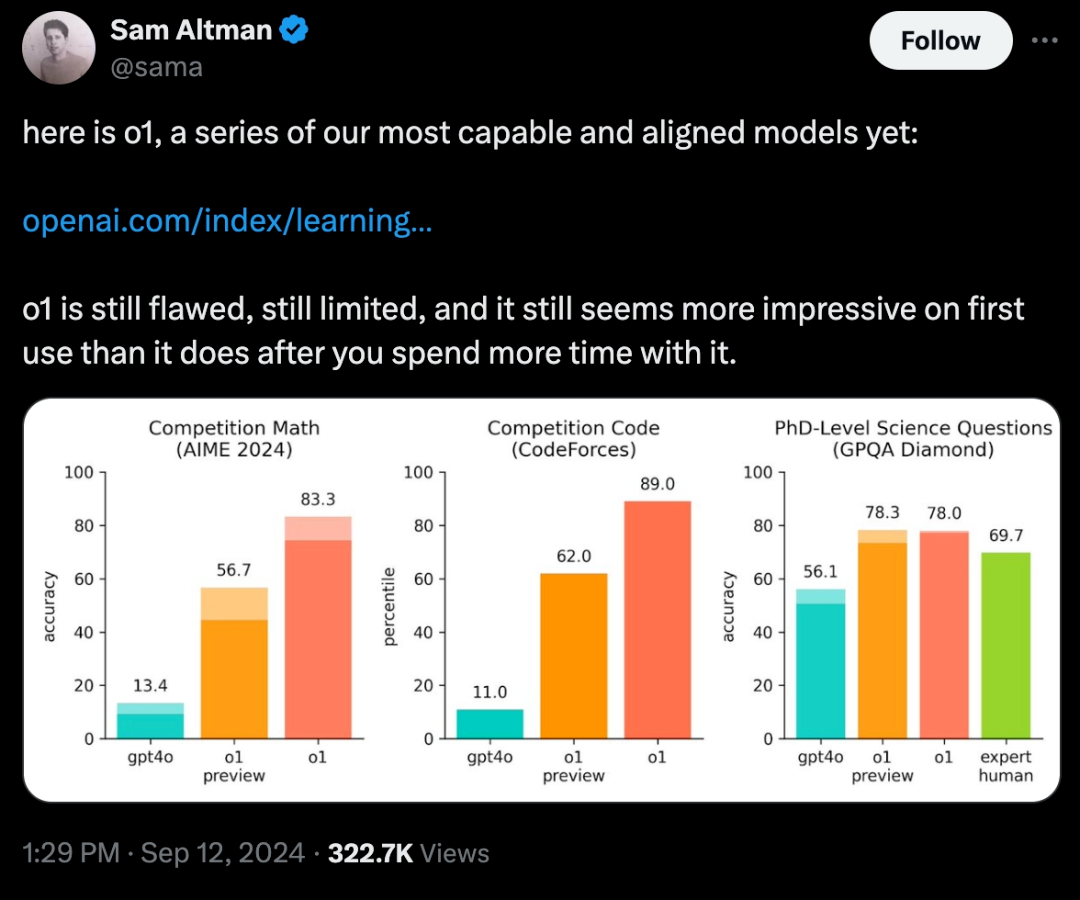
数据不撒谎,o1的推理能力如何碾压GPT-4?
OpenAI o1的发布,不仅仅是大语言模型的一次更新迭代,更是AI能力的一次重新定义。其在数学、科学和编程等多个领域的表现,展现出显著的进步,尤其是在推理能力方面。与GPT-4相比,o1实现了质的飞跃,数据证明了这一点,也预示着AI技术即将迈入一个全新的阶段。
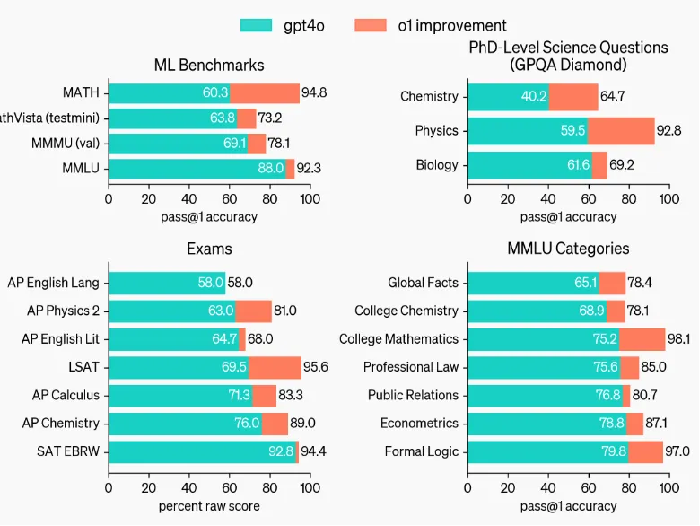
数学与科学领域的彻底“翻盘”
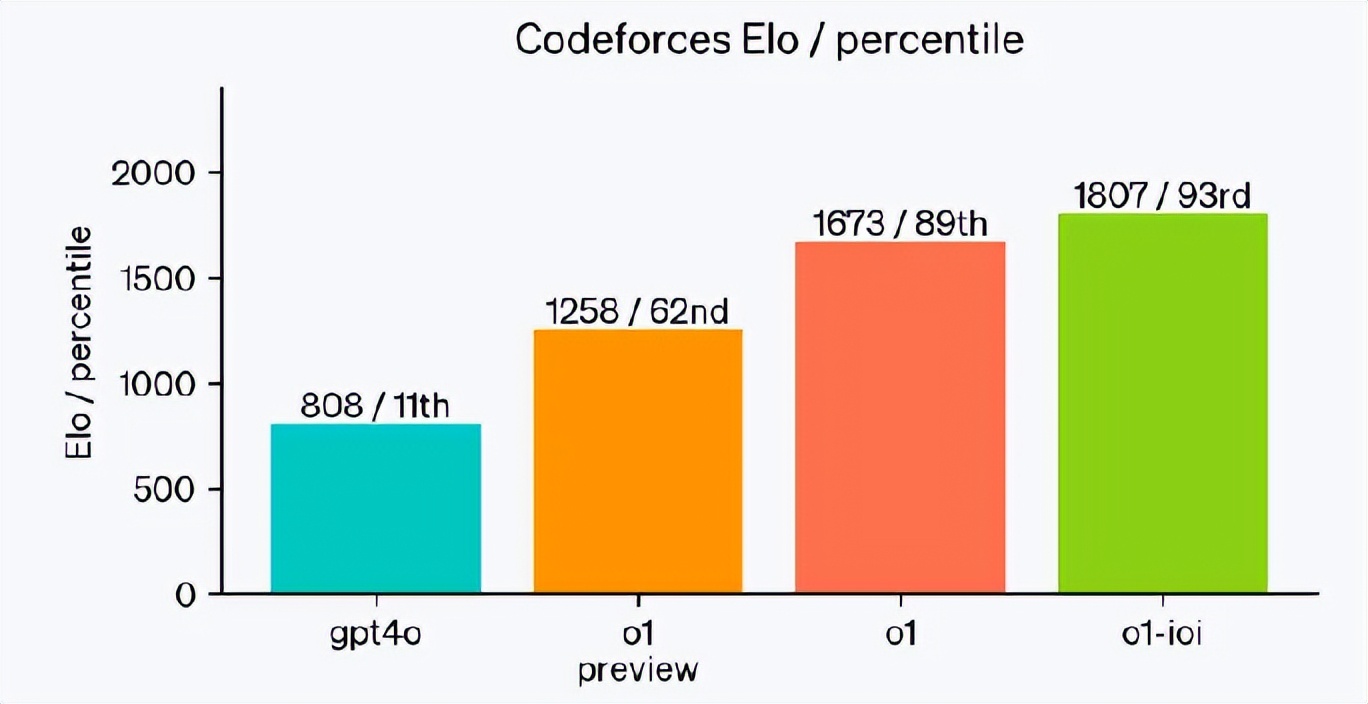
数学推理一直是衡量AI逻辑能力的重要标准。在全球知名的美国邀请数学竞赛(AIME)中,GPT-4的表现并不理想,准确率仅为13.4%。然而,o1的登场改变了这一局面。数据显示,o1预览版在AIME中的正确率已经达到56.7%,而正式版更是将正确率推高至83.3%,几乎可以与顶尖的数学竞赛选手媲美。这意味着,o1不仅能够处理基础数学问题,还具备拆解复杂推理过程的能力。
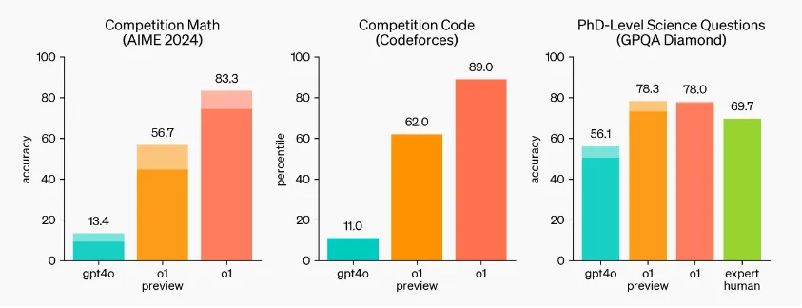
o1在科学推理领域同样展现了超凡的表现。在GPQA Diamond测试中(该测试用于评估AI在化学、物理和生物学等领域的专业推理能力),GPT-4的正确率为56.1%,已接近专家水平。但o1再次超越预期,其预览版的正确率达到78%,首次在科学推理能力上超过了拥有博士学位的专家。这一进步表明,o1不仅是数据处理的工具,正在逐渐具备与人类专家在科学领域“平起平坐”的能力。
这些数据表明,o1不再只是简单的“辅助工具”。与以往AI更多专注于基础性工作不同,o1正在向高智力任务迈进,展现出独立思考和深度推理的能力。AI不仅能解答高难度的数学题,还能在科学推理上超越人类专家,意味着AI正在向更高层次的认知跃升。
代码能力的质变:从11%到89%
编程能力是AI另一个关键领域。GPT-4曾在代码竞赛中表现出色,具备一定的代码生成和调试能力,但其准确率仅为11%。相比之下,o1在代码任务上的进步如同一次质变。其预览版的代码竞赛准确率达到62%,而正式版更是提升至89%。这一提升不仅代表了AI在编程中的进步,更预示着AI可能即将成为独立完成代码任务的“AI工程师”。
o1不仅能编写代码,还能在复杂编程逻辑中推理、纠错。这种能力的进化暗示,未来的AI开发者可能不再需要手动编写大量代码,而是让AI独立承担复杂的编程工作。AI在编程领域的质变,或许标志着AI工程师时代的到来。
总体而言,o1在数学、科学和编程领域的出色表现,展示了AI推理能力的巨大飞跃。这不仅意味着AI从“快思考”进化到“慢思考”,更预示着AI正在迈向更高层次的智能形态。未来的AI或许不仅是人类的助手,甚至将成为智力领域中的“平等对话者”。
值得提出的是,o1并不是一个“期货”产品,已经面向会员用户开放试用了。
为了对o1进行极限测试,我给了他一个超高难度的问题:“中国足球一直不行,你觉得问题到底出在哪里?如果让你来搞中国足球,你打算怎么消除积弊,带领中国足球冲向世界?”
先让GPT-4试试水。

接下来,用o1试试。可以发现,相对于GPT-4,o1用了16秒钟时间来“思考”,并给出了他的思考过程。
但是,无论是GPT-4还是o1,给出的答案都不能让我满意。看来,中国足球如何才能搞好,真的是一个世界未解之谜,解决这个问题的难度,堪比哥德巴赫猜想。

有意思的是,我仔细查看了o1的“思考”过程,发现他对自己设定了诸多限制,尤其是避免出现敏感的内容。也许,o1知道中国足球的问题在哪,只是不方便说出来吧。

虽然还不能解决中国足球的问题,但也不妨碍o1的优秀,以及他对大模型行业的变革意义。接下来,我们还是回归到技术本身,来对大模型行业的发展趋势进行探讨。
o1的技术奥秘,强化学习与思维链如何改变AI游戏规则
OpenAI o1的发布不仅仅是推理能力上的质变,它背后的技术核心——强化学习(Selfplay RL)和思维链(Chain of Thought)——深刻改变了AI的“思维方式”。这些技术让AI不再只是“数据匹配器”,而是一个能进行深度推理、主动优化的智能体。o1通过这两大技术,迈出了让AI真正“像人类一样思考”的关键一步。
什么是Selfplay RL?
想象一下你在和自己下棋,连续对弈数千次,赢的那一方不断学习策略,失败的一方则反思自己的错误,下一局再接再厉。这就是Selfplay RL的本质。简单来说,o1通过与自己对抗来提升自身推理和解决问题的能力,它不再需要人类老师时刻监督,而是通过“自学”来优化策略。
对于大多数AI模型来说,学习意味着依赖大量的数据集和训练样本,但o1的Selfplay RL机制让它在面对复杂问题时能够通过不断模拟、假设、对抗,从自己的错误中学习,最终变得更加智能。这是一个类似于游戏高手不断挑战自己的过程,通过不断“较劲”来提高技能,o1因此具备了前所未有的自我优化能力。
Selfplay RL如何解决GPT-4的瓶颈?
在GPT-4时代,我们已经见证了AI在模式匹配和语言生成上的巨大飞跃,但它们仍然像是一个“应答机器”——输入一个问题,输出一个答案。然而,当涉及到多步骤推理、复杂逻辑甚至解决全新问题时,GPT-4的表现就有点力不从心了。
这就是Selfplay RL的奇迹之处。它不仅让o1学会了从自己的错误中进化,还能够通过不断尝试不同策略来找到最优解。想象一个学生,每次做完错题后,不仅改正错误,还会通过反思推导出更多类似题型的解题思路。这种“自我进化”的能力,是GPT-4无法比拟的。
o1通过这种强化学习机制,成功超越了以往大模型的“死记硬背”式学习方式。它变得像一个策略高手,在面对复杂推理任务时,不再依赖预先给定的答案,而是自己不断尝试、推理、纠错,最终找到最佳解决方案。这让它在面对复杂问题时表现出远超GPT-4的智力优势。
o1如何像人类一样思考?
假如你在解一道数学题,你不会一眼就知道答案,而是会逐步拆解问题:先解出一部分,再利用这部分的结果解出另一部分,直到最终找到答案。这就是o1的“思维链”(Chain of Thought)机制。不同于GPT-4的“快思考”,o1在面对复杂问题时,会通过类似“系统2”的慢思考过程,一步步推敲每个逻辑环节。
简单来说,思维链让o1能像人类一样把复杂问题分解成一系列小任务,然后逐个解决。这种思维方式不仅提升了o1的推理能力,还让它能够解释自己的推理过程。换句话说,o1不再是一个单纯的答案生成器,而是一个能够“展示解题思路”的智能体。
思维链如何让o1的推理胜过GPT-4?
GPT-4的强大在于它能快速给出答案,但它的弱点同样显而易见——在处理复杂多步骤问题时,它缺乏逐步推理的能力。它的回答往往看似流畅,但却难以真正解释每一步的逻辑过程。你可以把GPT-4想象成一个“背诵答案的学生”,而o1则像是一个“逐步推导答案的高手”。
通过思维链,o1不仅能得出正确答案,还能解释这个答案是如何一步步推理出来的。比如在解决复杂的数学题时,o1会先展示步骤1的推导,然后在步骤2中使用步骤1的结果,再进行下一步推理。相比之下,GPT-4可能只是直接给你一个结果,但往往缺乏严谨的推导过程。
这种能力的提升让o1在应对复杂逻辑问题时,展现出了前所未有的实力。在面对需要多步骤推理的问题时,思维链让o1不仅能解决问题,还能给出清晰的解题路径,而这一点是GPT-4难以企及的。
AI的推理与人类智力的边界在哪里?
随着o1展现出这种前所未有的推理能力,我们不得不提出一个尖锐的问题:当AI可以像人类一样,逐步思考并推理复杂问题时,人类智力还能保有多少优势?o1通过强化学习与思维链的结合,已经在某些高智力任务上实现了超越——在数学竞赛、科学推理甚至编程任务中,它已经超越了大多数人类。
我们曾经认为AI的强项在于快速处理海量数据,但它在复杂推理上还远不及人类。然而,o1正在打破这一认知。当AI可以从容不迫地拆解复杂问题时,或许我们正处在一场智力竞赛的临界点——未来的AI不再是简单的工具,而可能成为真正的思维伙伴。
这也引发了更深层次的思考:o1的这些技术突破,是否意味着我们正在逼近AGI(通用人工智能)?强化学习让o1学会从自身对抗中进化,思维链让它具备了像人类一样逐步推理的能力。这两个技术组合,是否能成为迈向AGI的关键?而当AGI真正出现时,我们人类将处于什么样的智能生态中?
从AlphaGo到o1,AI强化学习的进化史
2016年,AlphaGo震撼全球,通过自我博弈和深度神经网络的结合,在围棋这类规则明确的封闭系统中不断优化,最终击败了人类围棋顶尖高手。强化学习在这一过程中展现了其强大的自我进化能力——AI通过每一局的胜负反馈,不断学习最佳策略,最终在特定领域超越了人类智力。
尽管AlphaGo在围棋中取得了巨大成功,但其强化学习机制依赖于封闭规则和明确的胜负反馈。这种系统对于AI的优化路径十分清晰,而现实世界中的问题,如科学推理、编程、复杂决策,通常没有明确的规则和即时反馈。因此,AlphaGo无法有效扩展到更复杂、开放性的现实领域。它的强化学习模式局限于“专家型智能”,难以应对多样化的挑战。
o1与AlphaGo的最大区别在于,它结合了大语言模型的深度和强化学习的自我优化能力。AlphaGo的神经网络虽然功能强大,但与今天的o1相比,其深度和规模远不及后者。o1依赖的大模型拥有数百到上千层的神经网络,能够处理海量的复杂数据。更重要的是,这种规模带来了“智能涌现”现象,使得o1不仅能从历史数据中推理,还能应对未知问题,展现出新的认知能力。
AlphaGo展示了AI在特定领域的专家智能,但o1则让我们看到了AI向通用智能迈进的潜力。大模型提供了广泛的知识储备,强化学习则让o1能够在这个基础上不断优化、进化。相比AlphaGo只能在围棋这样的封闭系统内提升,o1能够应对多领域的复杂问题——科学推理、编程、数学题解——它都展现出了超越领域局限的能力。
o1的技术路线表明,大模型与强化学习的结合可能是迈向AGI的关键路径。AGI的核心在于应对未知问题、自主学习和不断提升的能力。o1不仅能处理现有问题,还具备通过自我反思与优化,生成新知识、应对新挑战的潜力。这一质变使得AI向真正通用智能的方向迈出了至关重要的一步。
强化学习 vs RAG,谁才是未来?
随着AI技术的飞速发展,各国在AI技术路线上的选择开始逐渐分化。据我们观察,以中国为代表的部分技术路线,更倾向于大模型+RAG(Retrieval Augmented Generation)的结合,而OpenAI则选择了强化学习+大模型的路径。这两种技术路线背后,体现了对AI未来发展的不同思考方向:短期的快速商用落地,还是长期的智能深度进化?
RAG技术结合了大模型与信息检索,国内如Kimi、腾讯元宝等大模型解决方案广泛采用了这种路径。RAG的核心在于,当用户提出问题时,AI并非直接基于训练数据进行回答,而是首先通过搜索引擎、数据库或其他文档检索相关信息,再将这些信息进行总结和生成答案。
这种方法尤其适用于处理涉及大量实时信息的问题,例如新闻、政策、网页更新等。通过RAG,AI可以根据检索到的最新信息快速生成准确的回答,避免了传统大模型在面对实时信息时的滞后。
RAG路线的优势在于其商用落地的速度和效果。与依赖大量训练数据的大模型相比,RAG能够更好地处理实时性问题,具备更强的知识更新能力。在具体应用中,RAG路径特别适合搜索引擎、文档处理、智能问答等场景。这种能力让它在短期内实现快速商用,满足了企业对效率和实用性的需求。
然而,RAG的局限性也不容忽视。由于RAG依赖于检索外部信息,其核心依然是信息总结,而非推理本质。这种模式让AI在应对复杂推理和创新任务时表现不足,因为AI更多是依赖已有知识做出总结,缺乏独立思考、深度推理的能力。也就是说,RAG擅长“找答案”,但不擅长“推理答案”。
与中国的RAG路线不同,OpenAI选择了将强化学习与大模型结合的路径,核心优先级是提升AI的推理能力,而非依赖于外部信息检索。o1的技术路线更专注于让AI具备自我学习、自我优化的能力,通过大模型提供的知识储备,强化学习让AI能够在复杂的多步骤推理中逐步找到解决方案。
这种技术优先级的选择,意味着o1更关注的是AI如何独立解决问题,而不是仅仅作为信息检索工具。在实际应用中,o1的推理能力展现出了极高的价值,特别是在数学、科学和编程等复杂领域,o1能够通过自我对抗和逐步推理,给出比人类更精准、更深度的答案。
强化学习与RAG技术路线的本质区别在于,前者强调AI的独立推理能力,而后者则更像是“扩展工具”,依赖于外部信息的检索和总结。强化学习使AI在面对未知问题时,能够通过自我学习和反复尝试找到新的解决路径,而RAG则无法生成新的知识,只能基于已有数据做出判断。
从长远来看,强化学习与大模型的结合可能是通向AGI的关键路径。虽然RAG在短期内提供了更好的商用落地方案,但强化学习的深度智力提升能力,可能是推动AI实现质变的关键。如果AI的未来在于“独立思考”,而非“检索答案”,那么强化学习的路线无疑是通向智能进化的正确方向。
中国AI产业的隐忧,急功近利与技术探索的割裂
近年来,中国AI产业的发展速度惊人,尤其是在商用落地的层面,各大企业争相推出各种应用,迅速抢占市场。然而,这背后的隐忧逐渐显现:在快速商业化的背后,前沿技术探索的步伐却明显滞后。这种急功近利的现象,可能正在将中国AI产业引入一个“短视陷阱”,为未来的技术革命埋下隐患。
当前,中国的AI产业似乎陷入了一种“商用至上”的思维模式:与美国等国家大力突破技术天花板、推动前沿技术不同,国内企业将更多的精力放在如何将现有技术快速商用上。
除了上面提到的RAG,国内企业普遍偏爱小模型、行业模型、私有模型,或者推出一堆功能繁杂的APP,都是这一现象的表征。在这些商业化应用中,国内企业似乎更关注如何快速将功能推向市场,忽略了对底层技术的深度探索。
这一现象并非首次出现。当美国在深度学习领域持续突破时,国内许多企业仍抱着传统机器学习不放,认为短期商用更为重要,结果导致在深度学习的国际竞争中,中国AI失去了先发优势。这也是为什么ChatGPT首先出现在美国,而不是中国的一个重要原因。历史已经证明,技术探索的滞后意味着在未来关键节点上错失红利。
诚然,商用落地能够带来即时的经济效益,但在AI技术不断突破的当下,过分聚焦商用落地而忽视前沿探索,将导致中国AI产业在未来的大模型竞争中陷入困境。下一波技术红利,可能并不会等那些醉心于现有技术商用化的企业。
大模型的发展速度远超预期,从GPT3到GPT-4,再到o1,技术迭代的时间窗口不断缩短,AI技术天花板一次次被打破。而中国企业如果继续局限于现有的RAG路径和小模型应用,便可能被困在这条低门槛、低天花板的路径依赖中。下一波AI浪潮很可能来自更具推理能力、泛化能力的大模型+强化学习路线,而中国企业如果在这一领域投入不足,未来将陷入“技术降维打击”的风险中。
显示面板行业为我们提供了一个典型的教训。LCD技术曾经是主流,许多企业为了快速商用,将资源集中投入到LCD的产能扩张上。然而,随着OLED等新技术的迅速崛起,LCD技术逐渐被淘汰,大量过度投入LCD技术的企业陷入了“沉没成本”困局。过度投资旧技术,导致了在新技术爆发时的应对不力,形成了一场典型的技术代际更替的灾难。
同样的情景正在AI行业上演。如果中国的AI企业过度依赖当前的技术路线,将资源集中在短期商用上,忽视对下一代技术的持续投入,未来很可能重蹈覆辙,面临技术迭代时的巨大冲击。
中国AI产业正处于历史性关口。当前的商用策略固然能带来短期利润,但长期来看,过度关注商业化而忽视前沿技术,将使得中国AI产业在全球技术竞争中陷入不利地位。下一个技术红利期属于那些敢于突破技术天花板、深耕前沿技术的企业。如何在技术探索与商用落地之间找到平衡,将决定中国AI产业能否在未来保持全球竞争优势。
本文作者可以追加内容哦 !

