在Tesla Robotaxi Day来临之际,我们开设上下两篇产业报告回顾2022 AI Day的内容。本系列报告成文时间为2022年底,上篇主要分享Tesla专用于自动驾驶深度学习的训练硬件—DOJO,下篇主要分享 Tesla自动驾驶深度学习的算法内容,希望能帮助大家更好了解Tesla的Robotaxi。
Tesla的DOJO是一个由Tesla开发的超级计算机系统,专门用于加速人工智能(AI)和深度学习模型的训练,特别是为Tesla的自动驾驶系统(FSD,Full Self-Driving)提供支持。DOJO的设计目标是通过强大的计算能力和优化的架构,来处理海量的数据,从而使Tesla的自动驾驶技术更快地提升和改进。
01
为什么要设计专用的训练芯片

现阶段全球主流云计算的硬件为CPU和GPU,用于自动驾驶深度学习训练的硬件一般为Nvidia的A100,包括Tesla和国内新造车势力现阶段均以GPU为主,比如Tesla现阶段使用了4000张GPU用来做数据的自动标注、1万张GPU来做训练,既然Tesla前期已经在GPU上花费了巨资,为什么还需要重头设计一款全新的训练芯片/系统?
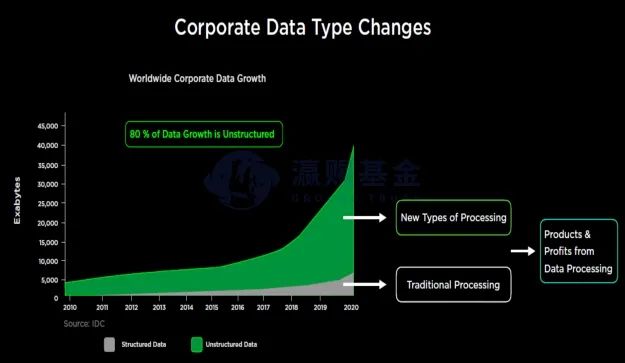
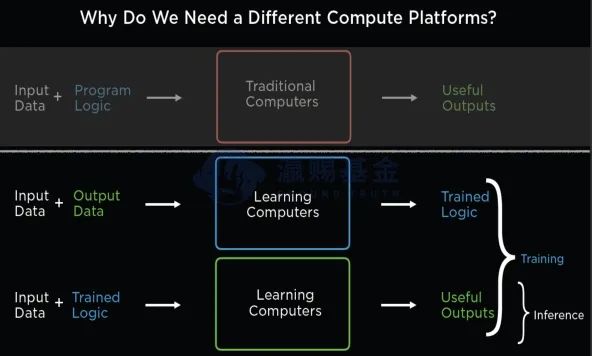
大型企业过去收集到的数据更多是一种结构化的数据,常规的数据处理过程是基于人类的逻辑编程(Software1.0),而现阶段企业收集的数据中心80%属于非结构化、离散化的数据(比如外卖订单),对于新的数据,如果采用传统数据处理方式,会效率低、效果差,因此新的数据需要新的训练体系(Software2.0)。Software2.0硬件的最大特点是数据驱动+可学习迭代,目标客户的特征归纳来自数据而不是人类逻辑、通过数据训练来实现更好的边缘侧推理结果。
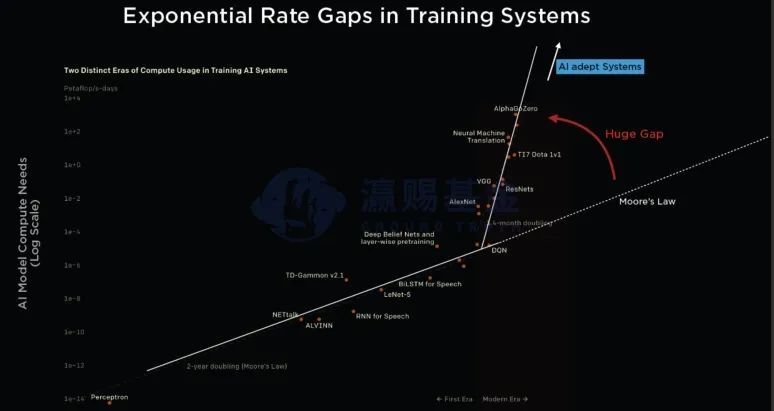
Google基于云端训练开发的TPU芯片、Amazon基于云计算开发的Graviton芯片、微软聘请苹果公司资深工程师Mike Filippo开发Azure服务器芯片等等(即使考虑到GPU内部的的RT单元同样是一个ASIC),从全球互联网巨头陆续开始自研芯片的产业变化中,我们可以感受到,在摩尔定律减速、超大AI模型算力每个季度翻倍的背景下, 需要全新的芯片和系统来适应AI时代的到来。
02
DOJO如何实现更好的性能
在集成电路产业中,从芯片的制造、到封装和最后的训练系统(如A100),整个系统的带宽和延迟比例逐步下降,即芯片的算力优势无法在系统层面得到体现。
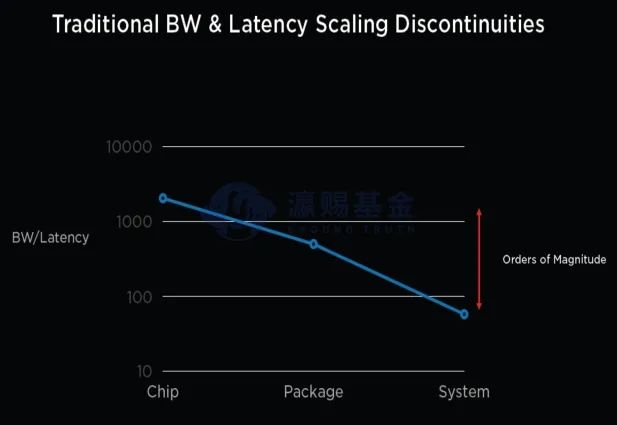
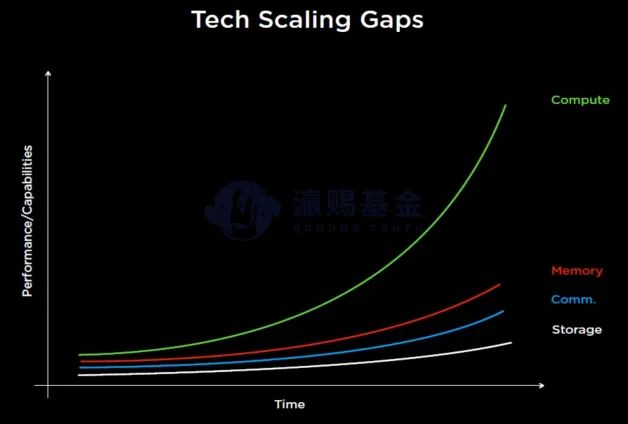
出现这一结果的原因在于,算力的扩展随着先进制程工艺的进步和规模化扩展,整体呈现指数级别提升,但导致系统训练效率下降的核心原因在于I/O与内层墙的问题,因此DOJO如果想提升效率,需要解决上述问题。
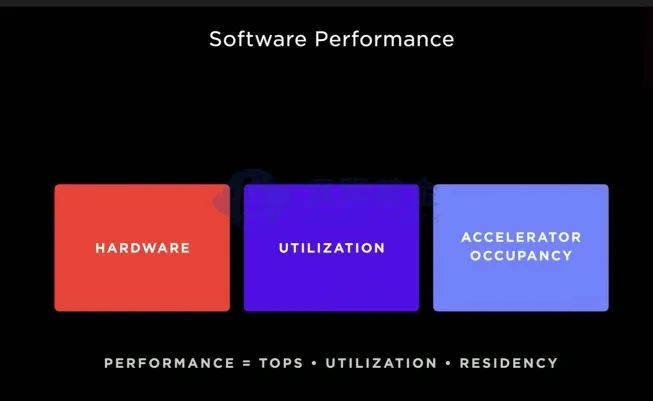
Tesla在进行DOJO设计之初,已经从硬件、算力利用率、加速核使用率三个角度来优化整个系统的训练效率。
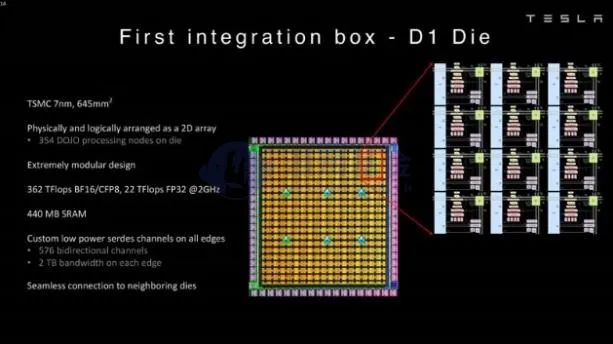
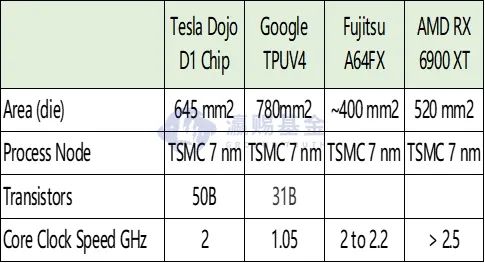
在硬件的工艺制程方面,DOJO采用了TSMC的7nm工艺,同时独家采用了TSMC的InFO_SoW的封装工艺,25片D1芯片集成在了同一块晶圆,从而有效的提升了I/O能力。
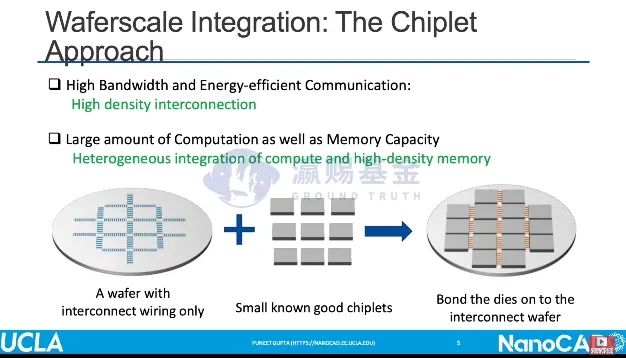

在算力利用率方面,Tesla的处理同样是基于自动驾驶场景的定制化需求。Tesla的自动驾驶解决方案基于纯摄像头的视觉解决方面,因此数据是以视频流的方式展现,而所用的深度学习模型是基于3D卷积、RNN、Transformer等,考虑到ML学习大模型化的趋势,未来可能会出现模型过大、单一处理器无法加载情况,DOJO如何解决这个问题?
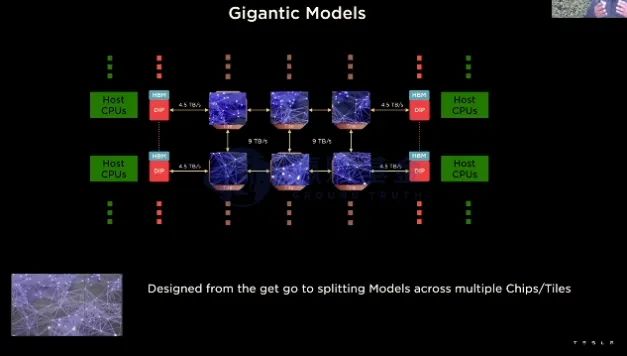
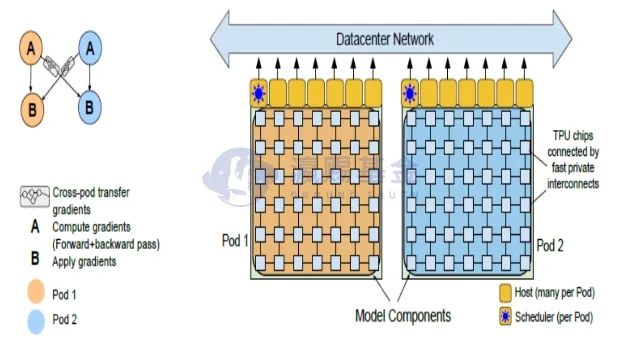
DOJO采用了分布式训练的思路,如上图(上)显示,DOJO在D1芯片层面对模型进行了分解,这样如果ML模型过大同样可以采取更高效的SRAM处理。上图(下)为Google的TPU芯片计算架构,A和B分别为计算的梯度优化和梯度更新利用,两个计算单元Pod1和Pod2首先通过分布式训练完成梯度更新,然后通过数据总线网络进行交互,可以看到DOJO和TPU在模型优化层面有着相似性。
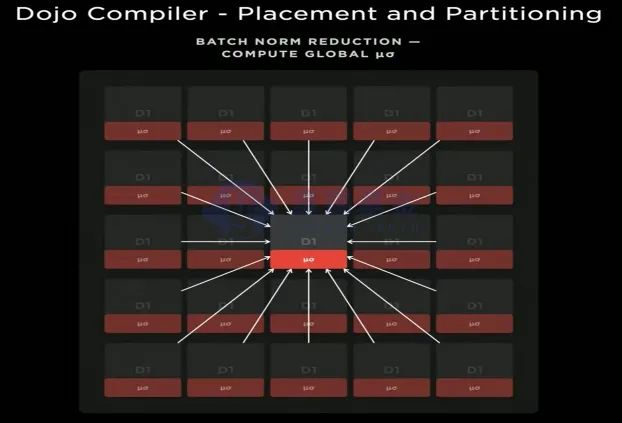
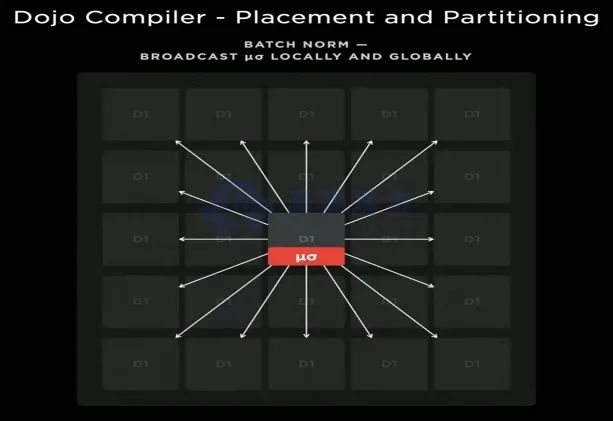
DOJO为了进一步提升模型处理效率,还采取本地计算+全局广播更新的思路,比如在单一的Train Tile处理ML常用的批量标准化处理时,25块D1首先本地化计算,然后通过从外向内的方式更新均值和标准差,汇总至中心的D1芯片后得到最终参数,然后向外广播至不同的D1进行参数更新。
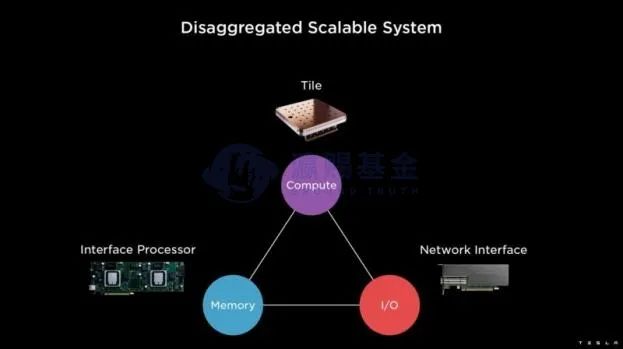
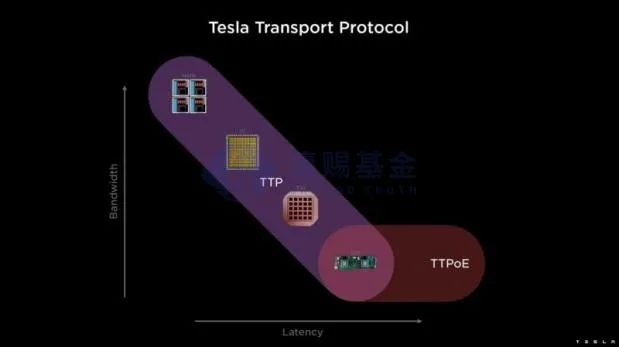
除了通过编译器进行模型、数据和硬件的灵活训练外,Tesla还通过自定义的TTP协议来加快通信速度。
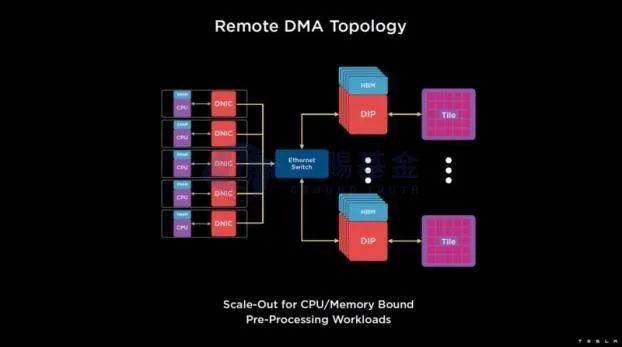
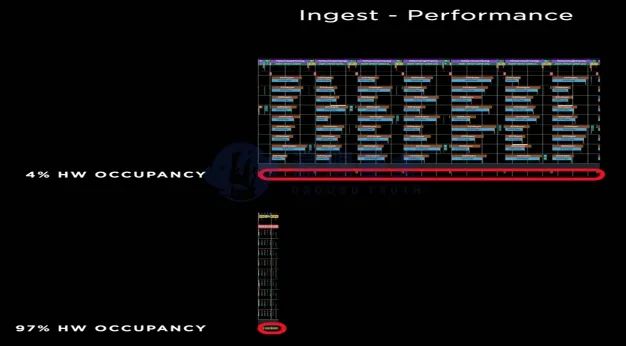
通过硬件DIP、以太网交换机和定制化通信协议TTP,DOJO成功的将加速核使用率从4%提升至97%。
在内存墙环节,DOJO采用了目前AI加速核通用的做法,即采取大容量SRAM来解决内存读取速度过慢的难题。

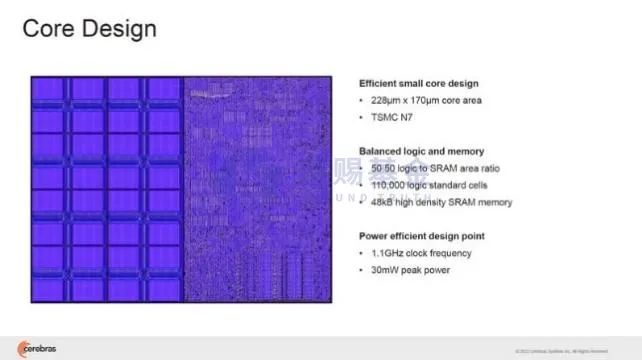
DOJO每个训练节点配置1.25M的SRAM,按照每块D1354的节点(SRAM达到440MB)、每个训练Tile25块D1,单个训练Tile的SRAM高达11G。近几年AI训练非常热门的一家公司Cerebras更是把片上存储做到了极致,Cerebras设计的Core上逻辑和存储(SRAM)的面积比例50:50,由于在整块晶圆上设计了加速核和存储单元,因此内存信息的读取速度比片外内存要快的多。
此外,DOJO还在同步机制、虚拟内存、数据格式等环节做了针对深度学习的优化,在硬件、模型和软件(编译器)三个环节做了系统性提升。
03
DOJO训练效果和未来对自动驾驶及AI产业的影响
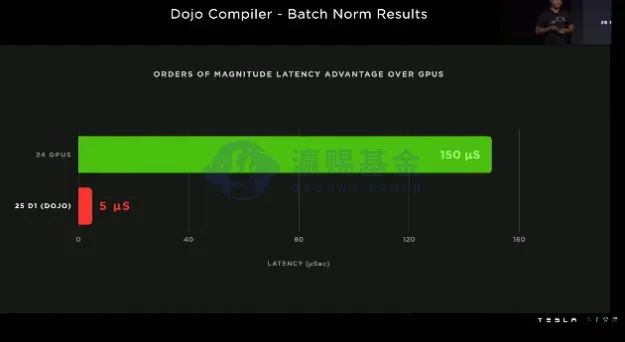
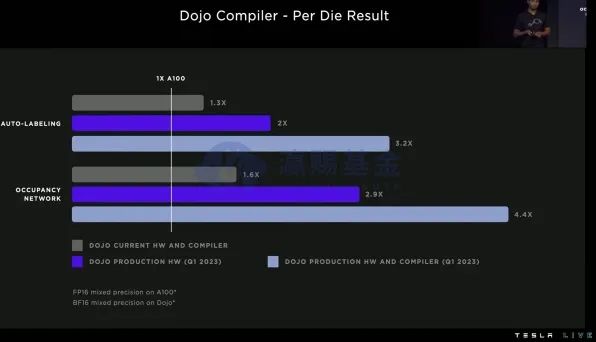
从测试的数据来看,DOJO的数据延迟只有GPU的1/30(ML常用的批量标准化),在两个数据处理量大的任务,包括自动标注和占用空间计算,DOJO的效率可以达到A100(GPU)的3.2和4.4倍,过去GPU需要花费数月才能完成的训练任务,DOJO仅仅只需数周时间。
对于自动驾驶产业而言,驾驶场景数据收集、数据训练优化模型、模型反馈至车端进行测试和错误场景数据收集、再次进行模型训练优化,如此闭环过程是实现自动驾驶目标的唯一路径,因此云端的训练效率只有达到又快又好,才能给消费者更好的辅助乃至自动驾驶体验。
美国政府对Nvidia的芯片进行了禁运,对于中国的自动驾驶产业而言,如果在训练芯片环节无法得到硬件突破,将会影响整个产业在全球的竞争力,这是一个无法回避的问题。
对于全球AI产业而言,芯片、加速核的合计层出不强,但如何在I/O、内存、系统封装,乃至编译器等硬软件环节做到全局优化,才是AI产业核心竞争力的体现,毕竟数据、算力和算法缺一不可,这一点对于我们寻找具备真正竞争力的AI企业是一个非常好的系统视角和分析框架。风险提示:
本文件非基金宣传推介材料,仅作为本公司旗下基金的客户服务事项之一。本文件所提供之任何信息仅供阅读者参考,既不构成未来本公司管理之基金进行投资决策之必然依据,亦不构成对阅读者或投资者的任何实质性投资建议或承诺。基金有风险,投资需谨慎。本文所载的意见仅为本文出具日的观点和判断,在不同时期,瀛赐基金可能会发出与本文所载不一致的意见。本文未经瀛赐基金书面许可,任何机构和个人,不得以任何形式转发、翻版、复制、刊登、发表或引用。

END
人
本文作者可以追加内容哦 !

