
在当今快速发展的科技领域,算力已成为推动人工智能(AI)等前沿技术前进的重要引擎。为了应对日益增长的算力需求,彩讯股份推出了RichMoss超大规模算力集群管理平台,该平台以其卓越的性能和全面的管理功能,正在逐步改变AI计算集群的管理方式。
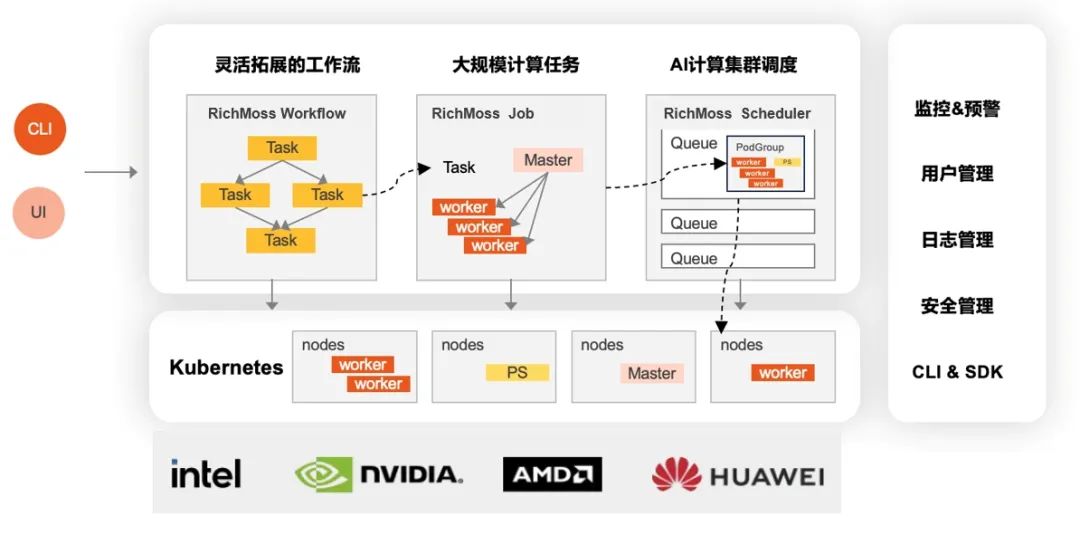
先进的AI 计算集群调度器,提升算力利用率

RichMoss平台专为AI计算集群设计,提供运行大规模工作负载所需的高级调度功能,包括任务队列、配额、优先级、自动抢占/恢复、协同调度及拓扑结构感知等,便于用户充分利用集群计算资源进行规模化 AI 开发和部署等。
平台允许用户根据具体业务目标灵活定制调度策略,通过实时监控、队列管理、优先级调控以及自动抢占作业等机制,实现对集群资源使用的精准把控;能够灵活调度具有多种特性的工作负载,高效利用GPU等高成本集群资源;通过弹性分配工作负载和自动回收闲置资源的方式,进一步优化计算资源利用率,确保每一份资源都能得到最大化的价值体现。
灵活扩展的工作流系统,复杂大规模计算工作流自动化
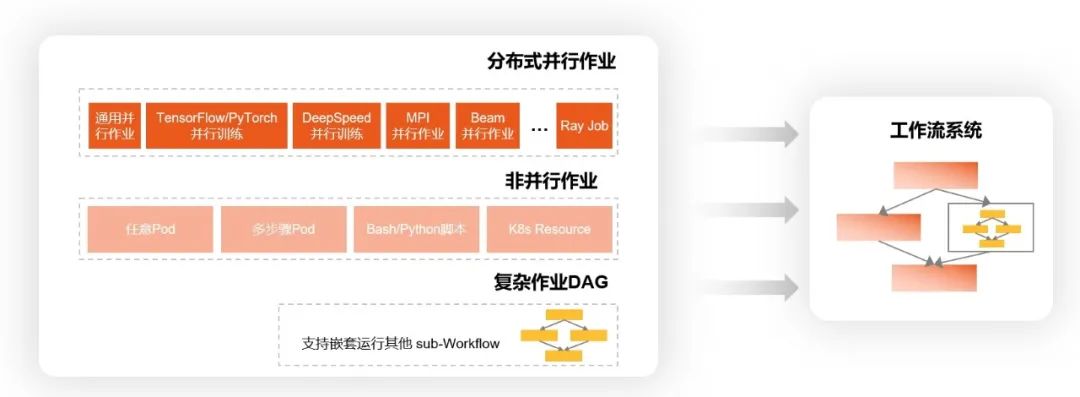
RichMoss平台能够把复杂的计算步骤灵活地组合在一起,进行统一管理和调度,在集群中实现复杂大规模计算工作流自动化。
可编程:Workflow 服务允许高度的灵活性,用户可以将一些基础任务组装成复杂的计算图,并使用条件分支、失败重启等高级功能。
可重用:用户可以编写任务模板,并在每次运行时为其提供不同的参数,达到一次编写、多次调用的目的,提高应用的模块性和代码的重用率,避免重复工作。
可扩展:Workflow 服务充分利用云原生架构的开放性和统一性,允许用户在任务中创建定制计算任务并管理其运行,极大拓宽了工作流的扩展性。
自动化集群管控运维,毫秒级故障恢复
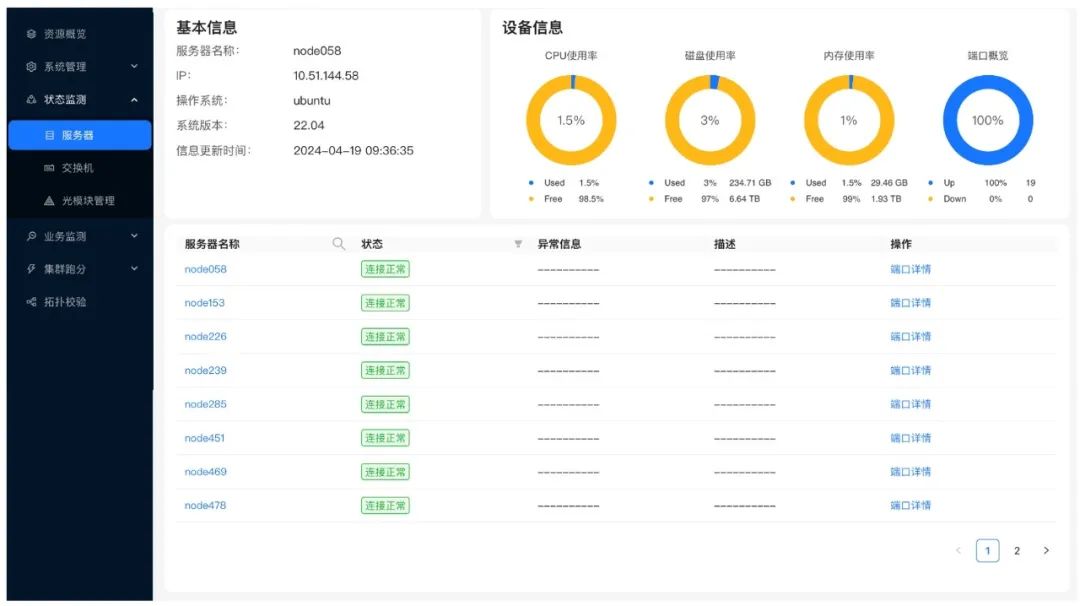
RichMoss算力集群管理平台通过自动化集群管控与运维,实现了对计算任务日志和运行指标的全面收集与存储,提供了定制告警规则、交互式查询、故障自动恢复、可视化展示等功能,确保了对计算任务的全方位观测与管理。
平台的监控能力覆盖了CPU、Memory、GPU、网络、存储等资源分配、使用模式、工作负载运行时间和成本等全局视图,可视化的界面提供,及各种计算任务的监控和管理等。内置专业的大模型训练监控模型,能够精准监控训练过程中的各项指标,及时发现异常,提高故障响应效率;自动化运维系统结合RichNet底层网络的稳定性和高容错性系统的容错恢复时间缩短至1ms以内,保证生产环境的高容错可用。
万卡集群管理,异构GPU集群调度
RichMoss平台提供了一套全面的计算集群管理功能,可以实现国际英伟达及国产华为、寒武纪、燧原、壁仞等GPU集群管理,支持GPU算力资源池化,实现异构GPU集群管理,广泛覆盖各类AI计算场景。支持多用户、多团队的环境下,资源的灵活隔离与共享。用户可以根据实际需求,为不同团队分配独立的资源池,确保资源的高效利用与安全性。同时,团队成员之间也能根据权限设置,实现资源的共享与协作,进一步提升计算资源的利用率与工作效率。
彩讯股份RichMoss超大规模算力集群管理平台已在多个项目中成功落地,为智算中心、人工智能企业以及证券公司等提供了强大的算力运维调度管理及性能调优服务,确保了数据处理和模型训练的高效率与高质量,为AI业务的顺利开展提供了高效、稳定的算力保障。
推荐阅读





