作者 | 程茜
编辑 | 漠影
智东西12月13日报道,今天,国产“算力黑马”之一英博数科亮出了英博云全系产品、服务升级成果,可以概括为一大标准+高效益、多样化的GPU智算产品与服务。
一大标准指的是企业在成本效率、资源利用等维度的成本评估框架——“单位有效算力成本”,这可以成为企业评估计算资源实际效率的参考,也为智算行业的透明化、高效化和可持续化提供了可行的路径。
高效益、多样化的GPU智算产品与服务,包括面向万卡集群大规模训练需求的智算中心建设运维、能满足弹性算力需求的GPU容器服务、评估关键指标的先进算力实验室、联合产业上下游的产业孵化器四大维度。
从评估标准、算力服务到科学评估服务,英博数科作为鸿博股份的全资子公司,承载着集团科技专项发展的重任,并已经在智算行业的加速变革下形成了全面的业务支撑。
大模型产业发展至今,从最初ChatGPT爆火,到如今AI应用加速落地,图片、视频、3D等多模态模型涌现,再到2024年临近尾声,OpenAI、谷歌、亚马逊、Meta纷纷亮出年末大招,又在大模型掀起新热潮,都将这一产业的竞争推向新的高度。
在这之中,算力、算法、数据三驾马车并驾齐驱之际,算力层面的企业需求正在发生变化:从单纯考量算力规模转移到如何用好算力、充分释放算力的价值,这对算力提供商提出了更为严峻的考验。
在此背景下,智东西等媒体在发布会前期,与鸿博股份CFO兼英博数科CEO浦威、英博数科CTO李少鹏、英博数科副总裁宋琛、英博数科副总裁秦伟俊进行了深入交流,从英博云的新发布出发,探寻智能算力产业的高效发展之路。
一、从基础模型到AI应用,智算产业三大趋势凸显
算力作为数据处理和算法执行的关键驱动力,今年以来,业界的关注焦点也在发生变化。
从算力提供方以及企业需求方来看,目前有三大明显的趋势:
首先,通用大模型训练算力集群从千卡移向万卡。
此前被视为大模型“金科玉律”的Scaling Law发展正在放缓成为业界热议的焦点,综合来看,尽管预训练有放缓趋势,但正如李少鹏所言,相同算法、相同架构条件下,模型规模与性能表现往往是成正比的,因此“从第一性原理来看,Scaling law不会失效”。在一定阶段内,算力需求的持续增长仍毋庸置疑。
再看通用大模型的参数量发展,已经从千亿级向万亿级迈进,随着硬件技术的进阶,使得构建万卡集群具备可行性。海外GPT-4大模型需要用25000张A100 GPU训100天、Meta推出2个24576张H100集群、马斯克曾自曝新版Grok 3训练用了10万张H100 GPU……
可以说,未来做通用模型,万卡级别已成必备门槛。
其次,垂直大模型训练算力使用从定量移向弹性。
不同于通用模型,垂直模型业务往往具有较强时效性和不确定性,以金融行业的风险预测为例,市场波动频繁才是其高频使用的场景,市场相对稳定其算力需求相对较低。
因此,其算力分配的规模和频率可能会随时间、业务场景而变化,定量的算力配置难以灵活应对这种变化。
而弹性算力模式的供给,既能让企业根据实际训练需求动态调整算力资源,在训练任务低谷期减少算力租用,避免不必要的成本支出;在高峰期则能快速扩充算力,确保训练任务按时完成,从而在高效利用算力资源的同时控制成本。
最后,算力需求正从训练转向推理。
大模型加速落地应用已经成为共识,其应用场景已经从科研维度向医疗、金融、交通等行业扩展,而这些实际场景中,大模型推理阶段的算力需求更为突出。
在业务端,AI助手、聊天机器人等需要快速响应客户请求,并实时对大量传感器数据进行处理、计算,以支撑其做出准确、科学的决策反馈。
但鲜明的产业趋势背后,对算力提供方提出的挑战也不可小觑。
构建万卡智算集群,需要解决硬件、软件等诸多挑战。如大量加速卡之间的高速互联、稳定可靠的硬件系统、具备容错能力的软件架构、有效的故障检测机制、优化和适配的训练算法、提高能源利用效率……
同时,弹性算力为算力提供商的技术积淀提出了更高要求,其需要整合云计算、虚拟化、容器、异构计算等多种技术,同时要兼顾数据管理、传输,在如此复杂的系统架构下完成运维和管理。
最后推理阶段的算力要求最直观的就是——响应要快,不同于训练阶段,推理阶段用户对延迟的容忍度更低,需要在短时间内得到响应,因此需要算力集群能通过提升网络带宽和存储系统的性能,以兼顾数据的快速传输、数据安全等。
因此,算力提供方如何提供更好用的算力、企业如何选择合适的算力,成为横亘在二者之间的鸿沟。
二、算力高效利用迫在眉睫,率先定义“单位有效算力成本”
目前,尽管万卡集群的建设正高歌猛进,各家都亮出了弹性算力提供方案,但企业应该如何选择这件事,尚未得到解决。
从企业端的需求来看,当大模型走向千行百业,企业选购算力的重点也随之转移,从更注重算力规模到算力的有效利用率。
那么,业界是否有直观的数据指标,能将这一评估标准直接呈现出来,以供企业能快速准确的选到高性能、性价比的方案?答案显然是还没有。
浦威做了一个形象的比喻,就像在高速路上开车载荷货物,只有车的马力跑足、货物装满,才能把实际支出的“算力”充分利用起来。 在此背景下,英博数科提出了一个定义“单位有效算力成本”的新标准:
具体来看,这一公式的分子是设备成本、机电成本、运维成本组成的算力投入成本,分母是装机算力、卡可用率、卡利用率及模型算力利用率组成的有效计算能力,通过这两个参数的系统比较,得出单位有效算力的成本。
李少鹏进一步解释说,这一标准制定背后,他们综合考虑了成本、实际装机算力、训练过程折损、模型框架选择、模型训练的时间长度和效率整个链条。
其中,算力投入成本中采购服务器的设备成本是固定的,此外智算中心的日常使用需要企业支付机房租赁以及电力的费用,同时需要人力运营、维护,避免其出现故障,因此,最终成本源头就组成了这三块。
分母指的就是企业得到的有效算力,由于装机算力即设备厂商标定的额定算力会因为各种因素被折损。
在运维技术或者条件不完善的情况下,卡会存在很高的故障概率,也就是说假设装机算力达到1000P,但实际可用的算力可能只有900P。
卡利用率指的就是GPU卡真正为企业所用的效率,正如前文所述,垂直业务场景中,对GPU算力的需求并不是稳定且持续的,因此在非业务场景下GPU卡会空闲下来。
最后是模型算力利用率,这是针对GPU做大模型训练和推理的重要指标,其是实际有效利用算力资源与所提供总算力资源之间的比例关系。
这四大关键要素相乘作为整体的分母,企业的算力投入成本相加作为分子,就将“单位有效算力成本”这件事评估清楚了。
回过头来看,当下企业关注应用算力效率问题这件事,其实并不是一个新鲜话题,相关的讨论也异常火热,目前从相关标准的讨论焦点来看,机房算力、运营、网络、存储、环境等问题的分析非常多,却缺少一个逻辑链将这些因素串联起来。
英博数科为什么做到了?浦威点出了问题的关键——因为英博数科将这一条链路端到端经历过。从智算中心建设、机房选型到集群建设、交付,到模型训练等环节,都已经呈现在其业务体系中。
不论从成本还是效率来看,算力的高效利用都迫在眉睫,“如何用好算力”在当下更为关键。站到算力产业新的发展节点,英博数科要在“提高算力有效利用率”上做文章。
而基于上面这一标准,当算力需求端和供给端形成共识,这是算力产业良性发展的前提。李少鹏补充说,企业可以根据这一标准快速估算自己的成本以及对应的需求,从而找到适合的方案。
因此,英博数科高效益、多样化的智算产品、服务方案就应运而生了。
三、高效益、多样化智算产品+服务,释放更多有效算力
“单位有效算力成本”新标准,已经成为英博数科产品与服务体系的基准。
今天,英博数科推出英博云——高效益、多样化的GPU智算产品与服务,成为大模型智能水平进阶以及落地应用的重要基础设施。
在此之上,其产品包括面向万卡集群大规模训练需求的智算中心建设运维、能满足弹性算力需求的GPU容器服务、评估关键指标的先进算力实验室、联合产业上下游的产业孵化器四大业务。
从直接的算力提供方案来看,宋琛提到英博数科关注的两点,一方面是对大模型训练本身有集群规模建设的头部大模型客户,其会基于本身的集群建设和运维经验,提供量身定制的集群选型、建设、运维到整体解决方案;另一方面是,对中小型客户的弹性算力需求,其推出了容器云服务。
其中,智算中心建设运维就是面向万卡集群的大规模训练需求,英博云会为企业提供自研的高性能并行存储解决方案、硬件测评和检测体系、系统运维和硬件维修体系、细粒度的集群监控和故障自动化恢复体系、算力调度平台。
做万卡甚至十万卡规模的集群,需要将所有卡组在一张计算网中,涉及整体的设备、交换机、光模块、光纤选型,对于非AI基建领域的专业玩家挑战很大,而这正是英博数科技术积累发挥优势的机遇。
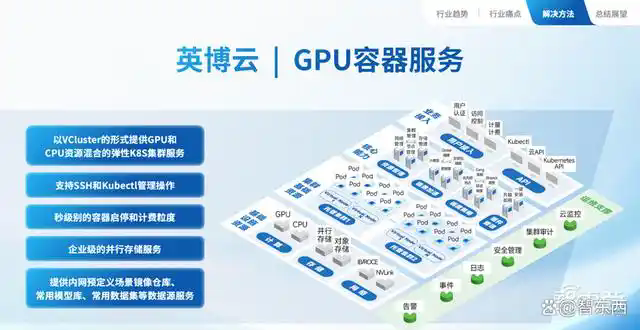
GPU容器服务可以满足弹性算力需求,包括以VCluster形式提供GPU和CPU资源混合的弹性K8S集群服务、支持SSH和Kubectl管理操作、秒级别的容器启停和计费粒度、企业级并行存储服务、提供内网预定义场景镜像仓库、常用模型库、常用数据集等数据源服务等。
容器云的难点在于,需要精准分配和管理算力资源,以适应企业进行大模型训练和推理不同阶段的算力需求,且需兼顾数据的高效存储、管理以及高效的网络通信、高效的并行和分布式训练等。而英博云的产品将面向客户提供按需使用的算力,甚至可以精确到按小时、按分钟计费,按CPU任务或GPU任务等,因“单位有效算力成本”的标准之下,企业的算力成本也会更为可控。
产品之外,服务体系也是链接企业需求与算力供应形成科学互动的关键,也就是英博数科的算力实验室扮演的角色。
宋琛谈道,算力实验室聚焦的领域有两个,测评市面上的主流算力卡,以及测评和适配国产算力卡并进行异构算力平台开发工作。
先进算力实验室围绕硬件评测、软件评测以及行业服务展开工作,为企业算力基础设施的升级与优化提供前瞻先进、切实可行的建议。比如在硬件评测方面,实验室会对GPU、交换机、光模块、并行存储等进行严格测试,确保设备性能符合高标准;在软件评测方面,围绕基座模型、训练框架、微调框架、推理框架等,为智能算力的优化提供全方位支持。通过提供行业标准制定和定制化服务,先进算力实验室会帮助企业在智能算力领域不断突破创新。
投资层面,英博云正在联合AI产业上下游,探索算力组合投资新模式,宋琛提到了产业孵化器的形式,英博数科会对AI应用领域的新兴创企,提供资金、算力、人才培养等帮助。
综上所述,英博云此次的智算产品与服务升级,集万卡集群构建、算力提供方式、评估体系于一体,将智能算力服务的供应体系串联了起来。
想要做到这些非一日之功,这都得益于这家国产“算力黑马”深厚的技术积淀与商业化经验。
英博数科的核心成员出身清华、北大等名校及头部互联网、AI与云计算企业。
就在上周,英博数科智算中心建设运维解决方案已在京能项目落地,据悉,英博数科在智算中心建设运维方面拥有的独特优势,成为推动京能项目持续进展的核心力量。
这些已经成为其面向智算产业变革的行业浪潮之下,打造行业护城河的重要支撑。
如今,算力在AI产业中的地位举足轻重,现下的产业命题正是如何紧跟大模型产业的发展趋势,使得算力在企业之间高效流转起来,英博数科的战略升级,使得其成为当下这一产业链中算力赋能者。
结语:算力先锋,AI全链进化的强劲引擎
随着AI技术不断向纵深拓展,从基础模型的构建到复杂算法的训练与优化,每一个环节都离不开强大算力的支撑。
英博数科在算力基础设施建设方面投入巨大且已经成果斐然,此次产品与服务的全面升级,也是其面向算力产业变革的趋势下交出的最新答卷。
在AI应用加速落地的当下,算力基础设施提供商正与大模型玩家、企业应用方形成合力,为AI大规模应用落地不断注入新动力。




本文作者可以追加内容哦 !

