近两年,检索增强生成(RAG,Retrieval-Augmented Generation)技术正在成为提升大模型性能的关键工具。RAG技术通过引入外部知识,结合检索与生成的双重能力,为大模型在复杂场景中的应用提供了更多可能性。无论是文档解析的质量、上下文信息的精确性,还是针对任务的合理规划,RAG的每一步都在为模型能力的上限奠定基础。
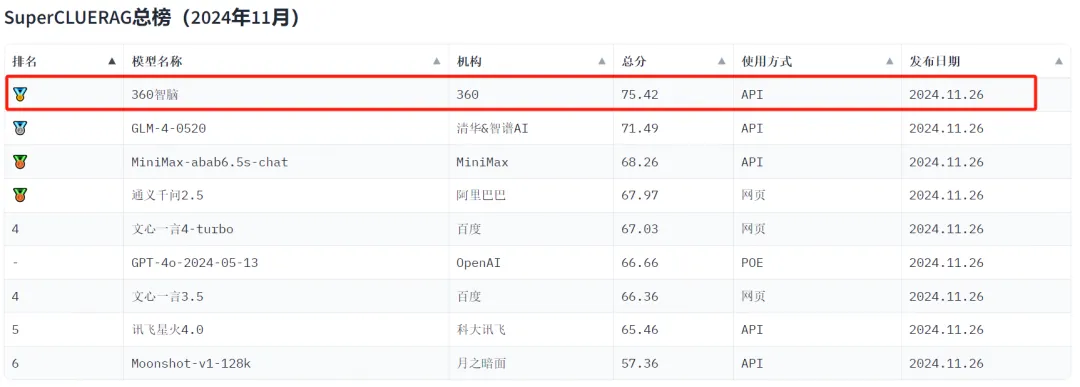
2024年11月,360智脑团队自研RAG在中文评测基准SuperCLUE-RAG专项榜单中表现优异取得榜单第一,本次评估是自研RAG技术与360GPT-Pro模型结合,在各项子指标上表现均衡。验证了360智脑在RAG技术优化上的实践价值,为复杂场景下的大模型应用提供了参考范式。
2
为什么大家这么关注RAG技术?
2.1 大模型为什么需要RAG?
在大模型(LLM)落地过程中,存在诸多挑战,如缺乏企业私有知识存在幻觉问题、训练周期长成本高、知识更新不及时的问题以及模型的黑箱属性缺乏可解释性的问题等。而RAG(Retrieval-Augmented Generation,检索增强生成)技术的引入,可以有效地解决这些问题。
LLM缺乏企业的私有知识,存在严重幻觉问题。大模型通常基于互联网公开数据进行训练,难以涵盖企业的私有知识。RAG技术通过构建企业私有知识库,实现私有知识注入,使得模型能够更好地服务于企业的具体需求。
LLM训练周期长成本高,存在知识更新不及时。大模型的训练周期长且成本高,更新知识需要耗费大量资源。通过迭代管理知识库内容,RAG技术能够实现知识的快速更新,而无需重新训练整个大模型,从而大大降低了成本和时间。
LLM属于黑箱模型,缺乏可解释性。大模型的黑箱属性使其回答缺乏可解释性。RAG技术可以显示答案的引用文档信息,提高了回答的透明度和可解释性,让用户可以追溯答案信息的来源,增强了模型的可信度。
2.2 RAG的定义和作用
RAG,全称为Retrieval-Augmented Generation,是一种结合了信息检索(Retrieval)和文本生成(Generation)的技术。具体来说,RAG模型在生成回答时,不仅依赖于预训练的语言模型,还会从一个大型的文本库中检索相关的信息,以增强生成的准确性和丰富性。这种方法通过引入外部知识,弥补了单纯依赖生成模型时可能存在的信息不足和错误。
RAG模型通常包括两个主要组件:
检索器(Retriever)。负责从预定义的文档集合中检索与输入查询相关的文档或片段。
生成器(Generator)。利用检索到的文档或片段作为上下文,生成连贯且与查询相关的回答。
这种方法的优点在于,它能够利用外部知识库中的丰富信息来增强生成模型的表现,从而生成对输入查询更有针对性、更相关的内容。
2.3 RAG典型的应用场景

3
360智脑RAG方案
在RAG发展迭代演进过程:逐步经历了基础RAG、高级RAG和模块化RAG。RAG通常又包括三个阶段:建库阶段、检索阶段、生成阶段。以下是360智脑RAG的整体架构图。
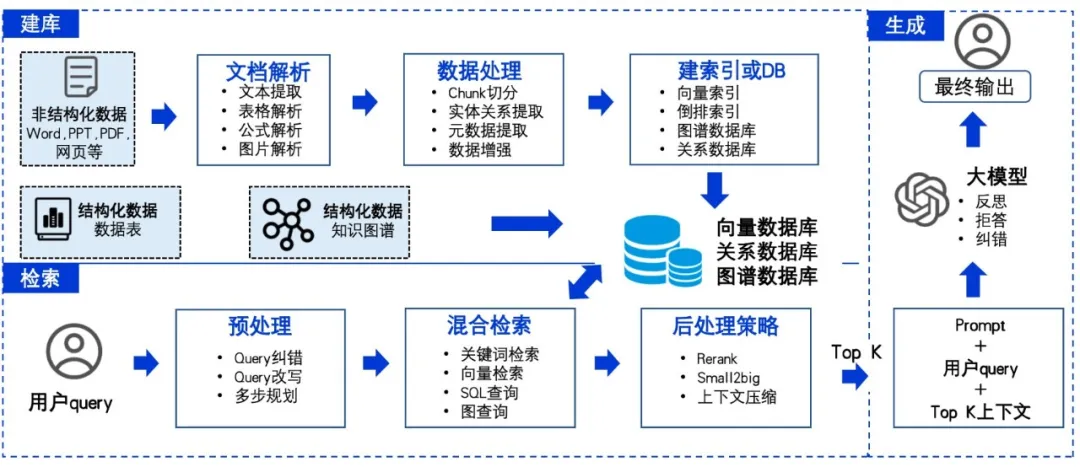
图7: 360智脑RAG技术架构图
快速搭建一个RAG demo很简单,但要在真实业务场景上进行落地并取得好的效果往往比较难。根据360智脑RAG的迭代经验,总结出做好RAG的六大观点:
观点1:文档解析的质量决定了RAG能力的上限
在RAG过程中,文档解析起着至关重要的作用。
首先,文档解析能够有效地提取和理解文档中的关键信息,从而为后续的信息检索和生成提供准确的基础。
其次,通过对文档的深入解析,可以更好地捕捉上下文关系,使得生成的内容更加连贯和符合逻辑。
此外,精确的文档解析还能够帮助识别和过滤噪音信息,确保检索到的内容具有高质量和高相关性。
总之,文档解析是RAG过程中不可或缺的一环,它直接影响到信息检索的效率和生成内容的质量。
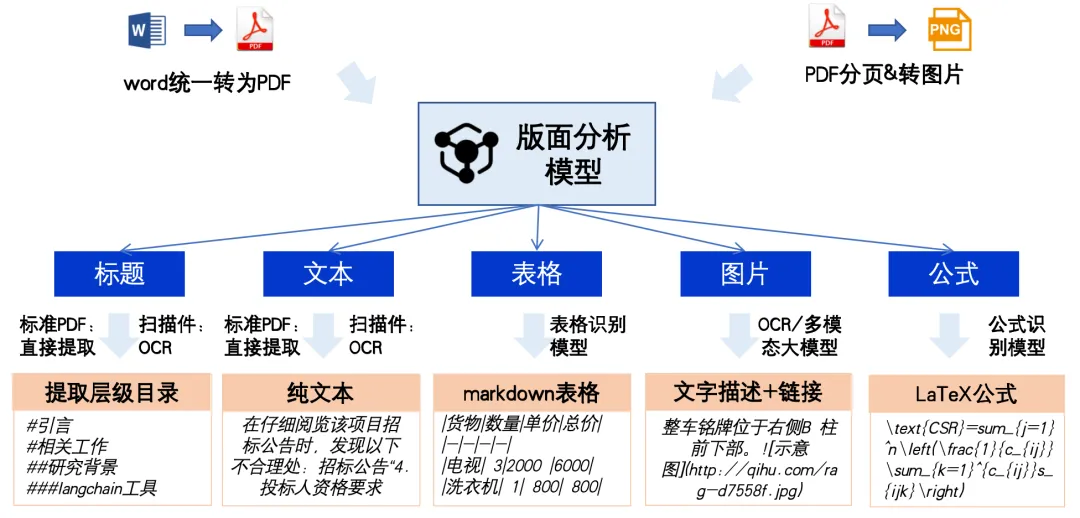
图8: 建库关键技术之文档解析
在文档解析过程中,我们通常会遵循以下几个步骤。
第一步,文档统一会被转换成PDF格式。
第二步,PDF文件会被分割并按页渲染成图像,以便后续的图像处理和分析。
第三步,我们会使用版面分析模型来识别文档中的各种元素,如标题、正文、表格、图片、图表和公式等。
第四步,不同的元素再用不同的模型识别处理,如标题和文本用OCR模型识别;表格用表格模型识别还原数据;公式用公式模型识别出latex公式。
最后一步,这些识别出的元素会按照阅读顺序进行排序,并输出为markdown格式,以便于进一步编辑和使用。通过这些步骤,我们能够高效地解析和处理各种复杂的文档。
观点2:细粒度、语义级、边界精确的文档切片对RAG至关重要
在RAG过程中,chunking方式的选择至关重要。
第一点,chunking可以将大段文本拆分成更小的、易于管理的块,从而提高信息检索的效率。通过合理的chunking,可以确保每个块包含足够的信息,使得生成模型能够更准确地理解和生成相关内容。
第二点,chunking有助于减少噪音和冗余信息的干扰,使检索结果更加精确和相关。
第三点,适当的chunking还可以优化计算资源的利用,减少处理时间和内存消耗。因此,chunking方式在RAG过程中不仅影响信息检索的质量,还直接关系到整个系统的性能和效率。

图9: 建库关键技术之切段
先根据文档的篇章目录结构对文档进行初步的语义切分。这一步的目的是将文档按照自然的段落或章节进行划分,使每个部分都有明确的主题和内容。这种结构化的划分有助于后续的处理和信息检索。接下来,对于每个初步切分后的段落或章节,如果其长度超过了预设的限制(例如,超过特定的字数或句子数),则需要对其进行递归切分。这一步的目的是确保每个文本块的长度在可控范围内,以便后续的处理和生成过程能够高效进行。
观点3:针对文档内容的多样化数据增强策略是一种有效的提升RAG效果的方案
在RAG建库阶段,数据增强对于提升检索效果至关重要。
生成QA对。通过根据内容生成QA对,可以丰富数据的语义信息,使得模型在回答问题时更加准确。
生成摘要。对片段做摘要总结,有助于提取关键信息,提高检索效率和准确性。
添加元数据。提取日期、页码等元数据,可以为检索提供更多维度的信息,方便用户快速找到所需内容。
构建知识图谱。提取实体和关系并构建知识图谱,能够将数据中的隐含关系显性化,增强模型的理解能力,从而提升整体检索效果。
通过这些数据增强手段,可以显著提高RAG系统的性能和用户体验。
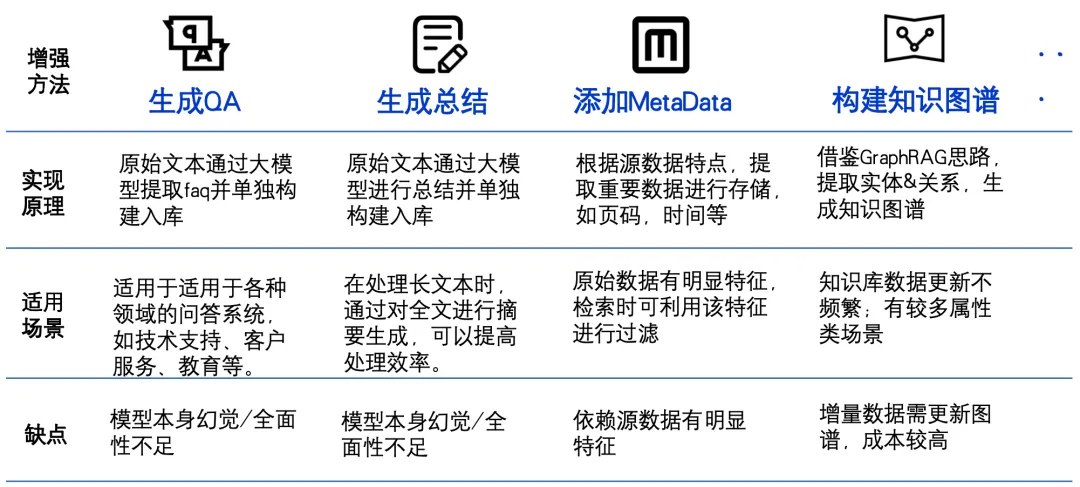
图10: 建库关键技术之数据增强
观点4:准确的query理解和任务规划策略对于RAG召回至关重要
检索策略的选择对结果的准确性和相关性至关重要。
首先,query纠错、指代消歧和query改写能够帮助系统更好地理解用户的意图,通过将原始查询转换为更易于处理的形式,提高检索效果。
其次,泛化子查询可以扩展查询范围,确保涵盖更多潜在的相关信息。query意图判定则是通过分析用户查询背后的真实需求,进一步优化检索结果。
最后,回溯提示功能允许系统先考虑层次的概念和原则以解决复杂问题。这些查询策略的综合应用,能够显著提升RAG系统的性能和用户满意度。

图11: 检索关键技术之检索策略和query预处理策略
观点5:精确、丰富、完备、不含噪声的上下文信息对大模型是友好的
使用较小的文本块可以显著提高检索的准确性,因为较小的块能够更精确地匹配查询内容,从而提供更加相关的检索结果。然而,在生成阶段,使用较大的文本块则能提供更多的上下文信息,帮助生成更加连贯和详尽的回答。此外,确定合适的上下文边界同样重要,避免包含主题无关的内容,以确保生成内容的准确性和相关性。以下是关于如何通过 RAG Small2Big 扩展上下文的方法:
通过chunk召回相关片段。将原始文章分成多个小块(chunk),每个小块包含一定数量的句子或段落。检索阶段可以有效地找到与当前内容相关的上下文信息。
通过文章的篇章标题结构确定上下文边界。在扩展上下文时,考虑文章的整体结构,特别是篇章标题。这有助于确定各部分内容的主题和边界。确保召回的片段与当前段落所在的章节或小节内容一致,从而保持上下文的连贯性和逻辑性。
通过NLP技术过滤掉无关噪声片段。采用技术如:1) NLI模型过滤,通过训练独立的NLI模型对召回结果进行语义相似性判断,保证性能的同时可有效过滤无关内容;2)实体识别过滤,通过提取query和召回question里的实体,维护实体+别名库,可实现别名的召回以及关键实体缺失的过滤;3) 规则引擎过滤,实际应用中总有一些corner case覆盖不到,通过规则引擎运营自定义规则,来实现干预处理,常见的规则,如完全精确匹配、包含匹配、正则匹配、模糊匹配(语义匹配)。
在扩展过程中,注意保持语义的完整性,避免引入无关或矛盾的信息。
观点6:用好慢思考能力,推理和反思能够帮助RAG提升能力上限
推理和反思起着至关重要的作用。
第一,进行查询预处理是整个过程的基础,通过对查询进行优化和标准化,可以提高检索的准确性和效率。
第二,任务规划是关键步骤,它决定了如何有效地组织和调度检索任务,以确保高效利用资源。
第三,在生成初步结果后,反思阶段尤为重要,通过对生成内容进行审查和评估,可以发现潜在的问题和改进点。
通过多轮迭代,不断进行推理和反思,可以逐步提升结果的质量和可靠性,最终获得高质量的输出。
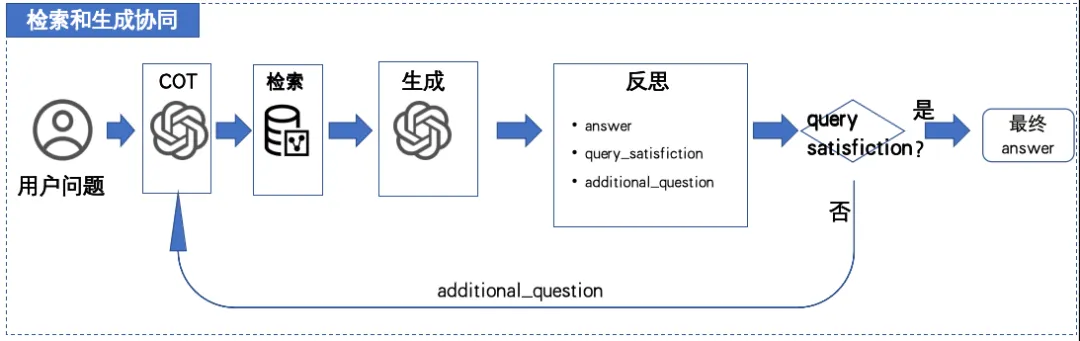
图12: 检索和生成协同进行推理和反思
在用户输入问题后,LLM模型先对问题进行分析和规划,这个过程被称为链式思考(Chain of Thought, COT)。COT帮助模型分解问题,确定需要检索的信息类型和生成答案的步骤。之后,模型会进行信息检索,从预定义的知识库或文档集中提取与问题相关的内容。这一步确保模型能够访问到最新和最准确的外部信息。
在完成信息检索后,LLM模型将检索到的内容与自身的生成能力结合起来,生成一个初步的答案。这个生成过程不仅依赖于检索到的信息,还利用了模型的内在语言生成能力,以确保答案的连贯性和流畅性。
最后,LLM模型会对生成的答案进行验证和反思。验证步骤包括检查答案的准确性和一致性,而反思则是对生成过程进行评估,找出可能的改进点。这一循环过程使得RAG能够不断优化其问答能力,提供更加精确和有用的答案。
4
总结
文档解析的质量决定了RAG能力的上限。
细粒度、语义级、边界精确的文档切片对RAG至关重要。
针对文档内容的多样化数据增强策略是一种有效的提升RAG效果的方案。
准确的query理解和任务规划策略对于RAG召回至关重要。
精确、丰富、完备、不含噪声的上下文信息对大模型是友好的。
用好慢思考能力,推理和反思能够帮助RAG提升能力上限。
5
欢迎体验
360智脑RAG能力已广泛应用于360公司内外部业务,并已在360智脑API开放平台开放使用,欢迎体验!
360智脑API开放平台:
https://ai.360.com/platform/datasets/list
360智脑官网:
https://ai.360.com/
本文作者可以追加内容哦 !

