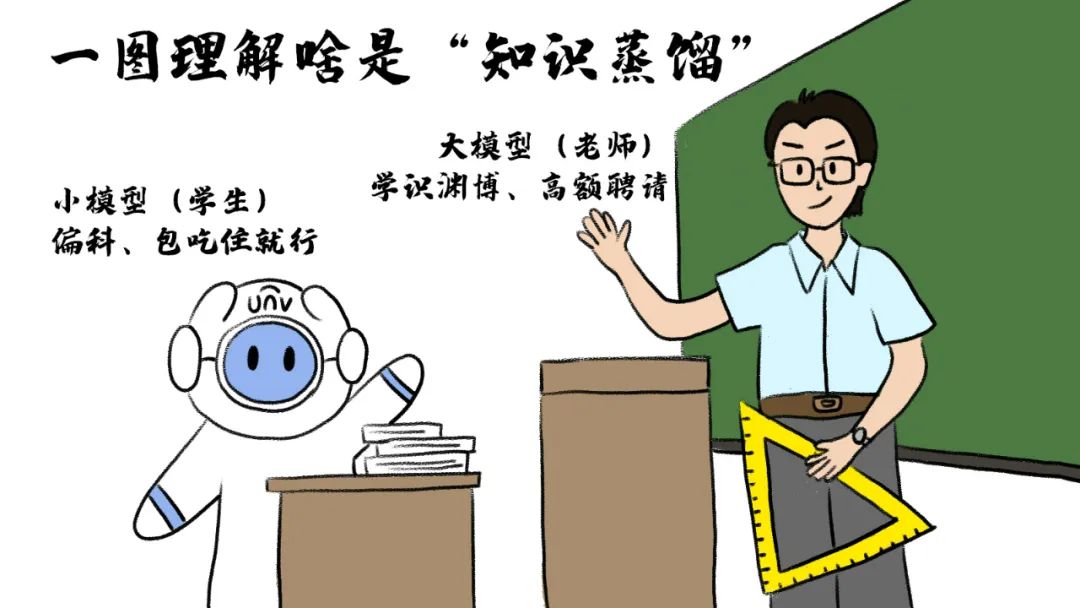
想让新手模型一夜逆袭成学霸?
大模型时代的"偷师绝技":
知识蒸馏(Knowledge Distillation)
不妨了解一下!
啥是知识蒸馏?
先给个一句话概括:
将大模型的关键知识迁移至小模型
即,“浓缩的都是精华”!
既保证精度,又大幅降低运算成本和硬件要求
为啥知识蒸馏这法子便宜又好用?
核心思想其实是“授之以鱼,不如授之以渔”
教师模型不是给你一个yes or no
而是传递决策背后的“思考逻辑”其中有个重要概念:
温度参数(Temperature Scaling)

• T=1 :标准Softmax• T>1 :软化分布,放大次要类别信息
别晕!其实这函数没那么唬人
咱只要大概理解什么是调温度、为什么要调就够用
可以拿喝咖啡来理解:
喝咖啡,你喜欢喝冰的、还是热的?
冰咖啡中的酸、甜、苦等味道在低温下被抑制
只剩下香、或不香,味道分明

图:手握冰咖啡的小U
这就是调低温度的效果:模型直接输出概率
比如判断一张图是猫概率90%,狗10%,其他忽略
而热咖啡因温度高,风味成分能更充分地溶解
此时你能尝到更多细微的味道层次

图:手握热咖啡的小U
这就是温度调高的效果:模型输出的概率更丰富
比如猫60%,狗30%,狐狸10%…
模型不再只关注最可能的答案
而是暴露更多隐藏的可能性
教师模型要把模糊的感觉教给学生模型
而不是只告诉它标准答案
温度T的作用,正是控制老师教知识的“模糊程度”
调高温度让模型更愿意透露自己的不确定感
方便学生偷师学艺
此外的重要概念还有软标签(Soft Labels)、
硬标签(Hard Labels)、双重损失函数……
核心都是通过蒸馏
让大模型提供解题思路,而非直接答案
使小模型学会举一反三,不断优化表现
DeepSeek发布的多个蒸馏模型
正展示了这一过程的实际应用

宇视「万物X」以梧桐大模型为核心技术
融合DeepSeek大模型蒸馏出各种专用模型
既保持高智商
又能塞进各种边、端设备里跑得飞快
适配企业园区、教育医疗、交通运输、
生产制造等多个垂直行业细分场景
万物可搜、万物可控、万物可核、万物可标,
为用户解锁更多创新可能
这种全链路智能引擎搭配客制化“数字助理”
真正将大模型能力下沉至边缘!

技术进阶
蒸馏的分类
【输出层蒸馏】(抄作业型)
通过模仿教师模型的最终输出概率分布(软标签)来训练学生模型。例如,教师模型对一张猫的图片输出“猫:0.8,狗:0.15”的概率分布,学生模型结合硬标签(真实答案)和软标签学习,既能捕捉类别间的关联性,又能保持基础判断能力。这种方式仅需调用教师模型的API即可实现,操作简单且通用性强,适合闭源模型的知识迁移。
【中间层蒸馏】(连解题过程一起学习)
不仅学习最终输出,还模仿教师模型的中间层特征表示,如对图像/文本的内部理解或推理轨迹。这相当于学生不仅抄答案,还要学习解题的详细步骤,从而更全面地继承知识结构。但该方法需要教师模型提供中间层数据或配合诱导推理轨迹,实现难度较高,通常适用于定制化合作场景。
简言之,输出层蒸馏“轻量易用”,中间层蒸馏“深入高效”,两者分别从结果和过程角度实现知识迁移。
本文作者可以追加内容哦 !


