未来的企业竞争,将不再仅仅是数据规模的竞争,而是“高质量、可进化知识图谱”的竞争。
日前,在中国通信标准化协会主办的2025数据资产管理大会数据资产分论坛上,普元信息技术领军人焦烈焱通过《从"治理秩序"到"知识工程":基于知识建模的全要素数据资产构建之道》的主题演讲,结合数据治理从1.0向2.0演进的底层逻辑,详细剖析了这一趋势。

2025数据资产管理大会:普元焦烈焱《从"治理秩序"到"知识工程":基于知识建模的全要素数据资产构建之道》
时代之变:从“做清洁”到“做知识”
数据治理正在经历一场范式转移。焦烈焱在演讲中指出,治理1.0时代的核心诉求是“秩序”,解决的是数据脏、乱、差的问题,追求的是数据的准确性。而治理2.0时代,随着AI和大模型的普及,核心诉求已转变为“知识涌现”,向“知识工程”演进。
“高质量数据集的瓶颈,已从数据本身的准确性,转移到其承载知识密度的丰富性。”焦烈焱强调。在这个新阶段,数据治理不再仅仅是一个物理层面的“熵减”过程(即减少混乱),更是一个驱动价值创造的因果链重塑过程。这意味着,系统不仅要存储数据,更要理解数据与业务、规则、场景之间的深层联系。企业需要从海量数据中提炼出高密度的知识,为AI提供可理解的“燃料”。
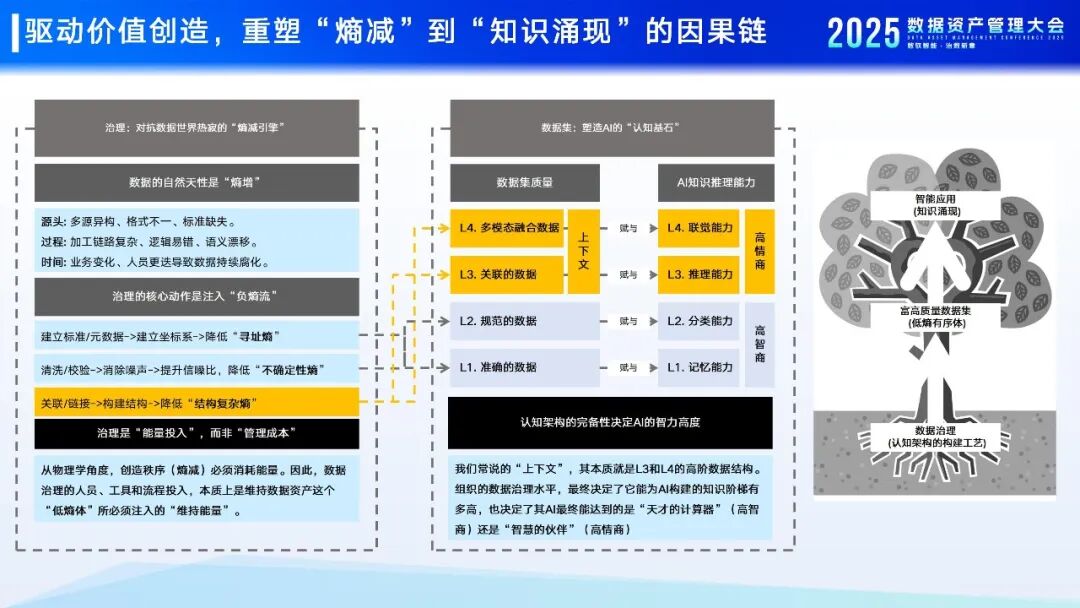
普元焦烈焱:驱动价值创造,重塑“熵减”到“知识涌现的因果链
鸿沟之痛:传统路径遭遇“语义断层”
无论是对行业企业还是政务机构而言,从原始数据到高价值资产,中间都横亘着难以逾越的“高熵原料”与“低熵资产”的转化鸿沟。原始数据往往是无序、高熵的,而业务需要的是有序、低熵的资产。而且传统治理路径往往只关注技术元数据,如表名、字段类型,经常会丢失数据背后的业务含义。
焦烈焱分析道,这正是传统梳理路径的根本症结所在——“语义断层”。仅仅通过扫描数据库表结构,无法还原数据在业务流程中的真实含义。这种“管了数据却不懂数据”的治理模式,导致产出的资产目录往往沦为没人看、没人用的“僵尸文档”。
破局起点:以“知识建模”构建结构化语义基座
如何跨越这道鸿沟?普元给出的答案是:知识建模。
“应用系统是数据‘业务含义’的天然容器与解码器。”焦烈焱指出,普元“易数”平台通过独特的三步走策略,基于业务语义与技术语义形成知识建模。
第一步:业务对象分析。从业务流程出发打破孤岛,还原业务概念模型,明确“数据代表什么业务”,促进数据与业务场景的深度绑定。
第二步:技术元数据采集。融合大模型与自动化标签技术,扫描底层物理数据,获取表、字段等基础信息,有助于将治理工作从高成本的“手工作坊”升级为高效的“智能工厂”。
第三步:应用元数据映射。这是关键一步。普元“易数”通过梳理功能、表、字段的层级关系,将技术字段与业务功能强关联,从海量数据中识别、分类并构建资产目录,以全要素连接激活价值。
通过这一路径,普元协助企业构建从“物理数据”到“领域知识”的结构化核心。这不仅生成了给人看的资产目录,更构建了给AI读的知识图谱骨架,为后续的智能化应用打下坚实基座。治理后的数据不再是静态的“冷数据”,而是能直接被业务系统调用、驱动决策的“活资产”。
价值跃迁:建立企业级的“知识工程”
焦烈焱结合全要素治理体系,展示了公共数据、通识数据、行业专识、企业私有数据等从“结构化”向“非结构化”的熵减扩张,以及构建数据资产全要素治理的“三引擎”协同模型。
结构化数据治理:实现从应用元数据到数据本体(Ontology)的升维。
半结构化数据治理:从僵化的“刚性约束”转向灵活的“柔性自适应”解析。
非结构化数据治理:结合多模态知识图谱,告别低效的“人工贴标签”,迈向“工业级语义锚定”,让文档、图片、日志也能被机器深度认知。
“数据治理是构建企业‘认知架构’的核心工程,而非单纯的‘IT项目’。”焦烈焱总结道,普元通过“易数”数据资产管理平台产品体系,帮助客户做的不只是简单的清洗数据,而是构建企业的“数据智能”进化引擎,为企业的数据资产注入“灵魂”。
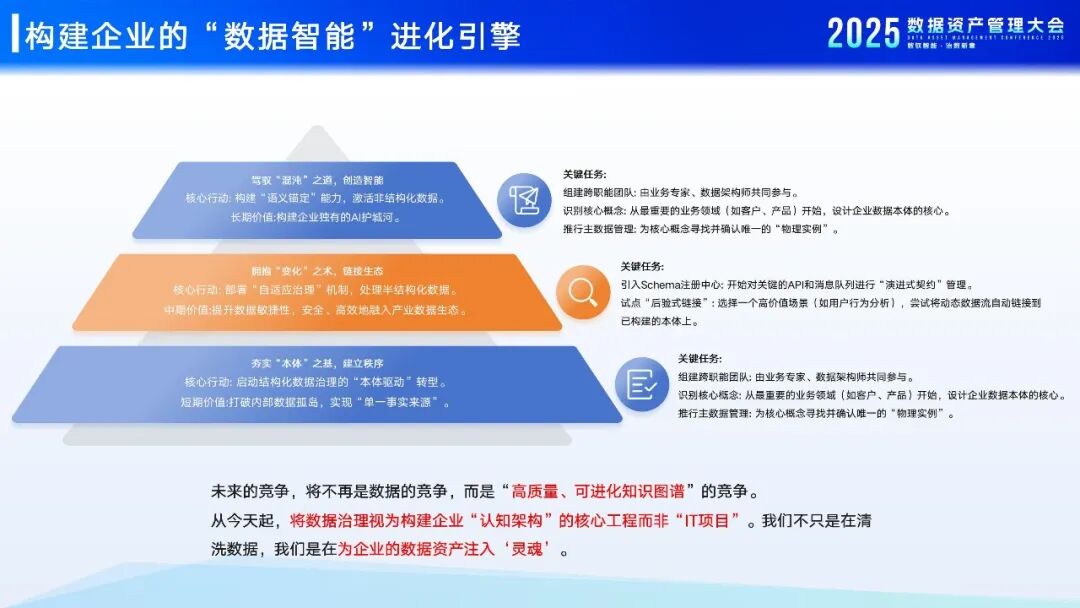
普元支持企业构建“数据智能”进化引擎
数据治理的目标不仅是整齐划一的“秩序”,更是能够驱动业务的“智慧”。面对活跃的数据要素市场,普元已展现出完善的产品与实践储备。从积极探索知识图谱与大模型在治理中的应用,到支撑上海市大数据中心、市场监管局获评“星河奖”,普元正助力行业从单纯的“管好数据”向“用好智慧”进阶。未来,普元将继续以“机器认知”为圆心,通过“易数”平台帮助企业和政府客户构建能思考、会增值的数据资产体系,支撑客户重塑数智化时代的核心竞争力。