砺算科技第二代GPU定位高端游戏显卡和高性能通用计算(训推一体)
基于这两项已公开的专利申请,并结合GPU行业的发展趋势,可以清晰地勾勒出砺算科技第二代GPU可能的研发方向与核心目标:
核心研发方向:构建“高效率、高灵活性的统一计算架构”
两项专利共同揭示了一个核心思路:通过架构创新,在保持硬件简洁(控制面积和功耗)的前提下,最大限度地提升数据处理和指令执行的效率与灵活性。 第二代GPU很可能围绕这一思路,在以下几个具体方向进行深化:
1. 指令与数据流的高度协同与预取
· 目标:打破传统GPU中指令调度、资源访问和数据加载之间的壁垒。
· 实现路径:
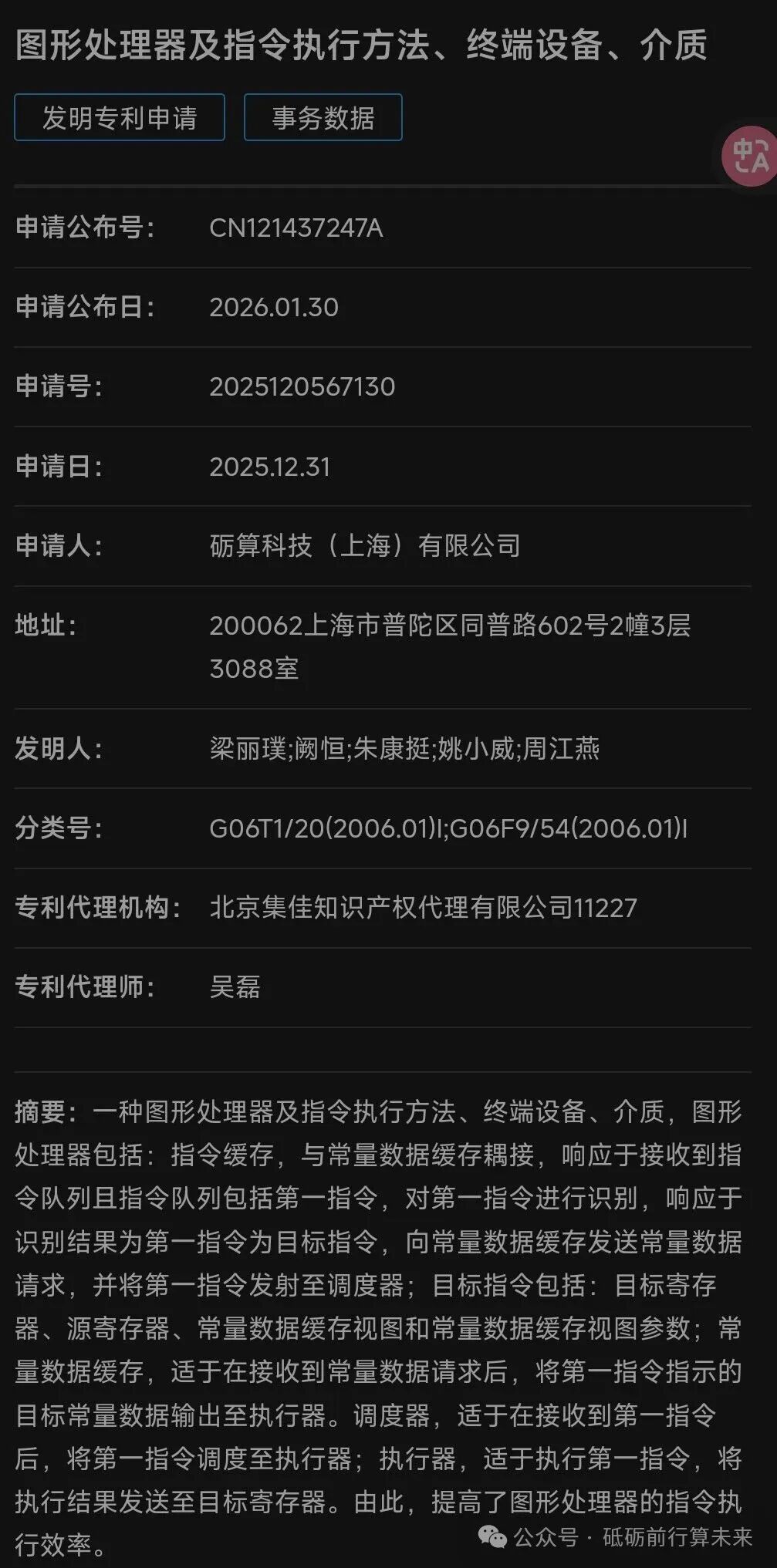
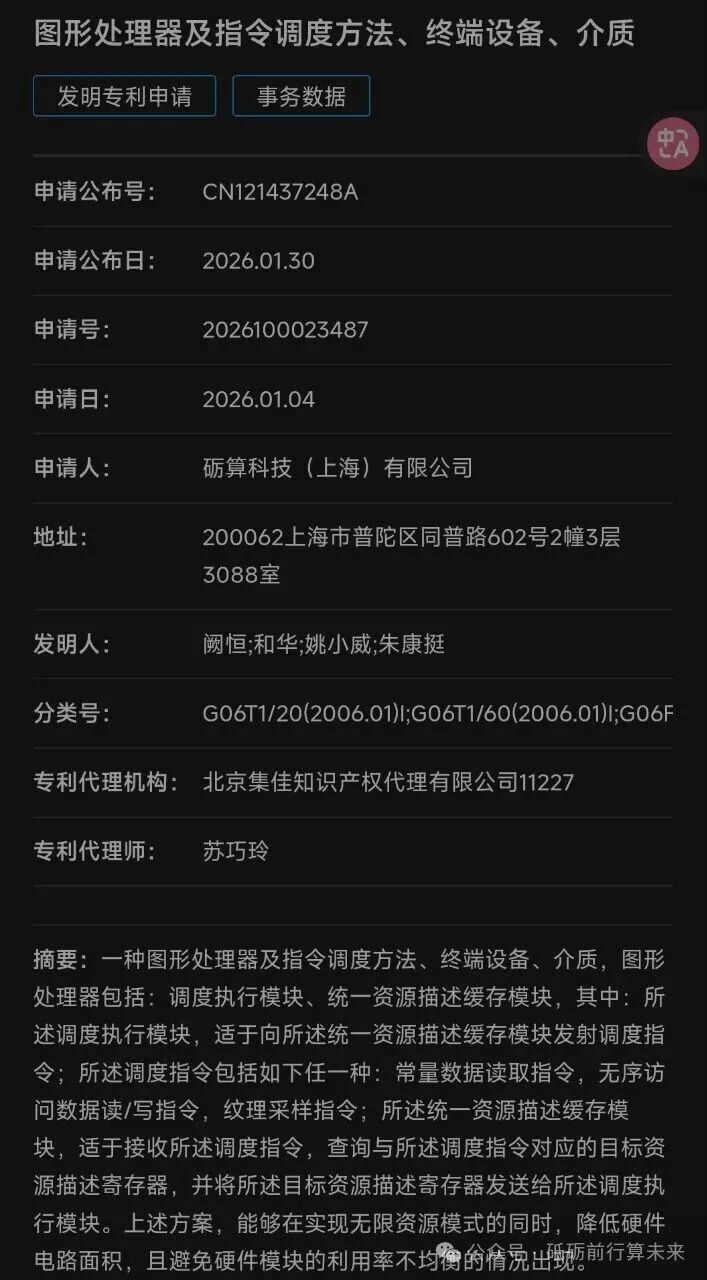
· 将专利一的“统一资源描述缓存”与专利二的“指令-常量数据协同”机制深度融合。GPU可以在解码阶段就预测并提前获取下一批指令所需的所有资源(常量、纹理、缓冲区),实现“指令未到,数据先行”。
· 效果:极大减少着色器核心的等待时间,显著提升计算单元的利用率,尤其对指令密集、数据依赖复杂的现代游戏着色器和AI计算内核有益。
2. 硬件虚拟化与“无限资源”支持的落地
· 目标:让开发者感觉GPU资源(如寄存器、纹理)是“无限”的,简化编程模型,支持更宏大、更复杂的场景。
· 实现路径:
· 专利一中“无限资源模式”是关键词。第二代GPU硬件将强化资源描述符的动态管理和换入换出机制,使得单次渲染任务可调用的逻辑资源远超物理硬件的限制。
· 效果:直接助力于影视级质量的实时渲染、超大规模几何体处理、以及需要海量中间数据的AI训练与推理任务。
3. 统一、可扩展的着色器/计算核心架构
· 目标:打造一个既能高效处理图形流水线固定功能,又能灵活执行通用并行计算(GPGPU)的核心。
· 实现路径:
· 两项专利都强调了调度的统一性和数据供给的敏捷性。这表明其第二代GPU的执行核心(Execution Unit)很可能采用高度统一的设计,能够无缝切换处理顶点、像素、计算等任务。
· 效果:提升硬件在不同负载下的利用率,避免传统架构中因任务类型不同导致的“忙闲不均”。这对于图形与AI混合负载(如DLSS/FSR超分辨率、光线追踪去噪)尤为重要。
4. 对移动端与能效的深度优化
· 目标:在提升性能的同时,严格控制功耗和芯片面积。
· 实现路径:
· 专利一明确提到“降低硬件电路面积”。统一调度模块本身就是为了精简电路。专利二的预取机制可以减少高功耗的片上缓存和外部存储的频繁访问。
· 效果:这种设计哲学非常符合高性能移动GPU(手机、平板、车载)和嵌入式GPU的需求。第二代GPU可能会推出针对不同功耗墙的SKU,覆盖从旗舰移动到桌面级的全系列产品。
5. 强化面向未来的计算范式
· 目标:为光线追踪、AI增强图形、元宇宙等下一代应用提供底层硬件支持。
· 实现路径:
· “无序访问数据读/写”(专利一)是光线追踪中光线遍历和着色处理的典型需求。“常量数据的快速供给”(专利二)对复杂的BVH遍历和材质计算至关重要。
· 效果:架构原生地为可变速率着色(VRS)、硬件级光线追踪加速、以及AI张量核心的紧密集成铺平了道路。
总结:砺算科技第二代GPU的潜在画像
砺算科技的第二代GPU,预计不会单纯追求晶体管数量或峰值算力的简单堆砌,而是走一条 “以架构效率取胜”的差异化路线:
· 对外(开发者/用户):它将提供一个资源近乎无限、编程更友好的开发环境,并能在复杂图形和计算任务中提供更稳定、更低延迟的高性能输出。
· 对内(芯片设计):它追求在给定工艺节点下,实现更高的性能密度(每平方毫米性能)和能效比(每瓦性能)。
如果成功,这将是一款兼具高性能图形渲染、强大通用计算能力和优秀能效表现的GPU产品,其发力点可能会同时瞄准:
1. 国产高性能计算(HPC)与AI训练市场。
2. 高端游戏显卡市场,提供独特的效率优势。
3. 下一代移动设备和汽车智能座舱的图形与AI计算平台。
总之,砺算科技的第二代GPU研发方向,核心是“通过智能调度与高效数据供给,释放硬件潜力”,这是一条旨在挑战现有巨头、建立自身技术护城河的深思熟虑之路!显然竞争对手瞄准英伟达,这一次目标直接是5090级别以内的国产替代。
本文作者可以追加内容哦 !

