AI全球视野 英特尔首次推出GPU产品Gaudi 3
建信新兴市场基金(539002 )AI 全球重要新闻总结
1美东时间4月9日周二,谷歌在今年的年度云计算大会Cloud Next 2024上宣布推出一款基于Arm架构的数据中心芯片,名为Axion。谷歌计划通过谷歌云提供这款CPU,称它的性能超过x86架构的芯片,以及云上运行的通用Arm架构芯片。Axion芯片的性能比通用Arm芯片高30%,比英特尔 生产的当前一代 x86芯片高50%。Axion 用于多种谷歌服务,例如谷歌云中的YouTube 广告。谷歌该公司计划扩大此类用途,并在“今年晚些时候”向公众开放。Axion适用于一系列任务,包括支持谷歌的搜索引擎和工智能(AI)相关的工作。谷歌官员表示,该芯片可以通过帮助处理大量数据并为数十亿用户部署服务,在AI领域发挥重要的支持作用。谷歌之前将基于Arm服务器的电脑内部使用,运行YouTube广告BigTable 和 Spanner 数据库,以及 BigQuery 数据分析工具。谷歌的发言人称,当Axion可用时,公司将逐步将它们转移到基于云的Arm实例上。Datadog、Elastic、OpenX 和 Snap都计划采用 Axion。推出新的芯片意味着,谷歌正在追赶亚马逊和微软这些云领域竞争对手的步伐。亚马逊和微软2021年就已经推出Arm架构的CPU,作为提供差异化计算服务的一种方式。谷歌之前为YouTube、AI及其智能手机推出过定制芯片,但还没有打造过CPU。谷歌开发新芯片是在AI竞赛白热化之际减少对外部厂商的依赖。不过,谷歌的官员并没有将芯片新品视为一种竞争之举。谷歌负责自研芯片业务的副总Amin Vahdat说:“我觉得这是做大蛋糕的基础。”谷歌的张量处理单元(TPU)是少数英伟达先进AI芯片的替代品之一,而开发者只能通过谷歌的云平台使用,不能直接购买。博通是谷歌生产前几代TPU芯片的合作方。谷歌并未置评设计Axion是否有合作方,以及博通参与推出谷歌云第五代TPU TPU v5p的情况。数据显示,虽然广告依然是谷歌最大收入源,但云计算的增长更快,在谷歌的收入中占比不断提高,已接近占公司总收入的11%。盖特纳(Gartner)估算,2022 年,谷歌占云基础设施市场 7.5% 的份额,而亚马逊和微软合计控制着 62% 左右的份额。谷歌成为继微软和亚马逊之后第三家用Arm架构推出数据中心CPU的科技巨头。这显示了新的趋势,此前运营服务器大企业几乎都采购英特尔和AMD的CPU。# 固态电池概念火了,背后逻辑是什么?# $建信新兴市场混合(QDII)A(OTCFUND|539002)$$建信新兴市场混合(QDII)C(OTCFUND|018147)$$建信纳斯达克100指数(QDII)人民币C(OTCFUND|012752)$
2. 马斯克在X平台接受挪威国家投资管理公司首席执行官Nicolai Tangen采访时预见,未来五年内AI的智力将超越全人类。
马斯克长期以来一直对所谓的通用人工智能(AGI)持乐观态度,然而,他这次比以往任何时候都更激进。
去年马斯克曾预言,到2029年将实现完全AGI。谷歌DeepMind的联合创始人Demis Hass也在今年早些时候预测,AGI将可能在2030年实现。@天天基金网 @天天精华君 @天天话题君
但在过去18个月中,AI领域的几项重大突破——视频生成工具、更强大聊天机器人——已经将AI技术推进到了意料之外的高度,并让马斯克看到了AGI更早实现的希望。马斯克认为,过去AI行业面临的芯片供应短缺正在得到缓解,但新的挑战已经出现,AI模型对数据中心其他设备以及电网的需求仍在增加。
去年,AI行业的主要挑战是芯片短缺,人们难以获取足够的英伟达芯片;今年,问题逐渐转向电压变压器供应。预计一到两年内,AI行业发展的主要瓶颈将是电力供应。马斯克还表示,他名下的AI初创公司xAI正在训练名第二代Grok模型,“我们认为它可能会比GPT-4更为优秀,”预计在5月完成这一阶段的工作,并计划随后推出一款在多个维度更为强大的新模型。
3. 美国当地时间4月9日,英特尔举办了面向客户和合作伙伴的英特尔on产业创新大会。毫无预兆,这场大会上,英特尔首次介绍了他们的GPU产品Gaudi 3,向英伟达发起冲击。尽管英伟达不久前的GTC大会上已经发布了他们最强的 Blackwell GPU,不过英特尔Gaudi 3主要还是瞄准了英伟达的主力产品H100。 英特尔Gaudi 3将带来4倍的BF16 AI计算能力提升,以及1.5倍的内存带宽提升。英特尔副总裁Das Kamhout介绍,若应用在70亿、130亿参数Llama2模型,以及1750亿参数GPT-3模型上,采用英特尔Gaudi 3时的 模型训练时间,相比于英伟达H100将缩短50%,同时推理量提高50%。在GPU中,网络连接也是一项关键重点。在英特尔Gaudi 3中, 英特尔采用的是以太网网络,允许企业灵活地从单个节点扩展到拥有数千个节点的集群、超级集群和超大集群,支持大规模的推理、微调和训练。英特尔方面称,英特尔Gaudi 3将于2024年第二季度面向OEM厂商出货,名单包括戴尔、HPE、联想和Supermicro。不仅仅是 GPU产品的进展,英特尔此次还发布了另外一款宣布面向数据中心、云和边缘的英特尔至强6处理器,具体包括两款新产品。其中,配备能效核的英特尔至强6处理器(代号为Sierra Forest),与第二代英特尔至强处理器相比,每瓦性能提高2.4倍,机架密度提高2.7倍,将于2024年第二季度推出。配备性能核的英特尔至强6处理器(代号为Granite Rapids),与使用FP16的第四代英特尔至强处理器相比,可将token的延迟时间最多缩短6.5倍,能够运行700亿参数的Llama-2模型。根据cnvrg.io的调研结果,2023年只有10%的企业成功将其生成式AI项目产品化。为了改变现状,英特尔还在打造他们的 AI生态。此次发布会上,英特尔还宣布和多家企业合作, 为企业AI创建一个开放平台。在这一平台上,通过检索增强生成(RAG),让企业用户能够通过开放的 LLM功能,更容易部署生成式AI。
4. 在4月9日伦敦举行的一次活动中, Meta确认计划在下个月内首次发布LLaMA 3 。据称,该模型将有多个具有不同功能的版本。但Meta并没有披露LLaMA 3的参数规模。“随着时间的推移,我们的目标是让由LLaMA驱动的Meta AI成为世界上最有用的助手。”Meta人工智能研究副总裁Joelle Pineau说。“要达到这个目标,还有相当多的工作要做。”而据外媒报道,作为对标GPT-4的大模型, LLaMA 3的大规模版本参数量可能超过1400亿 ,而最大的LLaMA 2版本的参数量为700亿。 LLaMA 3将支持多模态处理 ,即同时理解和生成文本及图片。值得注意的是,LLaMA 3将延续Meta一直以来的开源路线。目前,开源模型界的竞争正在变得愈发激烈,开源大模型亦进化得越来越强大。截至目前,包括谷歌、马斯克旗下的xAI、Mistral AI、StabilityAI等在内的许多公司都发布了开源的大模型。
作为开源模型界的“扛把子”,Meta在AI基础设施上的投入亦不可小觑,目前只有微软拥有与之相当的计算能力储备。Meta发布的一篇技术博客称, 到2024年底,该公司将再购350000个英伟达H100 GPU,算上其他GPU,其算力相当于近600000个H100。值得注意的是,LLaMA 3将延续Meta一直以来的开源路线。与OpenAI坚持的闭源路线和大参数LLM不同,Meta从一开始就选择了开源策略和小型化LLM。2023年2月,Meta在其官网公开发布了LLaMA大模型,与 GPT系列模型类似,LLaMA也是一个建立在Transformer基础架构上的自回归语言模型。LLaMA包括70亿、130亿、330亿、650亿这四种参数规模,旨在推动LLM的小型化和平民化研究。相比之下,GPT-3最高则达到了1750亿的参数规模。Meta在当时的论文中总结称,尽管体积小了10倍以上,但LLaMA(130亿参数)的性能优于GPT-3。
一般来说, 较小的模型成本更低,运行更快,且更容易微调 。正如Meta首席执行官扎克伯格在此前的财报电话会议中称,开源模型通常更安全、更高效,而且运行起来更具成本效益,它们不断受到社区的审查和开发。谈及开源问题,扎克伯格在接受外媒The Verge采访时还曾表示:“我倾向于认为,最大的挑战之一是,如果你打造的东西真的很有价值,那么它最终会变得非常集中和狭隘。如果你让它更加开放,那么就能解决机会和价值不平等可能带来的大量问题。因此,这是整个开源愿景的重要组成部分。”除此之外, 小型模型还便于开发者在移动设备上开发AI软件 ,这也是LLaMA系列模型自开源来就获得开发者广泛关注的原因。当前,Github上许多模型都是基于LLaMA系列模型而开发。到去年7月,Meta又发布了LLaMA 2。当时,Meta也采用了先发小模型的策略。在发布700亿参数的LLaMA 2大规模版本之前,Meta先行推出了130亿和70亿参数的小型版本。不过,根据相关的测试,LLaMA 2拒绝回答一些争议性较小的问题,例如如何对朋友恶作剧或怎样“杀死”汽车发动机等。近几个月来,Meta一直在努力使LLaMA 3在回答有争议的问题上更开放,也更准确。尽管Meta没有透露LLaMA 3的参数规模,作为对标GPT-4的大模型, LLaMA 3的大规模版本参数量据悉可能超过1400亿,这与最大版本的LLaMA 2相比提升了一倍。在整个开源模型界,竞争正在变得愈发激烈,开源大模型亦进化得越来越强大。今年2月,谷歌罕见地改变了去年坚持的大模型闭源策略,推出了开源大模型Gemma;3月,马斯克也开源了旗下xAI公司的Grok-1模型。根据Gemma和Grok-1的性能测试文档,它们在数学、推理、代码等多项基准测试方面的性能均超过了同规模的LLaMA 2模型。截至目前,包括谷歌、xAI、Mistral AI、DataBricks和StabilityAI等在内的多家科技公司发布了开源的大模型。有业内人士此前在接受《每日经济新闻》记者采访时说道:“开源是大势所趋,我认为Meta正在引领这一趋势,其次是Mistral AI、HuggingFace等规模较小的公司。”
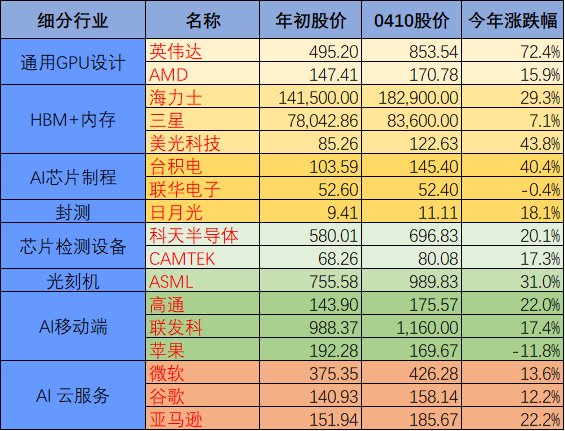
数据来源:Bloomberg,截至日期2024年4月10日
风险提示:部分个股讯息仅供参考,不作为任何投资建议或收益暗示。投资人应当认真阅读《基金合同》、《招募说明书》等基金法律文件,了解基金的风险收益特征,并根据自身的投资目的、投资期限、投资经验、资产状况等判断基金是否和投资人的风险承受能力相适应。基金的过往业绩并不预示其未来表现,基金管理人管理的其他基金的业绩并不构成基金业绩表现的保证。基金有风险,投资需谨慎。
本文作者可以追加内容哦 !

