AI全球视野 META准备开源更新的大语言模型
建信新兴市场基金(539002 )AI 全球重要新闻总结
1. # 据台湾经济日报,业界人士透露,亚马逊、戴尔、Google、Meta、微软等国际大厂都将导入英伟达Blackwell架构GPU打造AI服务器,量能超乎预期,为此,英伟达调高对台积电下单量约25%。分析认为,随着台积电传出开始生产Blackwell平台架构绘图处理器(GPU),意味英伟达搭载「地表最强AI芯片」的AI服务器问世倒数,开启AI业界新的一页,预料将成为台积电本周财报电话会议的焦点。分析师预估,以Blackwell架构打造的英伟达B100 GPU平均售价(ASP)为3万美元至3.5万美元,串联Grace CPU与B200 GPU的超级芯片GB200售价则介于6万美元至7万美元甚至更高,也就是说,英伟达相关芯片是台积电历来打造终端售价最贵的芯片。英伟达Blackwell架构GPU被誉为「地表最强AI芯片」,配备2,080亿个电晶体,采用台积电客制化4纳米制程制造,两倍光罩尺寸GPU裸晶通过每秒10TB的芯片到芯片互连连接成单个、统一GPU,且支援AI训练和即时大型语言模型推理,模型可扩展至10兆个参数。英伟达扩大Blackwell架构GPU投片量之际,就终端整机服务器机柜数量来看,包括GB200 NVL72及GB200 NVL36服务器机柜出货量同步大增,由原预期合并出货4万台,大增至6万台,增幅高达五成,当中以GB200 NVL36总量达5万台为数最多。业界估计,GB200 NVL36服务器机柜平均售价180万美元,GB200 NVL72服务器机柜售价更高达300万美元。GB200 NVL36有36个超级芯片GB200,18个Grace CPU、36个增强型B200 GPU;GB200 NVL72有72个超级芯片GB200,36个Grace CPU、72个B200 GPU。#6月社融同比少增,M1、M2增速回落# $建信新兴市场混合(QDII)A(OTCFUND|539002)$$建信新兴市场混合(QDII)C(OTCFUND|018147)$$建信纳斯达克100指数(QDII)人民币C(OTCFUND|012752)$
2. #谷歌母公司Alphabet正在计划以约230亿美元收购网络安全初创公司Wiz,这可能成为Alphabet历史上最大的一笔收购。两年前,Alphabet以54亿美元收购网络安全服务公司Mandiant,若此次收购Wiz成功,将意味着Alphabet将扩大在网络安全领域的布局,这也可能进一步引起监管注意,近年来,反垄断监管机构一直在打击科技巨头收购科技初创公司的行为。Alphabet 上一次大手笔的收购发生在十多年前,当时它以125亿美元收购了摩托罗拉。@天天基金网 @天天精华君 @天天话题君
这次要收购的Wiz,主要是为企业的云服务提供安全保护,客户包括Salesforce、玛氏和宝马等跨国集团。近些年来,随着企业越来越多地时候用云服务,Wiz的营收也随之激增,Wiz表示,它的年经常性营收已达到约3.5亿美元,这也是衡量软件初创企业发展潜力的常用指标。根据PitchBook的数据显示,Wiz自四年前成立以来,已融资约20亿美元。这家由前微软高管Assaf Rappaport创建的网络安全初创公司最近的估值约为120亿美元,背后的投资人包括红杉资本和Thrive。
3. #据媒体报道, OpenAI的内部团队正开发的“草莓”项目,目的是增强OpenAI的模型的推理能力,处理复杂科学和数学问题的能力,让大模型不仅能生成查询答案,还能提前规划,以便自主、可靠地浏览互联网,进行OpenAI 定义的“深度研究”。当被问及“草莓”的细节时,OpenAI的一位发言人只是绕了个弯表示:“我们希望AI大模型能像人类那样看待和理解这个世界。不断研究新的AI能力是业界的普遍做法,毕竟我们都相信AI的推理能力会随着时间的推移而不断提高。”但有媒体透露,“草莓”项目的前身是Q*算法模型,Q*能够解决棘手的科学和数学问题。而数学是生成式AI发展的基础,如果AI模型掌握了数学能力,将拥有更强的推理能力,甚至与人类智能相媲美。而这一点也是目前的大语言模型还无法做到的。去年底Q*在OpenAI的内部信中首次曝光,而CEO奥特曼当时被开除也是因为这个Q*项目。一些OpenAI内部人士指出,Q*可能是 OpenAI 在追寻通用人工智能(AGI)路上的一项突破,其发展速度之快让人感到震惊,并担心AI过快发展可能会威胁到人类安全。在这种担忧蔓延之际,奥特曼在没有告知董事会的情况下,选择加速推进GPT系列模型的开发及商业化,这激发了OpenAI董事会的不满并选择把他踢出局。
OpenAI的野心:利用“草莓”提高大模型的推理能力.虽然无法获取“草莓”的详细情况,但从OpenAI近期的种种蛛丝马迹中可以发现,增强生成式AI大模型的推理能力,是它接下来的发展重心。OpenAI的CEO奥特曼曾强调,今后AI发展的关键将围绕推理能力展开。在本周二的一次内部全员会议上,OpenAI展示了一个研究项目的演示,称该项目拥有类似人类的推理能力。OpenAI发言人向媒体证实了这次内部会议,但拒绝透露会议细节,因此无法确定演示的项目是否为“草莓”。但据知情人士透露,“草莓”项目包括一种专门的“后训练”方法,即生成式AI模型已经过大量数据集上进行预训练后,进一步调整模型以提高其在特定任务上的表现。这类似于斯坦福大学在2022年开发的“自学推理者”(Self-Taught Reasoner,简称STaR)方法。STaR的创造者之一、斯坦福大学教授Noah Goodman曾表示,STaR可以让AI模型通过反复创建自己的训练数据,“引导 ”自己进入更高的智能水平,理论上可以用来让语言模型实现超越人类的智能。
4. #,Meta计划7月23日发布旗下第三代大语言模型(LLM)Llama 3的最大版本。这一最新版模型将拥有4050亿参数,也将是多模态模型,这意味着它将能够理解和生成图像和文本。该媒体未透露这一最强版本是否开源。去年7月Meta发布的Llama 2有三个版本,最大版本70B的参数规模为700亿。今年4月,Meta发布Llama 3Meta,称它为“迄今为止能力最强的开源LLM”。当时推出的Llama 3有8B和70B两个版本。Meta CEO扎克伯格当时称,大版本的Llama 3将有超过4000亿参数。Meta并未透露会不会将4000亿参数规模的Llama 3开源,当时它还在接受训练。对比前代,Llama 3有了质的飞跃。Llama 2使用2万亿个 token进行训练,而训练Llama 3大版本的token超过15 万亿。Meta称,由于预训练和训练后的改进,其预训练和指令调优的模型是目前8B和70B两个参数规模的最佳模型。在训练后程序得到改进后,模型的错误拒绝率(FRR)大幅下降,一致性提高,模型响应的多样性增加。在推理、代码生成和指令跟踪等功能方面,Llama 3相比Llama 2有极大改进,使Llama 3更易于操控。4月Meta展示,8B和70B版本的Llama 3指令调优模型在大规模多任务语言理解数据集(MMLU)、研究生水平专家推理(GPQA)、数学评测集(GSM8K)、编程多语言测试(HumanEval)等方面的测评得分都高于Mistral、谷歌的Gemma和Gemini和Anthropic的Claude 3。8B和70B版本的预训练Llama 3多种性能测评优于Mistral、Gemma、Gemini和Mixtral。
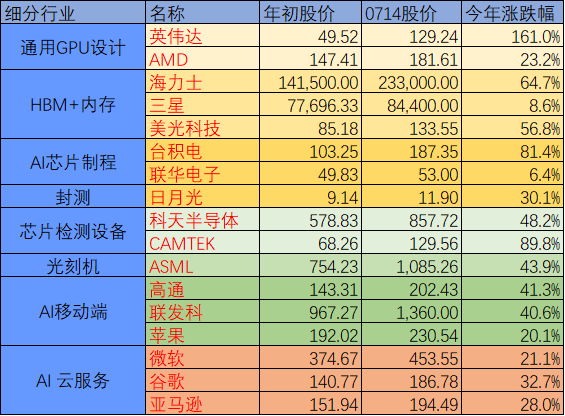
数据来源:万得,截至日期2024年7月15日
风险提示:部分个股讯息仅供参考,不作为任何投资建议或收益暗示。投资人应当认真阅读《基金合同》、《招募说明书》等基金法律文件,了解基金的风险收益特征,并根据自身的投资目的、投资期限、投资经验、资产状况等判断基金是否和投资人的风险承受能力相适应。基金的过往业绩并不预示其未来表现,基金管理人管理的其他基金的业绩并不构成基金业绩表现的保证。基金有风险,投资需谨慎。
本文作者可以追加内容哦 !

