当前,生成式人工智能已引爆新一轮智能革命的发展浪潮,大算力支撑下的人工智能技术极大改变着人类的生产生活方式。可随之而来的海量参数令算力需求持续攀升,如何解决庞大的算力缺口,实现能效比的大幅提升,正在变得日益迫切。高算力、高能效芯片作为算力的具体载体,已成为驱动本轮智能革命发展的核心底座,更是推动人类社会不断发展的动力源泉。
面向传统存算分离架构制约算力提升的重大挑战,集成电路学院吴华强教授、高滨副教授聚焦忆阻器存算一体技术研究,探索实现计算机系统新范式。忆阻器存算一体技术从底层器件、电路架构和计算理论全面颠覆了传统冯·诺依曼传统计算架构,可实现算力和能效的跨越式提升,同时,该技术还可利用底层器件的学习特性,支持实时片上学习,赋能基于本地学习的边缘训练新场景。
当前国际上的相关研究主要集中在忆阻器阵列层面的学习功能演示,然而实现全系统集成的、支持高效片上学习的忆阻器芯片仍面临较大挑战,至今还未实现,主要在于传统的反向传播训练算法所要求的高精度权重更新方式与忆阻器实际特性的适配性较差。具体而言,一是由于忆阻器固有的非理想特性,要精确更新权重则需要对忆阻器反复校验编程,产生了大量的功耗和延迟;二是在权重更新过程中,需要对不同忆阻器施加不同的操作条件,难以实现高效并行的电导调制策略;三是高精度的权重更新量计算导致了过高的开销。
为解决上述难题,课题组基于存算一体计算范式,创造性提出适配忆阻器存算一体实现高效片上学习的新型通用算法和架构(STELLAR),有效实现大规模模拟型忆阻器阵列与CMOS的单片三维集成,通过算法、架构、集成方式的全流程协同创新,研制出全球首颗全系统集成的、支持高效片上学习的忆阻器存算一体芯片。该芯片包含支持完整片上学习所必需的全部电路模块,成功完成多种片上增量学习功能验证,展示出高适应性、高能效、高通用性、高准确率等特点,有效强化了智能设备在实际应用场景下的学习适应能力,为突破冯·诺依曼传统计算架构下的能效瓶颈提供了一种创新发展路径。

忆阻器存算一体芯片及测试系统
课题组首先提出一种基于忆阻器存算一体实现高效片上学习的通用算法和架构。这些方法充分考虑忆阻器存算一体计算范式的特点,即只考虑权重更新的方向;根据符号计算权重更新方向,并按照一定的阈值对误差取符号;采用一种并行交替的电导调制策略进行权重更新,有效克服忆阻器的非理想特性,大幅降低电路、系统的设计复杂度和运行开销。
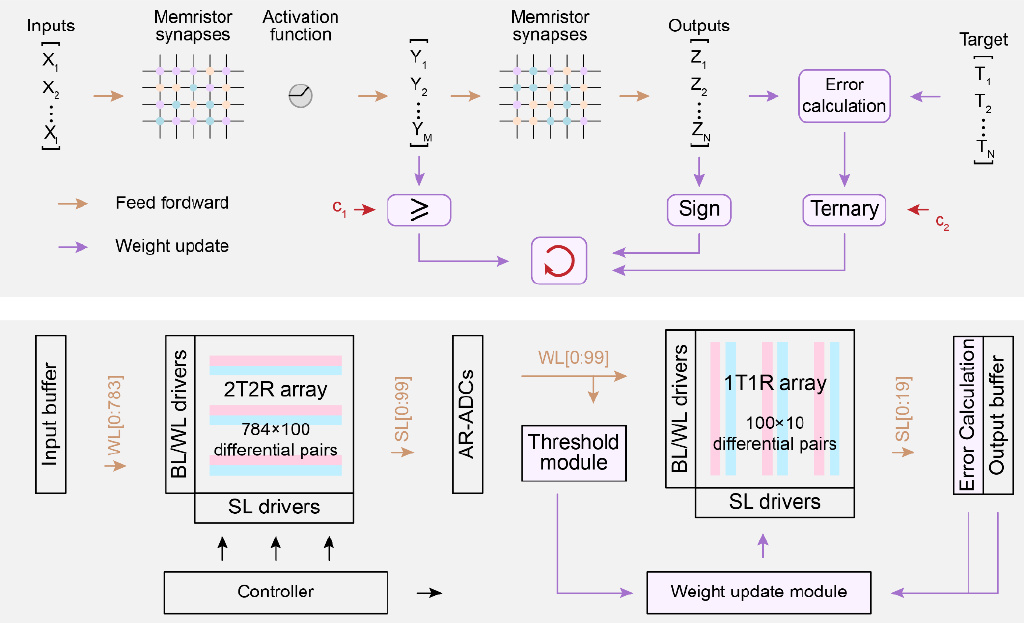
基于忆阻器存算一体实现高效片上学习的通用算法和架构
在此基础上,课题组设计并研制了全系统集成的忆阻器存算一体芯片,所有与学习相关的计算均在该芯片上完成。硬件实测结果显示,相同任务下,该芯片实现片上学习的能耗仅为先进工艺下专用集成电路(ASIC)系统的3%,展现出卓越的能效优势,极具满足人工智能时代高算力需求的应用潜力。
课题组基于该忆阻器芯片完成了多个片上增量学习演示任务,涉及图像分类、语音识别、控制任务的样本增量学习和类别增量学习。增量学习是指神经网络模型在已有知识的基础上,通过少量新类别或新样本数据快速地学会新知识,且不会遗忘已有知识。装载该忆阻器芯片的小车在只适应暗场环境时,通过少量数据增量学习便同时具备了亮场环境下的适应能力。
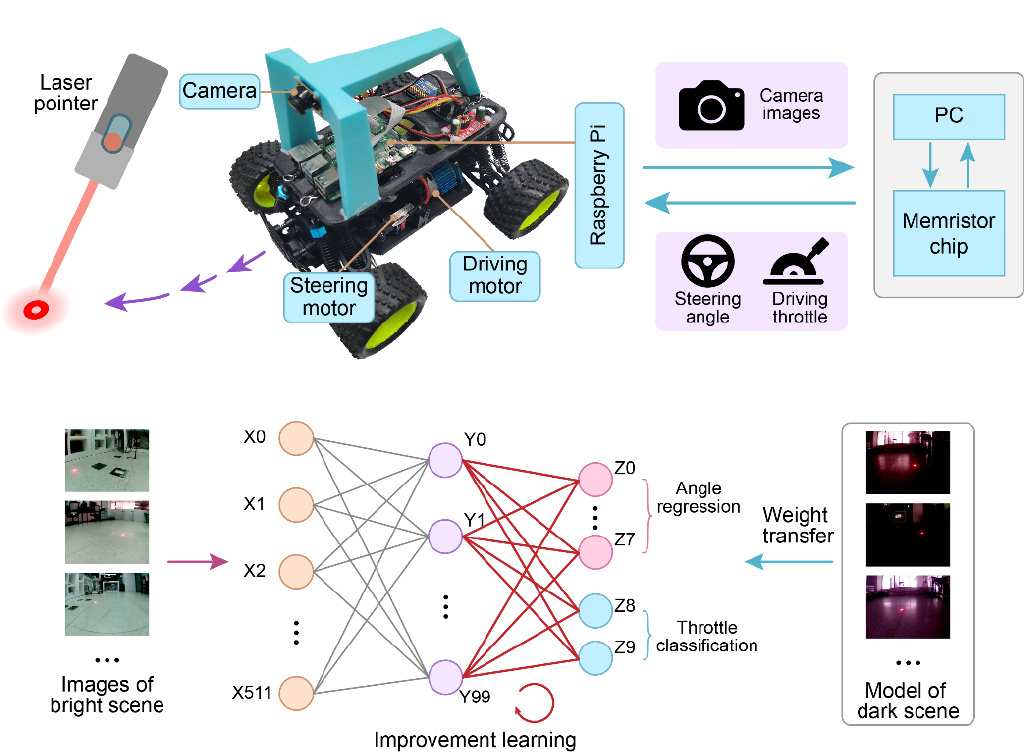
控制任务样本增量学习演示
该研究成果今天以“面向边缘学习的全集成类脑忆阻器芯片”(Edge Learning Using a Fully Integrated Neuro-Inspired Memristor Chip)为题在线发表在Science上。
论文通讯作者为清华大学集成电路学院高滨副教授和吴华强教授,清华大学集成电路学院博士生张文彬、博士后姚鹏为论文的共同第一作者,其他参加研究的作者包括清华大学集成电路学院钱鹤教授、唐建石副教授、伍冬副研究员、张清天助理研究员,清华大学电子系汪玉教授等。
该研究得到科技部科技创新2030“脑科学与类脑研究”重大项目、国家自然科学基金委后摩尔重大研究计划、北京集成电路高精尖中心等支持。
清华大学集成电路学院钱鹤、吴华强教授团队长期致力于基于忆阻器的存算一体技术研究,从器件制备、工艺集成、电路设计及架构与算法优化等多层次实现创新突破,先后在《自然》(Nature)、《科学》(Science)、《自然·纳米技术》(Nature Nanotechnology)、《自然·电子》(Nature Electronics)、《自然·机器智能》(Nature Machine Intelligence)等顶级期刊以及国际电子器件会议(IEDM)、国际固态半导体电路大会(ISSCC)等领域内顶级国际学术会议上发表多篇论文。高滨课题组作为团队重要研究力量,长期从事忆阻器性能优化和存算一体芯片设计方法的相关研究,成功开发了从器件到系统的联合仿真工具和协同优化方法,设计出计算精度大于95%、能效大于78TOPs/W的高性能忆阻器存算一体芯片。
本文作者可以追加内容哦 !

