具身智能狂潮降临的一年多里,物理世界与信息的生产与交互方式发生着革命性变化。
与此同时,一场新的争夺战正悄然打响:各大厂商绞尽脑汁,以夺取最有价值的 AI “燃料”—— 数据。当前,数据匮乏仍是通用具身智能面前的高墙。纵观过去三年,在谷歌、英伟达、OpenAI 等知名企业对具身智能的研究中,暂未窥见Scaling Law的出现,这与缺少各类数据有关。
如何解决这一根本性痛点?从技术的角度,Sim2Real AI 是一个长期存在的路径。但由于对消弭 Sim2Real gap 存在 “理念型偏差”,学术界和产业界更多地将其视为一个辅助的数据补充手段。
但是否真的如此?
香港中文大学(深圳)终身教授、跨维智能创始人贾奎通过从学术界到产业界的长期践行,给出答案:“Sim2Real AI 正是通往具身智能的最高效路径。”
从二维视觉到三维视觉、从空间智能到具身智能、从科研到产品再到商业落地,贾奎在这一领域已探索了二十余年。近期,在 WAIC 上,进行了一场关于具身智能如何突破数据困局的对谈。
如果用 AI 来试图理解这次对谈,它也许会帮助你概括出这些要点:
当下最火热的空间智能和具身智能的本质是什么?
以 Scaling Law 范式实现空间与具身智能的具体涵义是什么?
哪条路是实现通用具身智能的最高效路径?
具身智能如何从技术到产品再到商业落地?
未来,有哪些能够突破行业生产范式的想象成真?
当然还有 AI 暂时理解不了的部分 —— 这位科研工作者、创业者,展现出了其坚定信心及历史使命。
以下为访谈实录:
建立 “世界模型” 触发机器人 “灵性”
问:被誉为 “AI 教母” 的李飞飞教授首次创业即选择了 “空间智能” 方向,引发了对这一领域的广泛关注。可以谈谈您对空间智能和具身智能的理解吗?
贾奎:空间智能和具身智能是近年来进入到社会层面备受关注的话题,但其背后的学术研究已经持续了很久。空间智能(Spatial Intelligence)是一个多维度的概念,通常指个体在三维物理空间及四维时空中的认知和推理能力,包括感知、推理、决策等方面。具身智能(Embodied Intelligence)则是指智能系统具备物理形态,并通过这个形态与环境进行交互的智能。具身智能不仅仅关注感知,还包括智能体对环境的行动和反应。就像人类使用双眼感知世界一样,具身智能要求机器人能够通过多模态传感器进行感知、交互和决策,形成综合的空间认知和操作能力。
问:空间智能与具身智能的异同点是什么?
贾奎:就像前面提到的,空间智能赋予 AI 感知并理解现实世界的能力,而具身智能则不仅需要空间智能涉及到的对物体、环境及其他智能体的感知和认知推理,还进一步涵盖了机器人操作所需的高级运动规划和低级运动控制,以及由机器人本体与操作对象交互所定义出的类似人类操作能力的各类机器人 “技能”。每一种技能的掌握,意味着机器人可以处理与该技能相关的各种物体对象,而不仅仅是一个特定的、具体的对象。
这些技能包括 “子技能” 和 “原子技能” 的集合,形成了一个机器人技能库,或称为 “技能空间”。具身智能的本质是学习并泛化这个技能空间,从而实现像人类一样具备具身属性的通用人工智能(AGI)。
在具体应用中,空间智能范围更广,可以是附着在机器人身上,也可以脱离机器人,本质上是一个对空间的理解的问题,例如它的重要应用 AR/VR。而具身智能则主要体现在机器人身上,特别是通用(人形)机器人。
总的来说,空间智能更多地关注四维时空中的认知和推理能力,而具身智能则进一步包括了通过物理形态与环境进行直接互动的能力。
问:您为什么会选择空间与具身智能方向创业?
贾奎:可以说我们对这一领域关注得很早,有深厚的历史沉淀和技术积累。团队在早期就成立了 “几何感知与智能实验室”,当时这一领域尚未被大家所熟知的 “大厂” 涉足。我们是中国最早将人工智能技术应用于三维等非欧数据的学者和团队之一。
我们团队在几何深度学习、三维建模、空间感知、机器人应用等方向进行了大量交叉创新研究,取得了一系列代表性成果,包括 Grasp Proposal Networks (NeurIPS 2020), Analytic Marching (ICML 2020/TPAMI 2021), Sparse Steerable Convolution (NeurIPS 2021), 3D AffordanceNet (CVPR 2021), Fantasia3D (ICCV 2023), SAM-6D (CVPR 2024) 等等。

DexVerse™ 2.0 引入了全新的 4D Mesh 技术,专为动态物理仿真和数据渲染生成而设计,可统一处理刚体、软体、流体等多种对象。作为引擎的核心表达形式,4D Mesh 将贯穿物理仿真、数据标注生成到大模型训练的整个流程。
问:您理解的空间与具身智能的核心理念是什么?在这条火热的赛道上,跨维的优势在哪?
贾奎:我们认为,空间和具身智能的核心在于建立 “世界模型”,让机器人具备类似人类感知的 “灵性”。具体来说,需要建立能够对空间几何与物理过程进行精准建模、理解与推理的 “世界模型”,使包括视觉、力觉、触觉等在内的各类机器人传感器具备人类感知的能力。
在当前的 AI 架构和模型范式下,我们团队希望通过生成式物理仿真,捕捉人类生存世界的时空四维镜像,从而获取无穷无尽的物理属性数据 —— 这是实现空间与具身智能的关键。
因此,跨维自成立之初就打造了底层自研的 DexVerse™ 空间与具身智能引擎,能够针对具体的商业场景,实现 “物理仿真 - 数据合成 - 模型训练” 的全链条自动化,并基于此形成空间与具身智能大模型套件及纯视觉智能传感器,赋予通用机器人提供智慧的大脑和双眼。
目前,跨维已经在多个商业场景中,实现以 100% 的合成数据,在毫米 / 亚毫米的操作精度要求下,达到 99.9% 以上的任务成功率。
通用空间与具身智能 离终局还有多远?
问:您刚刚谈及以 Scaling Law 范式实现空间与具身智能,可以再详细说说它的具体含义吗?实现通用空间与具身智能会比实现大语言模型的通用性更难吗,难在哪里?
贾奎:实现通用空间与具身智能确实比实现大语言模型的通用性更难。以 OpenAI 的 GPT 系列为代表的大语言模型,通过利用海量自然语言文本,并结合 “自监督预训练 + 监督学习 + 强化学习意图对齐” 的方式,实现了自然语言理解任务的零样本(zero-shot),即通用能力,展示了所谓的 AGI 的曙光。
人类自然语言可以看作是对所生活的宇宙和自然环境经过高度抽象后,提炼出的语义编码。因此大语言模型直接在抽象层面进行学习和泛化,相对容易一些。
比较而言,空间智能需要从传感器获取的原始信号中学习,这意味着要跨越从原始数字信号到人类语义符号之间的 “语义鸿沟”。要通过类似 GPT 的 Scaling Law 范式来学习通用智能,需要大量训练数据;而空间智能的训练数据不仅需要大量,还要对传感器获取的原始信号进行精确标定,以确保其具备绝对物理尺度上的度量,这比从互联网获取海量图像文本数据困难得多。
具身智能更进一步,除了需要从视觉、力觉、触觉等高维感知信号中学习通用智能,其更本质的目标是学习由机器人本体和操作对象共同定义出的机器人 “技能空间”。具身智能的通用性体现在技能空间中的泛化,这增加了对不同范式的学习难度。
问:可以谈谈空间智能与具身智能具体需要哪些多模态大模型能力吗?
贾奎:空间智能涉及在三维物理世界的感知、交互、推理、决策等任务,具身智能进一步要求基于对视觉、力觉、触觉等空间感知信号的智能分析,形成机器人的自主操作技能库。
因此,需要包括自然语言、力触视、机器人本体状态等模态在内的多模态大模型能力。这些多模态能够在共通的语义、时空及技能空间中 “融会贯通”,从而实现像人一样的空间及具身智能。
问:在您看来,通用空间与具身智能离终局还有多远?
贾奎:目前,以海量数据、大模型和巨大算力为特点的 Scaling Law AI 范式,在通用机器人硬件成熟的前提下,即人形机器人、灵巧手、类人传感器等核心部件能够以高性价比方式稳定量产,至少能够支持空间与具身智能在多个有边界和 ROI 合理的商业场景闭环中,形成独立的商业价值。
具体来说,在工业、物流、商业、家庭等多个场景中,机器人能够以可泛化的方式完成多种任务。当然,这需要获取海量具备物理属性的多模态数据,以及支持监督训练、模仿学习、强化学习等多种学习策略的丰富标注的自动计算。
实现通用具身智能的最高效路径
问:之前关注到您在 WAIC 演讲中提到 “Sim2Real AI 是最高效的具身智能实现路径”,可以展开说说吗?
贾奎:要实现具身智能,必须考虑数据的性质和目标。具身智能的目标是让机器人基于视觉、力觉、触觉等传感器信号,在变化多端的物理世界中实现通用操作能力,就像我们人类每天在日常生活中所做的那样。
在 Scaling Law AI 范式下,即机器学习模型并无真正的通用智能或者说泛化性,而是仅仅在学习统计分布及其统计分布中 “插值” 能力,训练具身智能机器人需要获取大量数据。
这些数据要涵盖每个机器人技能在所涉及的各种操作情况上,比如从早到晚、春夏秋冬、室内到室外的所有操作情况。如果依赖于机器人数据采集系统或可穿戴设备,例如大家耳熟能详的 “遥操作”,那么要采集足够的数据,首先需要建立一个商业模式,让用户在享受服务、享受商业价值的同时,顺便帮忙采集数据,但目前并没有这样的方式。
相较而言,Sim2Real AI 通过物理仿真和合成数据,可以更高效地覆盖上述所有变化。这种方法允许在虚拟环境中模拟各种操作对象、环境变化、机器人构型和传感器变化,并能针对不同商业场景共享底层的物理仿真和数据生成能力。包括刚体、铰链、软体、流体等在内的任何操作对象,都可以通过精准的物理仿真支持数据生成。
因此,总的来说,虽然利用机器人数据采集系统或可穿戴设备 “遥操作”,可以快速展示一些类人操作动作,但与实现通用机器人所需的具身智能能力相比,这种方法显得 “南辕北辙”,Sim2Real AI 才是实现目标的最高效路径。
问:那在这种技术路径下,如何消弭合成数据与真实数据之间的 GAP?
贾奎:从学术界的角度,Sim2Real AI 是一个长期存在的技术路径,是实现空间与具身智能的主流路径之一。我们团队也是从学术界起步,在产品和业务落地的过程中,成功地趟出一条独特道路:能够在多个场景中以 100% 的合成数据,在毫米 / 亚毫米的精度要求下,实现 99.9% 以上的任务成功率,这在全球范围内可能都是绝无仅有的。
任何成功都不是偶然的,而是基于对问题的深入理解和系统化解决。从第一性原理出发,思考事物的内蕴,跨维团队通过简化复杂问题,层层拆解,找到了有效的解决方案。
简单的说,以 Sim2Real AI 的方式走通具身智能,需要对包括:
1)机器人本体仿真、多模态传感器仿真、不同形态的操作对象仿真以及动态过程仿真;
2)仿真对应的数据和标注渲染生成;
3)具身智能大模型设计和训练等在内的环节建立可 Sim2Real 迁移的自动化链条,并且至少需要克服以下核心技术门槛:
底层可控的具身性物理仿真
高效多模态大模型训练与持续学习
有效应对合成与真实数据域差别
低成本海量数字资产获取
问:那基于您刚刚提及的 Sim2Real AI 技术路径,跨维有哪些实践结果?
贾奎:跨维从底层构建了一个包括物理仿真、数据渲染生成、自动标注计算、模型设计与训练等模块在内的具身智能引擎 DexVerse™。这个引擎无需研发人员的参与,能够全链条自动化地产生针对具身智能任务的 AI 模型 SDK,数据生成速度与 AI 模型的训练迭代速度同频,从而完全不需要存贮数据,积攒多少条训练数据也将不再是具身智能落地的一个量化标准。目前,跨维在多个场景中的软硬件产品落地都由 DexVerse™ 支撑。
DexVerse™ 2.0 更进一步:
首先,给定一个边界清晰的商业场景和机器人硬件构型,DexVerse™ 2.0 能够利用大语言模型自动拆解所涉及到的机器人技能及子技能。
其次,针对任意一个技能或子技能,DexVerse™ 2.0 能够自动化地生成仿真所需对象、场景等数字资产,并基于这些资产仿真渲染生成虚拟空间中的机器人操作过程数据条。
紧接着,通过虚拟空间中的数据生成,训练具身智能 3D VLA(Vision Language Action)模型。
最后,训练好的模型可以在选定的商业场景内驱动机器人本体,以通用的方式完成各种机器人技能操作。

通过 DexVerse™ 具身智能引擎 2.0 全链条自动化地进行任务拆解、场景生成、训练配置生成、模型训练,并将训练好的模型导入真机引导机器人完成小鹿积木拼装的操作。
通过这个全自动化引擎,通用机器人修炼具身智能技能 / 子技能的飞轮将最高效地转动起来,推动通用机器人在更多场景实现落地。跨维将与更多产业方合作,开放生态,合作共赢,共同推进中国具身智能与通用机器人产业高速发展。
问:跨维为什么选择自研引擎?跨维 DexVerse™引擎与英伟达的 Omniverse™有什么差异?
贾奎:跨维做具身智能引擎与英伟达的 Omniverse™等引擎的理念是完全不同的。
如果说 Omniverse™是横向拓展,覆盖机器人、科学计算、AI for Science 等不同板块,同时为英伟达的 AI 算力产品服务,那么跨维的 DexVerse™则是端到端垂直打穿,引擎的迭代演进是为实现垂直场景中的具身智能技能任务服务的。
在当前 Sim2Real AI 仍处于创新驱动产品业务落地的阶段,只有依托自研引擎,才能支撑研发过程中从物理仿真、数据渲染生成、自动标注计算、具身智能模型设计和训练的各个环节,逐点攻关,掌握 know-how, 才能实现产品在业务场景中的真正落地。
具身智能商业落地的 L1-L5 之路
问:您认为具身智能从技术到产品再到商业落地,需要怎样的实现路径?
贾奎:具身智能的本质,是通过学习包含各种可泛化技能的机器人技能库,赋予各类机器人在不同应用场景中的通用操作能力;因而其商业化落地,必须以工业、农业、商业、个人 / 家庭等一个个有边界的商业场景为目标,“以终为始”,通过建立独立商业场景中的机器人通用技能,形成产品价值和商业落地。
技术上,具身智能必须以 Sim2Real AI 的方式,打通任务理解、数字资产生成、数据仿真生成、AI 模型训练的自动化链条,以最高效的方式实现通用机器人任务学习,并在这个过程中形成适用不同商业场景的软硬件产品,包括具身智能 SoCs、智能传感器、通用机器人控制器等。
路径上,具身智能需要首先赋能机械臂、复合机器人等等相对成熟的硬件本体,并随着灵巧手、人形机器人等通用本体的成熟量产,进一步提升整体能力,产生更大的商业价值。
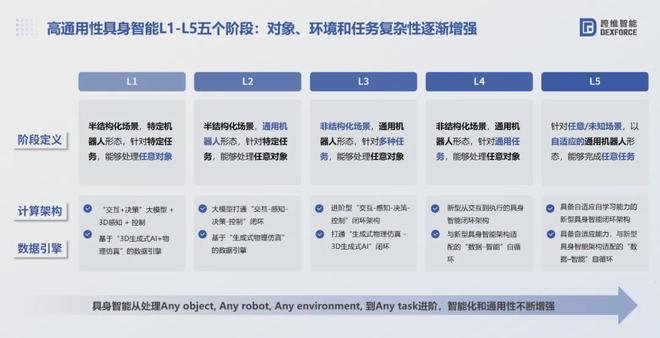
问:基于您提出的高通用性具身智能 L1-L5 五个阶段,跨维当前到哪个阶段了?
贾奎:跨维基于自研的 DexVerse™具身智能引擎,已经建立了服务智能制造、智慧农业等应用场景的场景任务理解、数字资产生成、数据仿真生成、AI 模型训练等全链条能力,并形成了包括智能视觉传感器、PickWiz 软件、复合机器人等具身智能产品。
目前,跨维已经跑通了 “Simulation to Reality” 的商业模式,在汽车零部件、3C 制造、新能源、家电、化工、物流等 30 余个行业中落地,合作了包括广汽、美的、海尔、松下、蓝思科技等在内的众多行业头部客户。
参照上图 L1-L5,跨维已完成具身智能 L1 阶段的发展,正在稳健地迈向 L2 级,这在全球范围内,都是屈指可数的。
问:您认为具身智能、人形机器人的终局生态链是怎样的?跨维会做(人形)机器人硬件整机么?
贾奎:通用机器人终局生态链由人形本体厂商、零部件厂商、视触力等传感器厂商、具身智能芯片与方案供应商等组成。跨维 DexVerse™具身智能引擎在产业链去往终态的过程中,在技术路径、产品形态、场景业务落地等方面将发挥决定性作用,通过 DexVerse™的 Sim2Real AI 全链条能力,以终为始,从商业闭环的方式推动具身智能机器人在硬件构型、传感器选型、数据模态范式及多模态大模型等方面统一标准。
跨维已形成复合机器人、智能视觉传感器、PickWiz 软件等具身智能产品,在落地更多商业场景的过程中,跨维将首先赋能相对成熟的移动 / 轮足底盘 + 双机械臂的具身智能本体,并最终与人形机器人本体厂商形成合力,实现通用具身智能的广泛落地。
本文是访谈记录,过程中不便直接引用相关学术文献,特此在本留言列明在DexVerse™ 2.0实践中所参考的学术文献。
[1] Wang Y, Xian Z, Chen F, et al. Robogen: Towards unleashing infinite data for automated robot learning via generative simulation[J]. arXiv preprint arXiv:2311.01455, 2023.
[2] Nasiriany S, Maddukuri A, Zhang L, et al. RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots[J]. arXiv preprint arXiv:2406.02523, 2024.
[3] Xi Z, Ding Y, Chen W, et al. AgentGym: Evolving Large Language Model-based Agents across Diverse Environments[J]. arXiv preprint arXiv:2406.04151, 2024.
[4] Zhang S, Wicke P, enel L K, et al. LoHoRavens: A Long-Horizon Language-Conditioned Benchmark for Robotic Tabletop Manipulation[J]. arXiv preprint arXiv:2310.12020, 2023.
[5] Mandlekar A, Nasiriany S, Wen B, et al. Mimicgen: A data generation system for scalable robot learning using human demonstrations[J]. arXiv preprint arXiv:2310.17596, 2023.
[6] Wu C, Chen J, Cao Q, et al. Grasp proposal networks: An end-to-end solution for visual learning of robotic grasps[J]. Advances in Neural Information Processing Systems, 2020, 33: 13174-13184.
[7] Lei J, Jia K. Analytic marching: An analytic meshing solution from deep implicit surface networks[C]//International Conference on Machine Learning. PMLR, 2020: 5789-5798.
[8] Lin J, Li H, Chen K, et al. Sparse steerable convolutions: An efficient learning of se (3)-equivariant features for estimation and tracking of object poses in 3d space[J]. Advances in Neural Information Processing Systems, 2021, 34: 16779-16790.
[9] Deng S, Xu X, Wu C, et al. 3d affordancenet: A benchmark for visual object affordance understanding[C]//proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2021: 1778-1787.
[10] Chen R, Chen Y, Jiao N, et al. Fantasia3d: Disentangling geometry and appearance for high-quality text-to-3d content creation[C]//Proceedings of the IEEE/CVF international conference on computer vision. 2023: 22246-22256.
[11] Lin J, Liu L, Lu D, et al. Sam-6d: Segment anything model meets zero-shot 6d object pose estimation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024: 27906-27916.
更多细节详情及参考文献,我们将在后续的Arxiv稿件中详细阐述。
本文作者可以追加内容哦 !

