7月23日,据国外媒体报道,马斯克在其社交媒体上宣布,旗下AI初创公司xAI已开始在位于田纳西州的所谓孟菲斯超级集群(training cluster)上进行训练,号称这是“全球最强大的AI训练集群”。
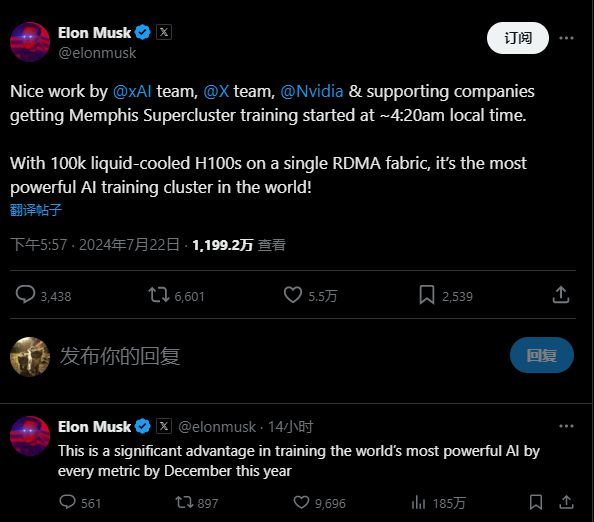
据马斯克介绍,这个集群由100,000个液冷H100 GPU组成,这些芯片是英伟达去年开始提供的。
马斯克还表示,该集群在单个RDMA结构(即远程直接数据存取结构)上运行。据思科介绍,这种结构可以在计算节点之间提供更高效、更低延迟的数据传输,而不会给中央处理器(CPU)带来负担。
马斯克今年5月曾透露这一计划 ,将英伟达H100串联到一台巨型的超级计算机中,并称其为“算力超级工厂”。
当时,马斯克匆匆忙忙地开始了Supercluster的工作,需要购买英伟达“Hopper”H100 GPU。这似乎表明,当时这位科技大亨没有耐心等待 H200 芯片推出,更不用说即将推出的基于 Blackwell 的 B100 和 B200 GPU。尽管预计较新的 Nvidia Blackwell 数据中心 GPU 将在 2024 年底之前发货。
xAI的目标是到2024年12月训练出“按每项指标衡量都是全球最强大的AI”。马斯克表示,孟菲斯超级集群将为实现这一目标提供“显著优势”。
马斯克周一还表示,特斯拉将在明年小规模生产用于内部使用的Optimus机器人,并希望到2026年能大规模生产供其他公司使用。这比他之前承诺的时间表晚了。之前马斯克宣称到2024年底将在特斯拉工厂使用Optimus机器人,并在2025年交付给其他公司。
另外,Microsoft正在与OpenAI首席执行官Sam Altman(阿尔特曼)合作开发一个价值1000亿美元的AI训练超级计算机,代号为Stargate。如果这一项目取得成功,xAI的孟菲斯超级集群可能不会长期保持全球最强大的AI训练集群地位。
AI既是“暴力美学”,也是工程比拼,需要算力、算法、数据的深度融合与经验积累。
一方面,随着计算量不断攀升,单卡算力角色弱化,大模型训练亟需一个超级工厂,即“大且通用”的加速计算平台,以缩短训练时间,实现模型能力的快速迭代。随着大模型参数量从千亿迈向万亿,模型能力更加泛化,大模型对底层算力的诉求进一步升级,万卡甚至超万卡集群已成为竞赛入场券。
另一方面,建设万卡或超万卡集群并非一万张GPU卡的简单堆叠,而是一项高度复杂的系统工程。算力集群不是一个计算GPU,怎么把它组织成算力网络,相互之间通讯效率怎么提高,怎么实现MFU(算力利用率)达到60%的最优目标,这些都要靠网络通讯、计算、存储一起来解决。只有软硬件结合,把整个集群算力发挥到最高,才能实现1+1>2的效果。
值得注意的是,在比拼算力和算法之外,如何将人工智能基础设施化,赋能全行业,中国正在做人工智能赋能实体经济的道路探索。
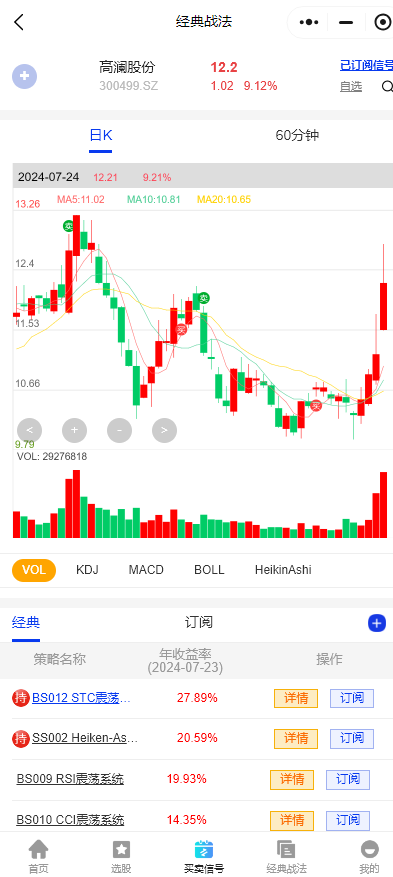
$高澜股份(SZ300499)$:公司控股子公司高澜创新科技负责数据中心液冷产品的研发、生产及制造,现有三种解决方案:冷板式液冷、浸没式液冷和集装箱式液冷。战法一半在参与,低位参与的继续看。
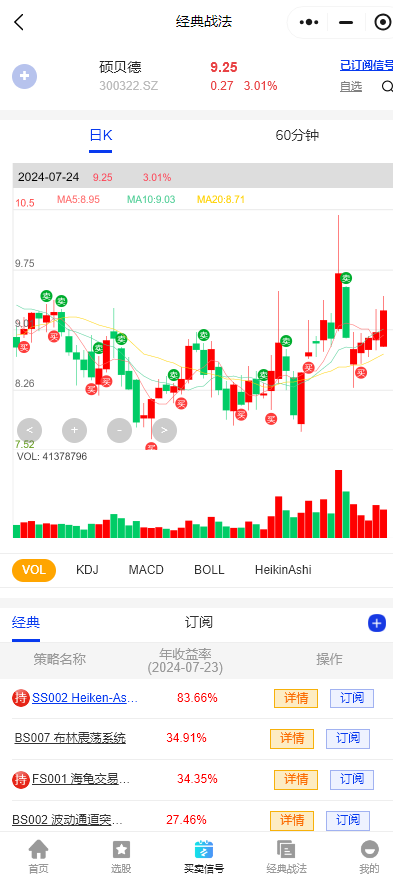
$硕贝德(SZ300322)$:公司液冷散热产品可应用于服务器、路由器、交换机以及光伏储能新能源汽车等领域。公司的散热产品及模组可以应用于数据中心,AI服务器等相关领域。战法一半在参与,低位参与的继续看。
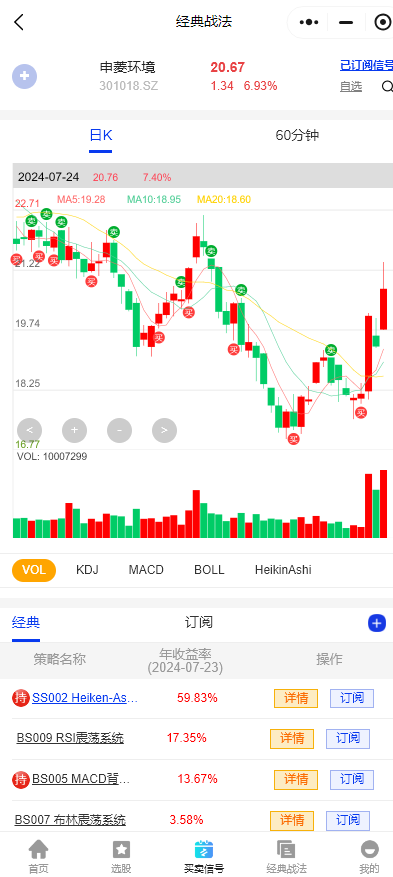
$申菱环境(SZ301018)$:公司致力于紧跟客户步伐,通过高能效,可靠的新一代温控产品如DPC相变冷却系统,新型高效蒸发冷却系统,液冷温控系统等产品和解决方案服务客户。战法一半在参与,低位参与的继续看。
注:以上仅为谱数的经典战法数据统计结果,供大家参考,股市有风险投资需谨慎。
本文作者可以追加内容哦 !

